Azure – Azure Functions support for Node 10 is ending on 30 September 2022
Functions App support for Node 10 apps is ending on 30 September 2022, we recommend you upgrade to Node 14.
Read More for the details.

Functions App support for Node 10 apps is ending on 30 September 2022, we recommend you upgrade to Node 14.
Read More for the details.
Today, we are excited to announce the release of version 1.10 of AWS Copilot with support for publish/subscribe architectures that customers can use to decouple microservices and consume events asynchronously. Customers can now use AWS Copilot to build event-driven architectures or to decouple services in order to increase performance, reliability, and scalability.
Read More for the details.
Amazon Managed Workflows for Apache Airflow (MWAA) is now available in six new AWS Regions: South America (Sao Paulo), Asia Pacific (Seoul), Asia Pacific (Mumbai), Canada (Central), EU (London), and EU (Paris).
Read More for the details.
Visual Studio Code for the Web is a web-based code editor that runs within the browser and allows opening repositories on GitHub (and soon Azure Repos) and making lightweight code changes.
Read More for the details.
A new and more reliable way to protect VMware machines using simplified ASR replication appliance
Read More for the details.
New enhancements and updates released for general availability (GA) in Azure Security Center in August 2021.
Read More for the details.
Public preview enhancements and updates released for Azure Security Center in August 2021.
Read More for the details.
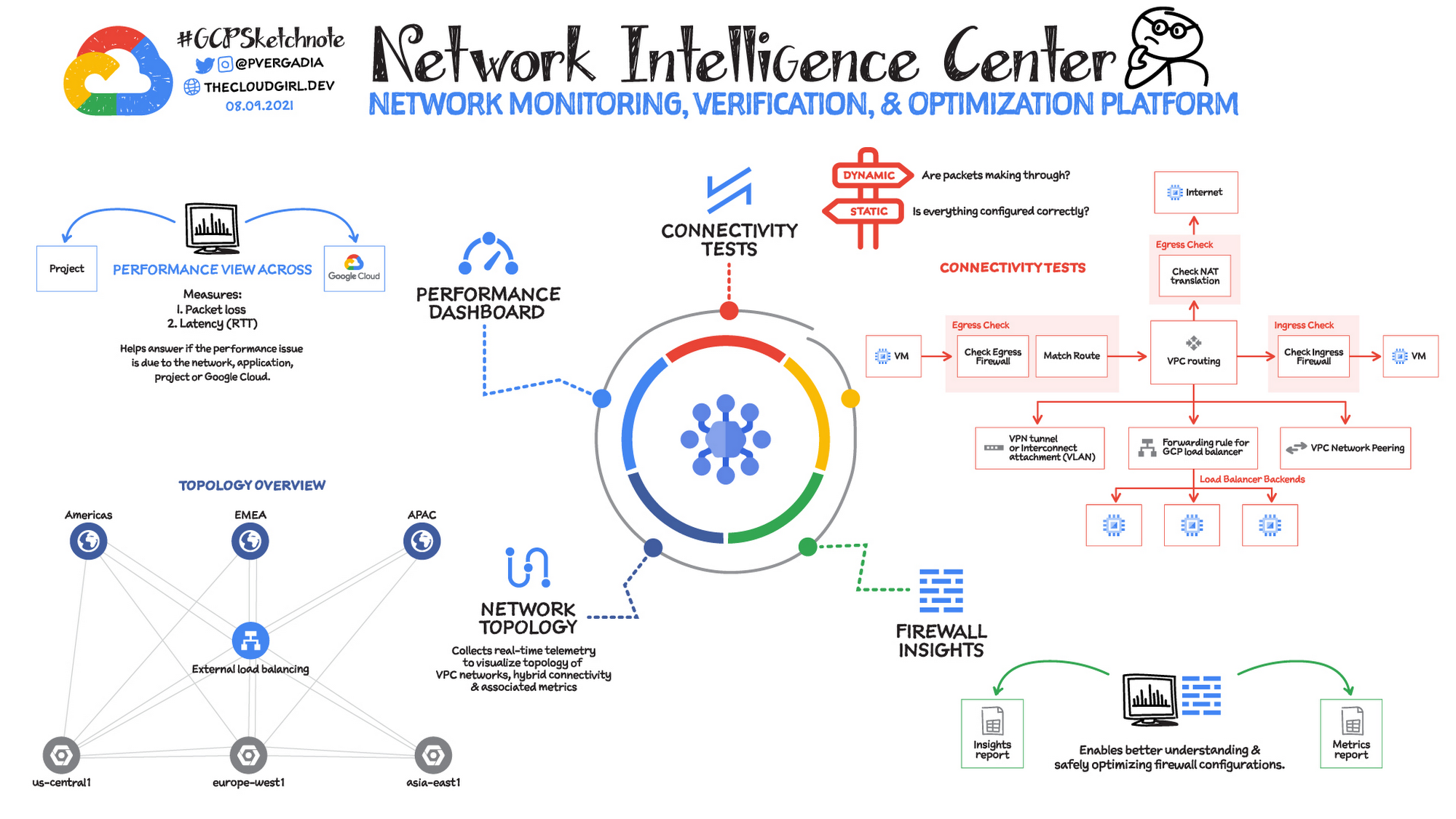
You need visibility into your cloud platform in order to monitor and troubleshoot it. Network Intelligence Center provides a single console for Google Cloud network observability, monitoring, and troubleshooting. Currently Network Intelligence Center has four modules:
Network Topology: Helps you visualize the network topology including VPC connectivity to on-premises, internet, and their associated metrics.
Connectivity Tests: Provides both static and dynamic network connectivity tests for configuration and data-plane reachability, to verify that packets are actually getting through.
Performance Dashboard: Shows packet loss and latency between zones and regions that you are using.
Firewall Insights: Shows usage for your VPC firewall rules and enables you to optimize their configuration
Network Topology collects real-time telemetry and configuration data from Google infrastructure and uses it to help you visualize your resources. It captures elements such as configuration information, metrics, and logs to infer relationships between resources in a project or across multiple projects. After collecting each element, Network Topology combines them to generate a graph that represents your deployment. This enables you to quickly view the topology and analyze the performance of your deployment without configuring any agents, sorting through multiple logs, or using third-party tools.
The Connectivity Tests diagnostics tool lets you check connectivity between endpoints in your network. It analyzes your configuration and in some cases performs run-time verification.
To analyze network configurations, Connectivity Tests simulates the expected inbound and outbound forwarding path of a packet to and from your Virtual Private Cloud (VPC) network, Cloud VPN tunnels, or VLAN attachments.
For some connectivity scenarios, Connectivity Tests also performs run-time verification where it sends packets over the data plane to validate connectivity and provides baseline diagnostics of latency and packet loss.
Performance Dashboard gives you visibility into the network performance of the entire Google Cloud network, as well as the performance of your project’s resources. It collects and shows packet loss and latency metrics. With these performance-monitoring capabilities, you can distinguish between a problem in your application and a problem in the underlying Google Cloud network. You can also debug historical network performance problems.
Firewall Insights enables you to better understand and safely optimize your firewall configurations. It provides reports that contain information about firewall usage and the impact of various firewall rules on your VPC network.
For a more in-depth look into Network Intelligence Center check out the documentation.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev
Read More for the details.
You can now configure routes in your subnet route tables to forward traffic between two subnets in a VPC, via virtual appliances such as network firewalls, intrusion detection and protection systems, etc.
Read More for the details.
Enterprises need to move faster than ever to gain a competitive advantage in today’s customer-focused environment. Time-to-market for products and services has shortened dramatically, from years to days. IT teams must move fast, react fast, and enable business strategies via constant innovation.
All of this digital transformation is about more than adopting the latest technologies. It is also about maximizing the use of existing data and services to improve efficiency and productivity, drive engagement and growth, and ultimately make the lives of customers, partners, and staff better. Connecting existing data and services and making them easily accessible via APIs promises a path forward, empowering enterprises to extend the value they already possess with new technologies, managed services, ecosystems, and support.
In addition to the challenges of legacy data and systems, today’s organizations are overwhelmed by the variety of cloud applications to meet their business needs and deliver innovative services to their customers.
Managing all of this data, connecting sources, integrating applications, and surfacing them as easy-to-use APIs for development is a crucial competency for any IT organization.
Many IT organizations have focused on solving this challenge with an “inside-out” approach: starting with the integration layer, building the flow, and then developing the APIs. But this approach is inefficient and fundamentally flawed because it looks at the problem from an “exposure” model; rather than designing for the business use cases of developers and other API consumers. Leaders in the organization end up seeing all of this data, connectivity, and integration as the “table stakes plumbing”, and thus do not seek inputs regarding business value from key business stakeholders.
The key issue is not exposure but rather how you leverage your data, services, and systems to drive impact across your digital value chain. Goals such as meeting your adoption or sales targets, reducing costs across lines of business, speeding up time to market, and reducing time spent supporting your customers may all be within reach. Easy-to-use APIs, rather than crudely exposed systems, are foundational enablers of this impact, and they are almost always designed from the outside-in, from the perspective of teams that are consuming the APIs to achieve a business goal.
To accelerate the speed of development, enterprise IT teams need to take an API-first approach to integration, starting with the consumers’ use cases rather than the structure of the data in their systems.
The notion of outside-in thinking should be familiar to product managers, who routinely have to demonstrate customer empathy and put themselves in their customers’ shoes. If your team has a product owner, be sure they are empowered to decide what functionality is needed from their data.
An API-first strategy treats the API not as middleware but as a software product that empowers developers, enables partnerships, and accelerates innovation—a big shift from integration-first operations in which APIs are typically exposed and then forgotten.
Possessing APIs is only part of the equation. If a company is going to share valuable digital assets with outsiders, it needs API management tools to:
apply security protections, such as authentication and authorization
protect assets from malicious attacks
monitor digital services to ensure availability and high performance
measure and track usage of the assets
With the right tools in place, APIs can unlock incredible business opportunities—which is a reason for every enterprise to aspire to be API-first!
Visit our website to learn more about API management with Google Cloud.
Read More for the details.
We are excited to announce that Cloud SQL for PostgreSQL now supportsLinux Huge Pages by default. If your instance has more than 2 GB of RAM then your PostgreSQL instance will use Linux Huge Pages for shared memory. This means the shared memory in your Cloud SQL for PostgreSQL instance will now use 2MB pages as opposed to the default 4KB pages. This has many benefits for your PostgreSQL workload. These include:
Improved memory usage by reducing each PostgreSQL process’ page table size which in turn means more memory is available for database operations.
Improved performance because more of the database’s working set can fit into the Translation Lookaside Buffers (TLB)
You can turn off Huge Pages by toggling the huge_pages flag.
For monitoring your PostgreSQL instance’s memory consumption, you can continue to use the database/memory/total_usage metric. This is the most accurate metric to use since it also incorporates the Linux OS page cache footprint. You may see some changes in the behavior of the database/memory/usage metric when Huge Pages are preallocated. This is expected and our recommendation is to use the database/memory/total_usage metric for tracking your instance’s overall memory consumption. Here’s a screenshot on how you can get a hold of the Total Usage metric from the Cloud SQL UI.
Learn more about Cloud SQL for PostgreSQL here.
Read More for the details.
Traffic Director is Google Cloud’s fully managed traffic control plane for service mesh and helps you manage traffic flows between gRPC-based services. For example, you can split traffic between multiple versions of your services for canary or blue/green deployments. You can manage this centrally (for example, by issuing API calls to Traffic Director) without having to re-deploy your applications.
With the most recent release of gRPC, we are bringing new traffic management capabilities to proxyless gRPC services that use Traffic Director: retries and session affinity.
Retries help you improve your service availability by enabling your gRPC applications to retry outbound requests according to a policy. This can be helpful if instances or endpoints (that host your server application(s)) are slow or flaky.
When your client gRPC application sends a request, the request gets resolved to a particular backend service based on request characteristics (for example, the hostname). You can use Traffic Director to set a retry policy for that backend service. The client will check the policy before sending a request to that backend service. The policy defines how your proxyless gRPC client application(s) can retry requests:
according to retry conditions (for example, when encountering response codes such as `unavailable`, `resource-exhausted`, and/or others)
x number of times where x is configurable (for example, retry up to 3 times)
Session affinity is critical to enabling particular use cases and can also help you improve application performance and efficiency. It works by attempting to send requests to the same backend service instance or endpoint based on the request characteristics (HTTP headers).
For example, session affinity allows you to route requests from a particular user to the same shopping cart instance during a session so that the cart can return the items that are in the user’s cart. Additionally, because the instance can store those items in memory, it doesn’t need to repeatedly read and write entries from a database (which can introduce latency).
You can use Traffic Director to enable header-based session affinity for a backend service. When your gRPC application sends a request, it will attempt to route all RPCs with a given request header to the same endpoint. The application just needs to use the same header on all RPCs in a given session.
If you’ve been thinking about adopting a service mesh, improving performance, or increasing the reliability of your system, proxyless gRPC and Traffic Director can help you do that. Once you have proxyless gRPC applications set up with Traffic Director, you can enable the above features on all your applications via API calls, as opposed to having to code each application independently.
For more information about using gRPC with Traffic Director and these new features, see the following links:
Read More for the details.
At Blibli, an Indonesian business-to-consumer Ecommerce provider, we run most of our IT infrastructure— including both stateful and stateless applications such as Redis, RabbitMQ, Spring Boot, Jenkins, and Grafana—on Google Kubernetes Engine (GKE).
GKE provides a scalable and reliable managed service of Kubernetes. It integrates well with other Google Cloud services. And on GKE, we’re now saving more than 30% of infrastructure costs. But like many companies with a lot on their plate and multiple tasks underway, we were once too busy to focus on operations like cluster and node pool updates. Consequently, we fell way behind the current version in GKE.
To comply with both service-provider and open-source software policies, you must stay on top of version updates. And since Google Cloud releases its Kubernetes clusters in three-month cycles, this can be a challenge when running workloads in GKE. But recently, we updated our GKE cluster from version 1.13.x to 1.15.x and tested the same update across different clusters and environments—without service interruptions.
You can read the release notes and changelogs of the version you plan to upgrade to, so I won’t belabor every detail of our update process. But read on to learn how we keep our GKE clusters up to date with newly released versions and how you can too.
We manage our GKE cluster and everything related to it using Terraform and GitOps, which help to simplify the update process.
With a regional cluster, you can avoid downtime because GKE maintains replicas of the control plane across all the zones. So your cluster is resilient to single-zone failure. Double check the resource availability for this activity.
Updating a cluster is a two-step process: First, control plane then node pools, which require a handful of critical network considerations.
The control plane in Kubernetes includes the Kubernetes API server, the scheduler, and the controller manager server. The control-plane upgrade is quite simple since GKE manages it for you with a simple click (in our case, changing the variable in Terraform). This update takes several minutes during which you won’t be able to change the cluster’s configuration. But your workloads will function perfectly.
By default, a cluster’s nodes have auto-update enabled, and Google Cloud recommends that you keep it that way. If you’ve opted for auto-update then GKE does the magic for you. You can just sit back and relax.
Unlike your control-plane update, the process has a lot of visibility. It is also highly dependent on the total number of nodes in the cluster. Sequentially, for each node in the node pool, nodes are stopped from scheduling node Pods, existing Pods are drained, and finally, the node is updated.
Like us, if you need to carefully manage dependencies and qualifications, you may elect to manage your own upgrade workflow. Surge upgrades let you control the number of nodes GKE can update at a time and control how disruptive updates are to your workloads. There are also several options when you decide to update the worker nodes. One obvious way is to manually trigger the update, which parallels the auto-update process except you decide when it occurs.
gcloud container clusters upgrade cluster-name –node-pool=node-pool-name –cluster-version cluster-version
Fun fact: You can manually update a node pool version to match the version of the control plane or a previous version that is still available and compatible with the control plane. The Kubernetes version and version skew support policy guarantees that control planes are compatible with nodes up to two minor versions older than the control plane. For example, Kubernetes 1.13.x control planes are compatible with Kubernetes 1.11.x nodes.
Although GKE can update large clusters quickly, we thought that when running over 100 nodes and not using surge upgrades in GKE, it might take forever to drain all the nodes and upgrade. So our strategy here was to depend on the continuous deployment of our application and also to avoid downtime.
Here comes the interesting implementation part you were looking for. Rather than updating the current nodes of a node pool, we created a new node pool with the updated version—but with a twist. The new node pool had different taints relative to the node pool with the old version. Can you guess the next step? It’s simple: We deployed our applications matching the taints of the node pool with the new version. Again, you can too.
But (there’s always a “but”) to prevent downtime, you need to ensure that your update strategy is a rolling one. And you must confirm a couple other things before deploying the applications.
Since the node pool you just created has a different taint, the first thing you need to ensure once the nodes in the new node pool are spawned is that the DaemonSets are deployed and running perfectly.
PDB is a mechanism by which you allow for a number/percentage of pods to be terminated. Since the number of replica and PDB go hand in hand, we set the PDB for our workloads to maxUnavailable: 1. This gives the confidence that at any point in the application deployment at least one Pod is running.
I know stateful sets are challenging, but GKE offers a variety of ways to manage them. To prevent down time, we use the following checklist, and you can as well. Additionally, you can take snapshots of the Persistent Volume Claims.
Basically, with this method of updating your node pools, you are doubling the size of your current running cluster during the process. So make sure you have sufficient resources available to meet network requirements, such as primary IPs or NAT IPs in case your nodes talk to the outside world.
The packets in the egress traffic will not be masqueraded and the pod IP will be visible if you:
Are running a version older than 1.14.x, and
Don’t have the ip-masq-agent running, and
Have a destination address range that falls under the CIDRs 10.0.0.0/8, 172.16.0.0/12, or 192.168.0.0/16
One way to address this is to add the ip-masq-agent and list the destination CIDRs for the nonMasqueradeCIDRs configuration.
GKE is a versatile platform that provides great value to manage microservices and run them efficiently. For a fully managed, highly effective but low maintenance Kubernetes solution, consider using GKE. Then you can focus on exploring rather than managing the underlying system.
Read More for the details.
Editor’s note: With Google Cloud’s datasets solution, you can access an ever-expanding resource of the newest datasets to support and empower your analyses and ML models, as well as frequently updated best practices on how to get the most out of any of our datasets. We will be regularly updating this blog with new datasets and announcements, so be sure to bookmark this link and check back often.
Looking for a new way to access Google Cloud Release Notes besides the docs, the XML feed, and Cloud Console? Check out the Google Cloud Release Notes dataset. With up-to-date release notes for all generally available Google Cloud products, this dataset allows you to use BigQuery to programmatically analyze release notes across all products, exploring security bulletin updates, fixes, changes, and the latest feature releases.
The Google Trends dataset represents the first time we’re adding Google-owned Search data into Datasets for Google Cloud. The Trends data allows users to measure interest in a particular topic or search term across Google Search, from around the United States, down to the city-level. You can learn more about the dataset here, and check out the Looker dashboard here! These tables are super valuable in their own right, but when you blend them with other actionable data you can unlock whole new areas of opportunity for your team. To learn how to make informed decisions with Google Trends data, keep reading.
With COVID-19 vaccinations being a topic of interest around the United States, this dataset shows aggregated, anonymized trends in searches related to COVID-19 vaccination and is intended to help public health officials design, target, and evaluate public education campaigns. Check out this interactive dashboard to explore searches for COVID-19 vaccination topics by region.
Since 2014, Google has disclosed data on the diversity of its workforce in an effort to bring candid transparency to the challenges technology companies like Google face in recruitment and retention of underrepresented communities. In an effort to make this data more accessible and useful, we’ve loaded it into BigQuery for the first time ever. To view Google’s Diversity Annual Report and learn more, check it out.
The most popular and surging Google Search terms are now available in BigQuery as a public dataset. View the Top 25 and Top 25 rising queries from Google Trends from the past 30-days, including 5 years of historical data across the 210 Designated Market Areas (DMAs) in the US. Keep reading.
With metrics quantifying travel times to COVID-19 vaccination sites, this dataset is intended to help Public Health officials, researchers, and Healthcare Providers to identify areas with insufficient access, deploy interventions, and research these issues. Check out how this data is being used in a number of new tools.
Geospatial data is a critical component for a comprehensive analytics strategy. Whether you are trying to visualize data using geospatial parameters or do deeper analysis or modeling on customer distribution or proximity, most organizations have some type of geospatial data they would like to use – whether it be customer zipcodes, store locations, or shipping addresses. However, converting geographic data into the correct format for analysis and aggregation at different levels can be difficult. In this post, we’ll walk through some examples of how you can leverage the Google Cloud platform alongside Google Cloud Public Datasets to perform robust analytics on geographic data. Keep reading.
When you’ve learned about many of our datasets and pre-built solutions from across Google, you may be ready to start querying them. Check out the full dataset directory and read all the metadata at g.co/cloud/marketplace-datasets, then dig into the data with our free-to-use BigQuery sandbox account, or $300 in credits with our Google Cloud free trial.
Read More for the details.
In September 2001, the first-ever German Google employee switched on their computer in Hamburg. Since then, we’ve grown to more than 2,500 employees in four offices across Germany. Berlin, Frankfurt, Hamburg and Munich have long been our home, and we continue to invest in the growth of the local economy.
Today, 20 years after the start of “Google Germany”, we are pleased to present one of our most important investment programs to date in this country. With the expansion of our Cloud Region in Frankfurt in a new Google-owned Hanau facility, a new Google Cloud region in Berlin-Brandenburg, and a broad investment plan in renewable energy, our commitment is clear: Google is investing in Germany’s potential and supporting the transition to a digital and sustainable economy. Between now (2021) and 2030, this investment in digital infrastructure and clean energy will total approximately 1 billion euros.
In Hanau, only 20 kilometers from the DE-CIX Internet hub in Frankfurt, Google is proud to be nearing completion of an additional cloud facility that will be fully operational in 2022. This expansion of our existing Frankfurt Google Cloud region will serve the growing demand for Google Cloud services in Germany.
The 4-story building is 10,000 square meters and was sustainably constructed with energy efficient infrastructure and adherence to our circular economy model for waste. The symbolic handover of the keys from developer NDC-Garbe, together with local government officials, took place on site yesterday.
In addition to the Hanau expansion of our Google Cloud region in Frankfurt, we are pleased to announce that a new Google Cloud region will be located in Berlin-Brandenburg, further extending our ability to meet growing demand for cloud services in the country. When open, this will be our second Google Cloud region in Germany, providing enterprise customers with faster access to secure infrastructure, smart analytics tools and an open platform. Designed and dedicated to providing enterprise services and products for Google Cloud customers of all sizes and industries in Germany, the Berlin-Brandenburg region will have three zones to protect against service disruptions and join the existing network of 27 Google Cloud regions connected via our high-performance network.
Since 2017, Google has matched 100% of our global, annual electricity use with renewable energy. Last year, we set out to run our business on carbon-free energy everywhere and at all times by 2030, enabling us to offer cloud customers one of the cleanest clouds in the industry, while helping Europe achieve its ambitious climate goals.
Today, we’re excited to announce that ENGIE Deutschland has been selected as Google’s carbon-free energy supplier in Germany. Under the terms of the agreement, ENGIE will assemble and develop, on Google’s behalf, a 140 megawatt (MW) carbon-free energy portfolio in Germany that has the ability to flex and grow with us as our needs change. This includes a new 39MW solar Photovoltaic system, and 22 wind parks in five federal states that will see their lives extended so they continue to produce electricity instead of being dismantled. This portfolio will ensure that the energy delivered to Google’s German facilities will be nearly 80% carbon-free by 2022 whenmeasured on an hourly basis. This is a first but important step on Google’s journey to reach our goal of full electricity decarbonization by 2030.
This is the first energy supply of its kind in Europe, with a focus on sourcing carbon-free energy for every hour of Google’s operations. Not only will this new agreement draw the roadmap for the industry and more 24/7 carbon-free energy contracts in Europe, but it provides our cloud customers with two more regions where they can lower their carbon footprint. And importantly, by working with our energy suppliers to transform how clean energy is delivered to customers, Google is supporting the broader decarbonization of the German electricity grid.
As companies continue to grapple with changing customer demands, technology has played a critical role, and we’ve been fortunate to partner with and serve people, companies, and government institutions in Germany and around the world to help them adapt. The Google Cloud region in Berlin-Brandenburg and the expansion of our Google Cloud region in Hanau will help our customers — such as BMG, Delivery Hero, and Deutsche Bank — adapt to new requirements, new opportunities and new ways of working.
“We are very pleased about the symbolic handover of the keys to the building here in Hanau to Google Cloud,” said Hanau Mayor Claus Kaminsky. “With Google, we have a strong partner at our side who is supporting us in setting up Hanau’s economic future, both digitally and sustainably. The data center facility of Google Cloud embodies this transformation: We bring the cloud to us in Hanau and thus support the digital transformation of companies and public authorities. Not only in our city and Hesse, but throughout Germany and Europe. The new building meets high sustainability standards and the clean energy initiative presented today by Google is in line with our aspirations for sustainable digitalization.”
“Sustainability is a central pillar of Deutsche Bank’s strategy and we have made strong public commitments to be part of the solution,” said Bernd Leukert, Chief Technology, Data and Innovation Officer and Member of the Management Board at Deutsche Bank. “We welcome the new Google Cloud region in Germany, which will enable us to deliver additional resilience and performance for our German client base.”
Ralf Bernhard, Senior Originator Renewables, ENGIE, said: “ENGIE is excited to collaborate with Google based on a first-of-a-kind agreement which will support the company with its sustainability goals and ambitious carbon-free energy target. Thanks to our expertise in energy and risk management, we can seamlessly integrate renewable energy from existing plants and develop new assets to design a tailor made product that meets Google’s needs and plans to go even greener.”
20 years since Google first touched down in Germany, our commitment to helping Germany continue to lead in technical innovation is stronger than ever. We are excited to continue working with our partners in Hesse, Berlin and Brandenburg and across Germany to advance infrastructure and clean energy projects, help accelerate digital transformation, and secure a sustainable future for German and European companies and organizations.
Read More for the details.
A key benefit of cloud computing is that you can easily create and delete computing resources, paying only for what you use. While production virtual machines (VMs) tend to run constantly, some are only needed when running batch jobs, while others like development or test environments are typically used only during business hours. Keeping VMs running when they have no users or tasks to run serves no useful purpose, so turning them off saves money.
However, managing fleets of VMs manually can be tedious, error-prone, and hard to enforce across a large organization. What’s more, systems that are migrated from on-premises hardware don’t usually take advantage of the ability to turn off when they don’t have users or tasks to run. While on-premises hardware either is there or isn’t, VMs in the cloud can be running, suspended, stopped or turned into machine images, ready to recreate at a moment’s notice. Each of these options has different costs and benefits.
Our new guide, Cost optimization through automated VM management, takes you through various ways to control your fleet of Compute Engine VMs, ranging from simple time-based scheduling to leveraging Recommender analytics to resizing underused VMs and shut down idling ones. You can learn about various approaches to running batch jobs efficiently, from self-deleting virtual machines to orchestrating simple or complex tasks with Workflows or Cloud Composer, and reduce the operational overhead of OS maintenance with VM Manager.
The guide also covers the differences between suspending, stopping and deleting instances. With suspend and resume, now available in Preview, you have a cost-effective way to “pause” an instance while retaining its memory and application state, the same way a laptop remembers what you were working on when you close the lid. When the instance is resumed, your users can continue their work from right where they left off, without having to wait for the instance to boot or their software to load.
Get started by stepping through the decision tree in Cost optimization through automated VM management, and start saving money today.
Read More for the details.
In the last couple of years there has been a shift in the way retailers approach ecommerce: where in the past development efforts were prioritized around building a solid foundation for backend transactions and operations now it is clear that companies in this space are focusing on differentiating themselves by creating unique shopping experiences that increase engagement and reduce friction.
But how can development teams spend the necessary time designing and writing code for this kind of interactions while also having to seamlessly maintain ecommerce vital components like online catalogs, shopping carts and checkout payment processes? Enter headless commerce.
Headless commerce (HC) helps companies of all sizes to innovate, develop and launch in less time and using fewer resources by decoupling backend and frontend. Headless solution providers empower online retailers by offering a balance between flexibility and optimization through pre-built api-accessible modules and components that can be easily plugged into their frontend architecture. This translates into rapid development while keeping desired levels of security, compliance, integration and responsiveness.
This composable approach enables dev teams not only to create new features but also connect other ecommerce components with less effort which is critical when responding to business trends. But above all, the main benefit retailers receive from HC, is owning and controlling the frontend for an engaging customer journey as well as quickly launching new experiences.
commercetools, a leader in the headless commerce space, has partnered with Google Cloud to make their cloud-native SaaS platform available in the Google Cloud Marketplace. With a flexible API system (REST API and GraphQL), commercetools’ architecture has been designed to meet the needs of demanding omnichannel ecommerce projects while offering real flexibility to modify or extend its features. It supports a variety of storefront providers like Vue Storefront, offers a large set of integrations and supports microservice-based architectures. All this while providing access to multiple programming languages (PHP, JS, Java) via its SDK tools.
commercetools and Google Cloud provide development teams with all the tools to build high-quality digital commerce systems. Google Cloud’s scalability, AI/ML components, API management capabilities and CI/CD tools are a perfect fit to build frontend shopping experiences that easily integrate with the commercetools stack. Developers can take advantage of this compatibility by:
Integrating systems with Google’s Retail Search, Recommendations AI and Vision Product Search
Injecting serverless functions into commercetools using Google Cloud Functions
Extending and integrating commercetools via Events handled by Pub/Sub
Managing 3rd party, legacy, microservices and commercetools APIs with Apigee
Selecting the Google Cloud region commercetools uses for zero latency for custom apps
Expanding their microservice ecosystem with components like Cloud Storage, Cloud SQL, Firestore and BigQuery
Additionally, commercetools allows ecommerce solutions to tap into the wider Google Ecosystem by providing authoritative data via Merchant Center, advertising via product listing ads and selling via Google Shopping.
As mentioned previously, headless commerce is increasingly preferred by retailers who want to own and control the ‘front-end’ for providing and enabling an engaging and differentiated user and shopping experiences.
The approach involves a loosely coupled architecture that separates ‘front end’ from the ‘back end’ of a digital commerce application. The front end is typically built and managed by the retailer. They want to leverage an independent software vendor (ISV) offered, ready-to-use ‘back-end’ commerce building blocks for capabilities, such as product catalog, pricing, promotions, cart, shipping, account and others.
Most retailers want to invest their time and resources in building a front end that requires an agile development model to introduce new and tweaking existing user experiences to acquire and retain customers. A few retailers that do not have an in-house web development team may choose an ISV that offers ready to use front end. The front end is a web app and designed as a progressive web application (PWA) on Google Cloud. The backend is a headless commerce offered by an ISV, such as commercetools. The backend commerce capabilities are built as a set of microservices, exposed as APIs, run cloud-native and implemented as headless. It is commonly referred to as the “MACH” solution. The API-first approach of the architecture allows easily integrating ‘best of breed’ capabilities built internally and/or offered by 3rd party ISVs.
The architecture of the front end will be implemented on Google Cloud and will integrate with the ISV’s headless commerce back end that runs natively in Google Cloud.
The front end will be designed using cloud-native services for
PWA web app development (Google Kubernetes Engine, CI/CD services),
Google Product Discovery solution that includes Retail Search and Vision API Product Search for serving product search (text and image) and Recommendations AI for serving recommendations.
Storage (Cloud Storage), Database (Cloud SQL, Cloud Firestore), and edge caching for content delivery (Cloud CDN)
Networking (Cloud DNS, Global Load Balancing), and
Security (Cloud Armor for DDoS, API Defense for API protection)
Additionally, API management (Apigee on Google Cloud) can be used to orchestrate interactions of the front end with the APIs of the backend commerce services. The API management’s capability will be used for accessing the services of on-premises systems, such as ERP, order management system (OMS), warehouse management system (WMS) as needed to support the functioning of digital commerce application. Alternatively, depending on the frontend capabilities, developers can use middleware to build custom services and route requests.
A considerable number of retailers have adopted headless commerce and are now focusing on adopting best practices and leveraging the agility that comes with this approach. Just like commercetools offers robust components that meet the retailer’s backend operational needs (Product Catalog, Order Management, Carts, Payments, etc), Google Cloud’s Compute, Networking, Severless and AI/ML services provide the agility and flexibility required by development teams to quickly and easily extend their frontend capabilities.
commercetools and Google Cloud work seamlessly together because they both prioritize ease of integration, scalability, security and iterability while providing ready-to-use building blocks. It also helps that commercetools backend runs on Google Cloud. Once an initial foundation of Google Cloud and commercetools has been established, adding new commerce modules and extending functionally of the current ones becomes a straightforward process that allows to route efforts to innovation initiatives. In the end, the main beneficiaries of this technical synergy are the shoppers that enjoy experiences which increase engagement and minimize friction.
Alternatively, retailers can also save time and resources by relying on frontend integrations. commercetools offers a variety of third-party solutions that can effortlessly be added to a headless commerce architecture. These integrations as well as other important headless commerce extensions will be explored in future blog entries. In the meantime, all the necessary tools to leverage headless commerce can be found in just one place:
Get started with commercetools on the Google Cloud Marketplace today!
Read More for the details.
AWS Backint Agent now supports three new features: Amazon S3 Intelligent Tiering, the ability to send log and data backups to separate folders, and compatibility with Ansible.
Read More for the details.
ExpressRoute Direct gives you the ability to connect directly into Microsoft’s global network at peering locations strategically distributed around the world.
Read More for the details.
AWS CloudFormation users can now choose to preserve the state of successfully deployed resources in the event of CloudFormation stack operation errors. Using this feature, you can retry the operation using an updated CloudFormation template and quickly iterate through feedback loops, shortening development cycles.
Read More for the details.
{kind=link}
{kind=link}
{kind=link}