AWS Private Certificate Authority (AWS Private CA) now supports Online Certificate Status Protocol (OCSP) in China and AWS GovCloud (US) Regions. AWS Private CA is a fully managed certificate authority service that makes it easy to create and manage private certificates for your organization without the operational overhead of running your own CA infrastructure. OCSP enables real-time certificate validation, allowing applications to check the revocation status of individual certificates on-demand rather than downloading Certificate Revocation List (CRL) files.
With OCSP support, customers in these Regions can implement more efficient certificate validation with minimal bandwidth, typically requiring a few hundred bytes per query, versus downloading large Certificate Revocation Lists (CRLs) that can be hundreds of kilobytes or larger. This enables real-time revocation checks for use cases such as validating internal microservices communications, implementing zero trust security architectures, and authenticating IoT devices. AWS Private CA fully manages the OCSP responder infrastructure, providing high availability without requiring you to deploy or maintain OCSP servers.
OCSP is now also available in the following AWS Regions: China (Beijing), and China (Ningxia), AWS GovCloud (US-East), AWS GovCloud (US-West).
To enable OCSP for your certificate authorities, use the AWS Private CA console, AWS CLI, or API. To learn more about OCSP, see Certificate Revocation in the AWS Private CA User Guide. For pricing information, visit the AWS Private CA pricing page.
Amazon Application Recovery Controller (ARC) Region switch allows you to orchestrate the specific steps to switch your multi-Region applications to operate out of another AWS Region and achieve a bounded recovery time in the event of a Regional impairment to your applications. Region switch saves hours of engineering effort and eliminates the operational overhead previously required to complete failover steps, create custom dashboards, and manually gather evidence of a successful recovery for applications across your organization and hosted in multiple AWS accounts. Today, we are announcing three new Region switch capabilities:
AWS GovCloud (US) support: ARC Region switch is now generally available in AWS GovCloud (US-East and US-West) Regions.
Plan execution reports: Region switch now automatically generates a comprehensive report from each plan execution and saves it to an Amazon S3 bucket of your choice. Each report includes a detailed timeline of events for the recovery operation, resources in scope for the Region switch, alarm states for optional application status alarms, and recovery time objective (RTO) calculations. This eliminates the manual effort previously required to compile evidence and documentation for compliance officers and auditors.
DocumentDB global cluster execution blocks: Adding to the catalog of 9 execution blocks, Region switch now supports Amazon DocumentDB global cluster execution blocks for automated multi-Region database recovery. This feature allows you to orchestrate DocumentDB global cluster failover and switchover operations within your Region switch plans.
To get started, build a Region switch plan using the ARC console, API, or CLI. See the AWS Regional Services List for availability information. Visit our home page or read the documentation.
Today, AWS announces SOCI (Seekable Open Container Initiative) indexing support for Amazon SageMaker Studio, reducing container startup times by 30-50% when using custom images. Amazon SageMaker Studio is a fully integrated, browser-based environment for end-to-end machine learning development. SageMaker Studio provides pre-built container images for popular ML frameworks like TensorFlow, PyTorch, and Scikit-learn that enable quick environment setup. However, when data scientists need to tailor environments for specific use cases with additional libraries, dependencies, or configurations, they can build and register custom container images with pre-configured components to ensure consistency across projects. As ML workloads become increasingly complex, these custom container images have grown in size, leading to startup times of several minutes that create a bottlenecks in iterative ML development where quick experimentation and rapid prototyping are essential.
SOCI indexing addresses this challenge by enabling lazy loading of container images, downloading only the necessary components to start applications with additional files loaded on-demand as needed. Instead of waiting several minutes for complete custom image downloads, users can begin productive work in seconds while the environment completes initialization in the background. To use SOCI indexing, create a SOCI index for your custom container image using tools like Finch CLI, nerdctl, or Docker with SOCI CLI, push the indexed image to Amazon Elastic Container Registry (ECR), and reference the image index URI when creating SageMaker Image resources.
SOCI indexing is available in all AWS Regions where Amazon SageMaker Studio is available. To learn more about implementing SOCI indexing for your SageMaker Studio custom images, see Bring your own SageMaker image in the Amazon SageMaker Developer Guide.
Amazon Relational Database Service (RDS) now offers enhanced observability for your snapshot exports to Amazon S3, providing detailed insights into export progress, failures, and performance for each task. These notifications enable you to monitor your exports with greater granularity and enables more predictability.
With snapshot export to S3, you can export data from your RDS database snapshots to Apache Parquet format in your Amazon S3 bucket. This launch introduces four new event types, including current export progress and table-level notifications for long-running tables, providing more granular visibility into your snapshot export performance and recommendations for troubleshooting export operation issues. Additionally, you can view export progress, such as the number of tables exported and pending, along with exported data sizes, enabling you to better plan your operations and workflows. You can subscribe to these events through Amazon Simple Notification Service (SNS) to receive notifications and view the export events through the AWS Management Console, AWS CLI, or SDK.
This feature is available for RDS PostgreSQL, RDS MySQL, and RDS MariaDB engines in all Commercial Regions where RDS is generally available.
In the latest episode ofthe Agent Factory, Mofi Rahmanand I had the pleasure of hosting, Brandon Royal, the PM working on agentic workloads on GKE. We dove deep into the critical questions around the nuances of choosing the right agent runtime, the power of GKE for agents, and the essential security measures needed for intelligent agents to run code.
This post guides you through the key ideas from our conversation. Use it to quickly recap topics or dive deeper into specific segments with links and timestamps.
We kicked off our discussion by tackling a fundamental question: why choose GKE as your agent runtime when serverless options like Cloud Run or fully managed solutions like Agent Engine exist?
Brandon explained that the decision often boils down to control versus convenience. While serverless options are perfectly adequate for basic agents, the flexibility and governance capabilities of Kubernetes and GKE become indispensable in high-scale scenarios involving hundreds or thousands of agents. GKE truly shines when you need granular control over your agent deployments.
We’ve discussed the Agent Development Kit (ADK) in previous episodes, and Mofi highlighted to us how seamlessly it integrates with GKE and even showed a demo with the agent he built. ADK provides the framework for building the agent’s logic, traces, and tools, while GKE provides the robust hosting environment. You can containerize your ADK agent, push it to Google Artifact Registry, and deploy it to GKE in minutes, transforming a local prototype into a globally accessible service.
As agents become more sophisticated and capable of writing and executing code, a critical security concern emerges: the risk of untrusted, LLM-generated code. Brandon emphasized that while code execution is vital for high-performance agents and deterministic behavior, it also introduces significant risks in multi-tenant systems. This led us to the concept of a “sandbox.”
For those less familiar with security engineering, Brandon clarified that a sandbox provides kernel and network isolation. Mofi further elaborated, explaining that agents often need to execute scripts (e.g., Python for data analysis). Without a sandbox, a hallucinating or prompt-injected model could potentially delete databases or steal secrets if allowed to run code directly on the main server. A sandbox creates a safe, isolated environment where such code can run without harming other systems.
So, how do we build this “high fence” on Kubernetes? Brandon introduced the Agent Sandbox on Kubernetes, which leverages technologies like gVisor, an application kernel sandbox. When an agent needs to execute code, GKE dynamically provisions a completely isolated pod. This pod operates with its own kernel, network, and file system, effectively trapping any malicious code within the gVisor bubble.
Mofi walked us through a compelling demo of the Agent Sandbox in action.We observed an ADK agent being given a task requiring code execution. As the agent initiated code execution, GKE dynamically provisioned a new pod, visibly labeled as “sandbox-executor,” demonstrating the real-time isolation. Brandon highlighted that this pod is configured with strict network policies, further enhancing security.
While the Agent Sandbox offers incredible security, the latency of spinning up a new pod for every task is a concern. Mofi demoed the game-changing solution: Pod Snapshots. This technology allows us to save their state of running sandboxes and then near-instantly restore them when an agent needs them. Brandon noted that this reduces startup times from minutes to seconds, revolutionizing real-time agentic workflows on GKE.
Conclusion
It’s incredible to see how GKE isn’t just hosting agents; it’s actively protecting them and making them faster.
Your turn to build
Ready to put these concepts into practice? Dive into the full episode to see the demos in action and explore how GKE can supercharge your agentic workloads.
Amazon WorkSpaces Applications now offers images powered by Microsoft Windows Server 2025, enabling customers to launch streaming instances with the latest features and enhancements from Microsoft’s newest server operating system. This update ensures your application streaming environment benefits from improved security, performance, and modern capabilities.
With Windows Server 2025 support, you can deliver the Microsoft Windows 11 desktop experience to your end users, giving you greater flexibility in choosing the right operating system for your specific application and desktop streaming needs. Whether you’re running business-critical applications or providing remote access to specialized software, you now have expanded options to align your infrastructure decisions with your unique workload requirements and organizational standards. You can select from AWS-provided public images or create custom images tailored to your requirements using Image Builder.
Support for Microsoft Windows Server 2025 is now generally available in all AWS Regions where Amazon WorkSpaces Applications is offered.
Amazon Bedrock Data Automation (BDA) now supports blueprint instruction optimization, enabling you to improve the accuracy of your custom field extraction using just a few example document assets with ground truth labels. BDA automates the generation of insights from unstructured multimodal content such as documents, images, audio, and videos for your GenAI-powered applications. Blueprint instruction optimization automatically refines the natural language instructions in your blueprints, helping you achieve production-ready accuracy in minutes without model training or fine-tuning.
With blueprint instruction optimization, you can now bring up to 10 representative document assets from your production workload and provide the correct, expected values for each field. Blueprint instruction optimization analyzes the differences between your expected results and the Data Automation inference results, and then refines the natural language instructions to improve extraction accuracy across your examples. For your intelligent document processing applications, you can now improve the accuracy of extracting insights such as invoice line items, contract terms, tax form fields, or medical billing codes. After optimization completes, you receive detailed evaluation metrics including exact match rates and F1 scores measured against your ground truth, giving you confidence that your blueprint is ready for production deployment.
Data Automation blueprint instruction optimization for documents is available in all AWS Regions where Amazon Bedrock Data Automation is supported.
Amazon Timestream for InfluxDB now offers a restart API for both InfluxDB versions 2 and 3. This new capability enables customers to trigger system restarts on their database instances directly through the AWS Management Console, API, or CLI, to streamline operational management of their time-series database environments.
With the restart API, customers can perform resilience testing to validate their application’s behavior during database restarts and address health-related issues without requiring support intervention. This feature enhances operational flexibility for DevOps teams managing mission-critical workloads, allowing them to implement more comprehensive testing strategies and respond faster to performance concerns by providing direct control over database instance lifecycle operations.
Amazon Timestream for InfluxDB restart capability is available in all Regions where Timestream for InfluxDB is offered.
AWS announces Cost Allocation tags support for account tags across AWS Cost Management products, enabling customers with multiple member accounts to utilize their existing AWS Organizations account tags directly in cost management tools. Account tags are applied at the account level in AWS Organizations and automatically apply to all metered usage within tagged accounts, eliminating the need to manually configure and maintain separate account groupings in AWS Cost Explorer, Cost and Usage Reports, AWS Budgets, and Cost Categories.
With account tag support, customers can analyze costs by account tag directly in Cost Explorer and Cost and Usage Reports (CUR 2.0 and FOCUS). Customers can set up AWS Budgets and AWS Cost Anomaly Detection alerts on groups of accounts without configuring lists of account IDs. Customers can also build complex cost categories on top of account tags for further categorization. Account tags enable cost allocation for untaggable resources including refunds, credits, and certain service charges that cannot be tagged at the resource level. When new accounts join the organization or existing accounts are removed, customers simply add or update relevant tags, and the changes automatically apply across all cost management products. To get started, customers apply tags to accounts in the AWS Organizations console, then activate those account tags from the Cost Allocation Tags page in the Billing and Cost Management console. This feature is generally available in all AWS Regions, excluding GovCloud (US) Regions and China (Beijing) and China (Ningxia) Regions.
Amazon Elastic Container Registry (ECR) now supports automatic repository creation on image push. This new capability simplifies container workflows by having ECR automatically create repositories if they don’t exist when an image is pushed, without customers having to pre-create repositories before pushing container images. Now when customers push images, ECR will automatically create repositories according to defined repository creation template settings.
Create on push is available in all AWS commercial and AWS GovCloud (US) Regions. To learn more about repository creation templates, please visit our documentation. You can learn more about storing, managing and deploying container images and artifacts with Amazon ECR, including how to get started, from our product page and user guide.
Amazon Redshift ODBC 2.x driver now supports Apple macOS, expanding platform compatibility for developers and analysts. This enhancement allows Apple macOS users to connect to Amazon Redshift clusters using the latest Amazon Redshift ODBC 2.x driver version. You can use an ODBC connection to connect to your Amazon Redshift cluster from many third-party SQL client tools and applications.
The Amazon Redshift ODBC 2.x native driver support enables you to access Amazon Redshift features such as data sharing write capabilities and Amazon IAM Identity Center integration – features that are only available through Amazon Redshift drivers. This native Apple macOS support enables seamless integration with Extract, Transform, Load (ETL) and Business Intelligence (BI) tools, allowing you to use Apple macOS while accessing the full suite of Amazon Redshift capabilities.
We recommend that you upgrade to the latest Amazon Redshift ODBC 2.x driver version to access new features. For installation instructions and system requirements, please see the Amazon Redshift ODBC 2.x driver documentation.
AWS IoT now supports event-based logging, a new capability that helps developers reduce Amazon CloudWatch costs while improving log management efficiency. This feature enables targeted logging for individual event with customizable log levels and Amazon CloudWatch log group destinations. With Event-Based Logging, you can set different log levels for different types of IoT events based on their operational importance. For example, you can configure INFO-level logging for certificateProvider events while maintaining ERROR-level logging for less critical activities like connectivity events. The granularity allows you to maintain comprehensive visibility into your IoT operations without the overhead of logging every activity at the same verbosity level, improving log searchability and analysis efficiency while helping to reducing costs. Event-level logging is now available for configuration through the AWS IoT console, CLI, and API in all AWS Regions where AWS IoT is supported. To learn more about configuring Event-Based Logging, visit AWS IoT Developer Guide.
In computing’s early days of the 1940s, mathematicians discovered a flawed assumption about the behavior of round-off errors. Instead of canceling out, fixed-point arithmetic accumulated errors, compromising the accuracy of calculations. A few years later, “random round-off” was proposed, which would round up or down based on a random probability proportional to the remainder.
In today’s age of generative AI, we face a new numerical challenge. To overcome memory bottlenecks, the industry is shifting to lower precision formats like FP8 and emerging 4-bit standards. However, training in low precision is fragile. Standard rounding destroys the tiny gradient updates driving learning, causing model training to stagnate. That same technique from the 1950s, now known as stochastic rounding, is allowing us to train massive models without losing the signal. In this article, you’ll learn how frameworks like JAX and Qwix apply this technique on modern Google Cloud hardware to make low-precision training possible.
When Gradients Vanish
The challenge in low-precision training is vanishing updates. This occurs when small gradient updates are systematically rounded to zero by “round to nearest” or RTN arithmetic. For example, if a large weight is 100.0 and the learning update is 0.001, a low-precision format may register 100.001 as identical to 100.0. The update effectively vanishes, causing learning to stall.
Let’s consider the analogy of a digital swimming pool that only records the water level in whole gallons. If you add a teaspoon of water, the system rounds the new total back down to the nearest gallon. This effectively deletes your addition. Even if you pour in a billion teaspoons one by one, the recorded water level never rises.
Precision through Probability
Stochastic rounding, or SR for short, solves this by replacing deterministic rounding rules with probability. For example, instead of always rounding 1.4 down to 1, SR rounds it to 1 with 60% probability and 2 with 40% probability.
Mathematically, for a value x in the interval [⌊x⌋,⌊x⌋+1], the definition is:
The defining property is that SR is unbiased in expectation:
Stochastic Rounding: E[SR(x)] = x
Round-to-Nearest: E[RTN(x)] ≠ x
To see the difference, look at our 1.4 example again. RTN is deterministic: it outputs 1 every single time. The variance is 0. It is stable, but consistently wrong. SR, however, produces a noisy stream like 1, 1, 2, 1, 2.... The average is correct (1.4), but the individual values fluctuate.
We can quantify the “cost” of zero bias with the variance formula:
Var(SR(x))=p(1-p)wherep=x-⌊x⌋
In contrast, RTN has zero variance, but suffers from fast error accumulation. In a sum of N operations, RTN’s systematic error can grow linearly (O(N)). If you consistently round down by a tiny amount, those errors stack up fast.
SR behaves differently. Because the errors are random and unbiased, they tend to cancel each other out. This “random walk” means the total error grows only as the square root of the number of operations O(√N).
While stochastic rounding introduces noise, the tradeoff can often be benign. In deep learning, this added variance often acts as a form of implicit regularization, similar to dropout or normalization, helping the model escape shallow local minima and generalize better.
Google’s TPU architecture includes native hardware support for stochastic rounding in the Matrix Multiply Unit (MXU). This allows you to train in lower-precision formats like INT4, INT8 and FP8 without meaningful degradation of model performance.
You can use Google’s Qwix library, a quantization toolkit for JAX that supports both training (QAT) and post-training quantization (PTQ). Here is how you might configure it to quantize a model in INT8, explicitly enabling stochastic rounding for the backward pass to prevent vanishing updates:
code_block
<ListValue: [StructValue([(‘code’, “import qwixrnrn# Define quantization rules selecting which layers to compressrnrules = [rn qwix.QtRule(rn module_path=’.*’,rn weight_qtype=’int8′,rn act_qtype=’int8′,rn bwd_qtype=’int8′, # Quantize gradientsrn bwd_stochastic_rounding=’uniform’, # Enable SR for gradientsrn )rn]rnrn# Apply Quantization Aware Training (QAT) rulesrnmodel = qwix.quantize_model(model, qwix.QtProvider(rules))”), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x7fcbc7d66f10>)])]>
Qwix abstracts the complexity of low-level hardware instructions, allowing you to inject quantization logic directly into your model’s graph with a simple configuration.
NVIDIA Blackwell & A4X VMs
The story is similar if you are using NVIDIA GPUs on Google Cloud. You can deploy A4X VMs, the industry’s first cloud instance powered by the NVIDIA GB200 NVL72 system. These VMs connect 72 Blackwell GPUs into a single supercomputing unit, the AI Hypercomputer.
Blackwell introduces native hardware support for NVFP4, a 4-bit floating-point format that utilizes a block scaling strategy. To preserve accuracy, the NVFP4BlockScaling recipe automatically applies stochastic rounding to gradients to avoid bias, along with other advanced scaling techniques.
When you wrap your layers in te.autocast with this recipe, the library engages these modes for the backward pass:
By simply entering this context manager, the A4X’s GB200 GPUs perform matrix multiplications in 4-bit precision while using stochastic rounding for the backward pass, delivering up to 4x higher training performance than previous generations without compromising convergence.
Best Practices for Production
To effectively implement SR in production, first remember that stochastic rounding is designed for training only. Because it is non-deterministic, you should stick to standard Round-to-Nearest for inference workloads where consistent outputs are required.
Second, use SR as a tool for debugging divergence. If your low-precision training is unstable, check your gradient norms. If they are vanishing, enabling SR may help, while exploding gradients suggest problems elsewhere.
Finally, manage reproducibility carefully. Since SR relies on random number generation, bit-wise reproducibility is more challenging. Always set a global random seed, for example, using jax.random.key(0), to ensure that your training runs exhibit “deterministic randomness,” producing the same results each time despite the internal probabilistic operations.
Stochastic rounding transforms the noise of low-precision arithmetic into the signal of learning. Whether you are pushing the boundaries with A4X VMs or Ironwood TPUs, this 1950’s numerical method is the key to unlocking the next generation of AI performance.
Connect on LinkedIn, X, and Bluesky to continue the discussion about the past, present, and future of AI infrastructure.
You’ve built a powerful AI agent. It works on your local machine, it’s intelligent, and it’s ready to meet the world. Now, how do you take this agent from a script on your laptop to a secure, scalable, and reliable application in production? On Google Cloud, there are multiple paths to deployment, each offering a different developer experience.
For teams seeking the simplest path to production, Vertex AI Agent Engine removes the need to manage web servers or containers entirely. It provides an opinionated environment optimized for python agents, where you define the agent’s logic, and the platform handles the execution, memory, and tool invocation.
aside_block
<ListValue: [StructValue([(‘title’, ‘Start the lab!’), (‘body’, <wagtail.rich_text.RichText object at 0x7fcbc59891f0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
The Serverless Experience: Cloud Run
For teams that want the flexibility of containers without the operational overhead, Cloud Run abstracts away the infrastructure, allowing you to deploy your agent as a container that automatically scales up when busy and down to zero when quiet.
This path is particularly powerful if you need to build in languages other than Python, use custom frameworks, or integrate your agent into existing declarative CI/CD pipelines.
aside_block
<ListValue: [StructValue([(‘title’, ‘Start the lab!’), (‘body’, <wagtail.rich_text.RichText object at 0x7fcbc5989400>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
The Orchestrated Experience: Google Kubernetes Engine (GKE)
For teams that need precise configuration over their environment, GKE is designed to manage that complexity. This path shows you how an AI agent functions not just as a script, but as a microservice within a broader orchestrated cluster.
aside_block
<ListValue: [StructValue([(‘title’, ‘Start the lab!’), (‘body’, <wagtail.rich_text.RichText object at 0x7fcbc5989460>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
Your Path to Production
Whether you are looking for serverless speed, orchestrated control, or a fully managed runtime, these labs provide the blueprint to get you there.
These labs are part of the Deploying Agents module in our official Production-Ready AI with Google Cloud program. Explore the full curriculum for more content that will help you bridge the gap from a promising prototype to a production-grade AI application.
Share your progress and connect with others on the journey using the hashtag #ProductionReadyAI. Happy learning!
Amazon EC2 now supports Availability Zone ID (AZ ID) parameter, enabling you to create and manage resources such as instances, volumes, and subnets using consistent zone identifiers. AZ IDs are consistent and static identifiers that represent the same physical location across all AWS accounts, helping you optimize resource placement.
Prior to this launch, you had to use an AZ name while creating a resource, but these names could map to different physical locations. This mapping made it difficult to ensure resources were always co-located especially when operating with multiple accounts. Now, you can specify the AZ ID parameter directly in your EC2 APIs to guarantee consistent placement of resources. AZ IDs always refer to the same physical location across all accounts, which means you no longer need to manually map AZ names across your accounts or deal with the complexity of tracking and aligning zones. This capability is now available for resources including instances, launch templates, hosts, reserved instances, fleet, spot instances, volumes, capacity reservations, network insights, VPC endpoints and subnets, network interfaces, fast snapshot restore, and instance connect.
This feature is available in all AWS regions including China and AWS GovCloud (US) Regions. To learn more about Availability Zone IDs, visit the documentation.
The White House’s Genesis Mission has set a bold ambition for our nation: to double our scientific productivity within the decade and harness artificial intelligence (AI) to accelerate the pace of discovery. This requires a profound transformation in our national scientific enterprise, one that seamlessly integrates high-performance computing, world-class experimental facilities, and AI. The challenge is no longer generating exabytes of exquisite data from experiments and simulations, but rather curating and exploring it using AI to accelerate the discoveries hidden within.
Through our Genesis Mission partnership with the Department of Energy (DOE), Google is committed to powering this new era of federally-funded scientific discovery with the necessary tools and platforms.
State-of-the-art reasoning for science
The National Labs can take advantage of Gemini for Government—a secure platform with an accredited interface that provides scaled access to a new class of agentic tools designed to augment the scientific process. This includes access to the full capabilities of Gemini, our most powerful and general-purpose AI model. Its native multimodal reasoning operates across the diverse data types of modern science. This means researchers can ask questions in natural language to generate insights grounded in selected sources—from technical reports, code, and images, to a library of enterprise applications, and even organizational and scientific datasets.
In addition to the Gemini for Government platform, the National Labs will have access to several Google technologies that support their mission. Today, Google DeepMind announced an accelerated access program for all 17 National Labs, beginning with AI co-scientist—a multi-agent virtual collaborator built on Gemini that can accelerate hypothesis development from years to days—with plans to expand to other frontier AI tools in 2026.
Google Cloud provides the secure foundation to bring these innovations to the public sector. By making these capabilities commercially available through our cloud infrastructure, we are ensuring that the latest frontier AI models and tools from Google DeepMind are accessible for the mission-critical work of our National Labs.
Accelerating the research cycle with autonomous workflows
Gemini for Government brings together the best of Google accredited cloud services, industry-leading Gemini models, and agentic solutions. The platform is engineered to enable autonomous workflows that orchestrate complex tasks.
A prime example is Deep Research, which can traverse decades of scientific literature and experimental databases to identify previously unseen connections across different research initiatives or flag contradictory findings that warrant new investigation. By automating complex computational tasks, like managing large-scale simulation ensembles or orchestrating analysis pipelines across hybrid cloud resources, scientists can dramatically accelerate the ‘design-build-test-learn’ cycle, freeing up valuable time for the creative thinking that drives scientific breakthroughs.
To ensure agencies can easily leverage these advanced capabilities—including the DOE and its National Laboratories—Gemini for Government is available under the same standard terms and pricing already established for all federal agencies through the General Services Administration’s OneGov Strategy. This streamlined access enables National Labs to quickly deploy an AI-powered backbone for their most complex, multi-lab research initiatives.
A secure fabric for big team science
The future of AI-enabled research requires interconnected experimental facilities, data repositories, and computing infrastructure stewarded by the National Labs.
Gemini for Government provides a secure, federated foundation required to reimagine “Big Team Science,” creating a seamless fabric connecting the entire DOE complex. AI models and tools in this integrated environment empower researchers to weave together disparate datasets from the field to the benchtop, and combine observations with models, revealing more insights across vast temporal and spatial scales.
Ultimately, this transformation can change the nature of discovery, creating a frictionless environment where AI manages complex workflows, uncovers hidden insights, and acts as a true creative research partner to those at our National Labs.
Learn more about Gemini for Government by registering for Google Public Sector Summit On-Demand. Ready to discuss how Gemini for Government can address your organization’s needs? Please reach out to our Google Public Sector team at geminiforgov@google.com.
Today’s AI capabilities provide a great opportunity to enable natural language (NL) interactions with your enterprise data through applications using text and voice. In fact, in the world of agentic applications, natural language is rapidly becoming the interaction standard. That means agents need to be able to issue natural language questions to a database and receive accurate answers in return. At Google Cloud, this drove us to build Natural-Language-to-SQL (NL2SQL) technology in the AlloyDB database that can receive a question as input and return a NL result, or the SQL query that will help you retrieve it.
Currently in preview, the AlloyDB AI natural language API enables developers to build an agentic application that answers natural language questions on their database data by agents or end users in a secure, business-relevant, explainable manner, with accuracy approaching 100% — and we’re focused on bringing this capability to a broader set of Google Cloud databases.
When we first released the API in 2024, it already provided leading NL2SQL accuracy, albeit not close to 100%. But leading accuracy isn’t enough. In many industries, it’s not sufficient to translate text into SQL with accuracy of 80% or even 90%. Low-quality answers carry a real cost, often measurable in monetary terms: disappointed customers or poor business decisions. A real estate search application that fails to understand what the end user is asking for (their “intent”) risks becoming irrelevant. In retail product search, less relevant answers lead to lower conversions into sales. In other words, the accuracy of the text-to-SQL translation must almost always be extremely high.
In this blog we help you understand the value of the AlloyDB AI natural language API and techniques for maximizing the accuracy of its answers.
Getting to ~100% accurate and relevant results
Achieving highly accurate text-to-SQL takes more than just prompting Gemini with a question. Rather, when developing your app, you need to provide AlloyDB AI with descriptive context, including descriptions of the database tables and columns; this context can be autogenerated. Then, when the AlloyDB AI natural language API receives a question, it can intelligently retrieve the relevant pieces of descriptive context, enabling Gemini to see how the question relates to the database data.
Still, many of our customers asked us for explainable, certifiable and business-relevant answers that would enable them to reach even higher accuracy, approaching 100% (such as >95% or even higher than 99%), for their use cases.
The latest preview release of the AlloyDB AI natural language API provides capabilities for improving your answers in several ways:
Business relevance:Answers should contain and properly rank information in order to improve business metrics, such as conversions or end-user engagement.
Explainability: Results should include anexplanation of intent that clarifies — in language that end users can understand — what the NL API understood the question to be. For example, when a real estate app interprets the question “Can you show me Del Mar homes for families?” as “Del Mar homes that are close to good schools”, it explains its interpretation to the end user.
Verified results:The result should always be consistent with the intent, as it was explained to the user or agent.
Accuracy: The result should correctly capture the intent of the question.
With this, the AlloyDB AI natural language API enables you to progressively improve accuracy for your use case, what’s sometimes referred to as “hill-climbing”. As you work your way towards 100% accuracy, AlloyDB AI’s intent explanations mitigate the effect of the occasional remaining inaccuracies, allowing the end user or agent to understand that the API answered a slightly different question than the one they intended to ask.
aside_block
<ListValue: [StructValue([(‘title’, ‘Get started with a 30-day AlloyDB free trial instance’), (‘body’, <wagtail.rich_text.RichText object at 0x7f5bdd3e8fa0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
Hill-climbing to approximate 100% accuracy
Iteratively improving the accuracy of AlloyDB AI happens via a simple workflow.
First, you start with the NL2SQL API that AlloyDB AI provides out of the box. It’s highly (although not perfectly) accurate thanks to its built-in agent that translates natural language questions into SQL queries, as well as automatically generated descriptive context that is used by the included agent.
Next, you can quickly iterate to hill-climb to approximately 100% accuracy and business relevance by improving context. Crucially, in the AlloyDB AI natural language API, context comes in two forms:
Descriptive context, which includes table and column descriptions, and
Prescriptive context, which includes SQL templates and (condition) facets, allowing you to control how the NL request is translated to SQL.
Finally, a “value index” disambiguates terms (such as SKUs and employee names) that are private to your database, and thus that are not immediately clear to foundation models.
The ability to hill-climb to approximate 100% accuracy flexibly and securely relies on two types of context and the value index in AlloyDB.
Let’s take a deeper look at context and the value index.
1. Descriptive and prescriptive context
As mentioned above, the AlloyDB AI natural language API relies on descriptive and prescriptive context to improve the accuracy of the SQL code it generates.
By improving descriptive context, mostly table and column descriptions, you increase the chances that the SQL queries employ the right tables and columns in the right roles. However, prescriptive context resolves a harder problem: accurately interpreting difficult questions that matter for a given use case. For example, an agentic real-estate application may need to answer a question such as “Can you show me homes near good schools in <provided city>?” Notice the challenges:
What exactly is “near”?
How do you define a “good” school?
Assuming the database provides ratings, what is the cutoff for a good school rating?
What is the optimal tradeoff (for ranking purposes and thus for business relevance of the top results) between distance from the school and ranking of the school when the solutions are presented as a list?
To help, the AlloyDB natural language API lets you supply templates, which allow you to associate a type of question with a parameterized SQL query and a parameterized explanation. This enables the AlloyDB NL API to accurately interpret natural language questions that may be very nuanced; this makes templates a good option for frequently asked, nuanced questions.
A second type of prescriptive context, facets, allows you to provide individual SQL conditions along with their natural language counterparts. Facets enable you to combine the accuracy of templates with the flexibility of searching over a gigantic number of conditions. For example, “near good schools” is just one of many conditions. Others may be price, “good for a young family”, “ocean view” or others. Some are combinations of these conditions, such as “homes near good schools with ocean views”. But you can’t have a template for each combination of conditions. In the past, to accommodate all these conditions, you could have tried to create a dashboard with a search field for every conceivable condition, but it would have become very unwieldy, very fast. Instead, when you use a natural language interface, you can use facets to cover any number of conditions, even in a single search field. This is where the strength of a natural language interface really shines!
The AlloyDB AI natural language API facilitates the creation of descriptive and prescriptive context. For example, rather than providing parameterized questions, parameterized intent explanations, and parameterized SQL, just add a template via the add_template API, in which you provide an example question (“Del Mar homes close to good schools”) and the correct corresponding SQL. AlloyDB AI automatically generalizes this question to handle any city and automatically prepares an intent explanation.
2. The value index
The second key enabler of approximate 100% accuracy is the AlloyDB AI value index, which disambiguates terms that are private to your database and, thus, not known to the underlying foundation model. Private terms in natural language questions pose many problems. For starters, users misspell words, and, indeed, misspellings increase with a voice interface. Second, natural language questions don’t always spell out a private term’s entity type. For instance, a university administrator may ask “How did John Smith perform in 2025?” without specifying whether John Smith is faculty or a student; each case requires a different SQL query to answer the question. The value index clarifies what kind of entity “John Smith” is, and can be automatically created by AlloyDB AI for your application.
Natural language search over structured, unstructured and multimodal data
When it comes to applications that provide search over structured data, the AlloyDB AI natural language API enables a clean and powerful search experience. Traditionally, applications present conditions as filters in the user interface that the end user can employ to narrow their search. In contrast, an NL-enabled application can provide a simple chat interface or even take voice commands that directly or indirectly pose any combination of search conditions, and still answer the question. Once search breaks free from the limitations of traditional apps, the possibilities for completely new user experiences really open up.
The combination of the NL2SQL technology with AI search features also makes it good for querying combinations of structured, unstructured and multimodal data.The AlloyDB AI natural language API can generate SQL queries that include vector search, text search and other AI search features such as the AI.IF condition, which enables checking semantic conditions on text and multimodal data. For example, our real estate app may be asked about “Del Mar move-in ready houses”. This would result in a SQL query with an AI.IF function that checks whether the text in the description column of the real_estate.properties table is similar to “move-in ready”.
Bringing the AlloyDB AI natural language API into your agentic application
Ready to integrate the AlloyDB AI natural language API into your agentic application? If you’re writing AI tools (functions) to retrieve data from AlloyDB, give MCP Toolbox for Databases a try. Or for no-code agentic programming, you can use Gemini Enterprise. For example, you can create a conversational agentic application that uses Gemini to answer questions from its knowledge of the web and the data it draws from your database — all without writing a single line of code! Either way, we look forward to seeing what you build.
At Google Cloud, we continue to make critical investments to Vertex AI Agent Builder, our comprehensive and open platform, enabling you to build faster, scale efficiently, and govern with enterprise-grade security.
Today, with the integration of the Cloud API Registry, we’re excited to bring enhanced tool governance capabilitiestoVertex AI Agent Builder. With this latest update, administrators can now manage available tools for developers across your organization directly in Vertex AI Agent Builder Console, and developers can leverage tools managed by the registry with a new ApiRegistry.
With this, organizations can anchor agents in the embedded security and operational controls that they already use, enabling deploying and managing agents as a digital workforce.
Following last month’s expansion of our Agent Builder platform, we are also introducing new capabilities across the entire agent lifecycle to help developers build faster using new ADK capabilities and visual tools, and scale with high performance through the expansion of Agent Engine services, including the general availability of support for sessions and memory. Read more below.
1. Govern your tools with confidence
Building a useful agent requires the agent to have access to the necessary tools. However, developers today spend a significant amount of time building their tools for each agent, resulting in duplicate work. This approach also presents challenges for administrators who want to control what data and tools agents can access.
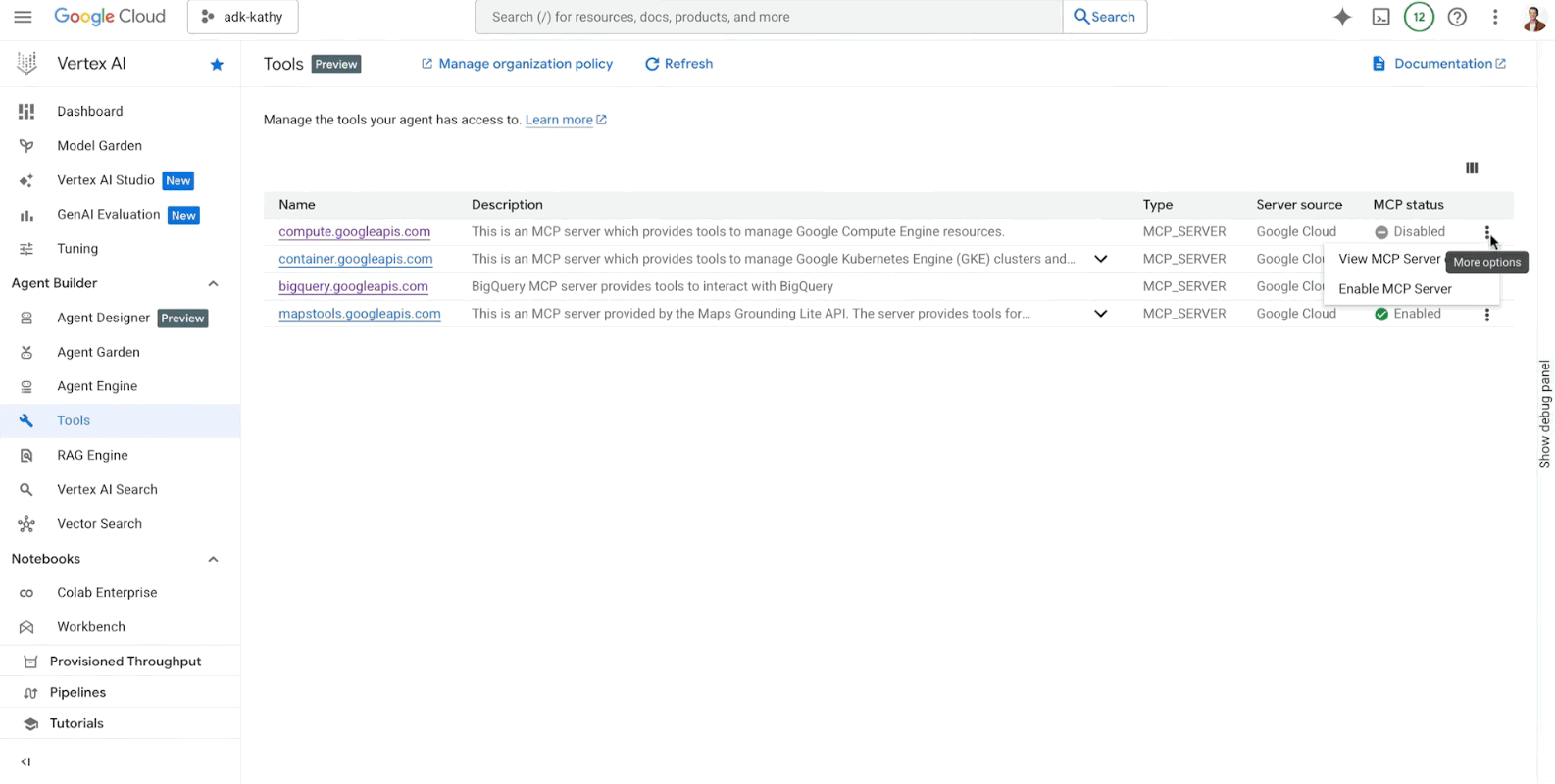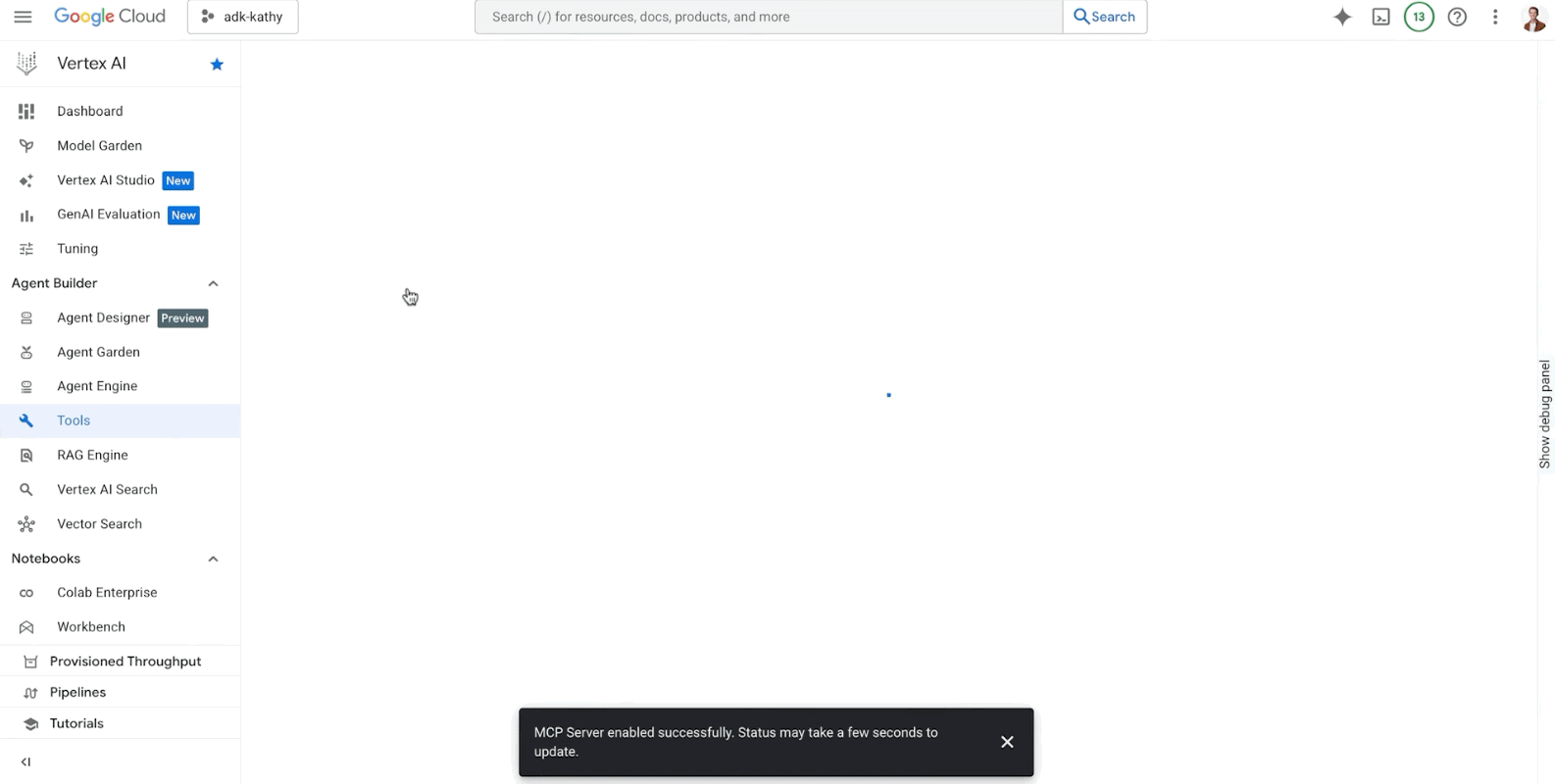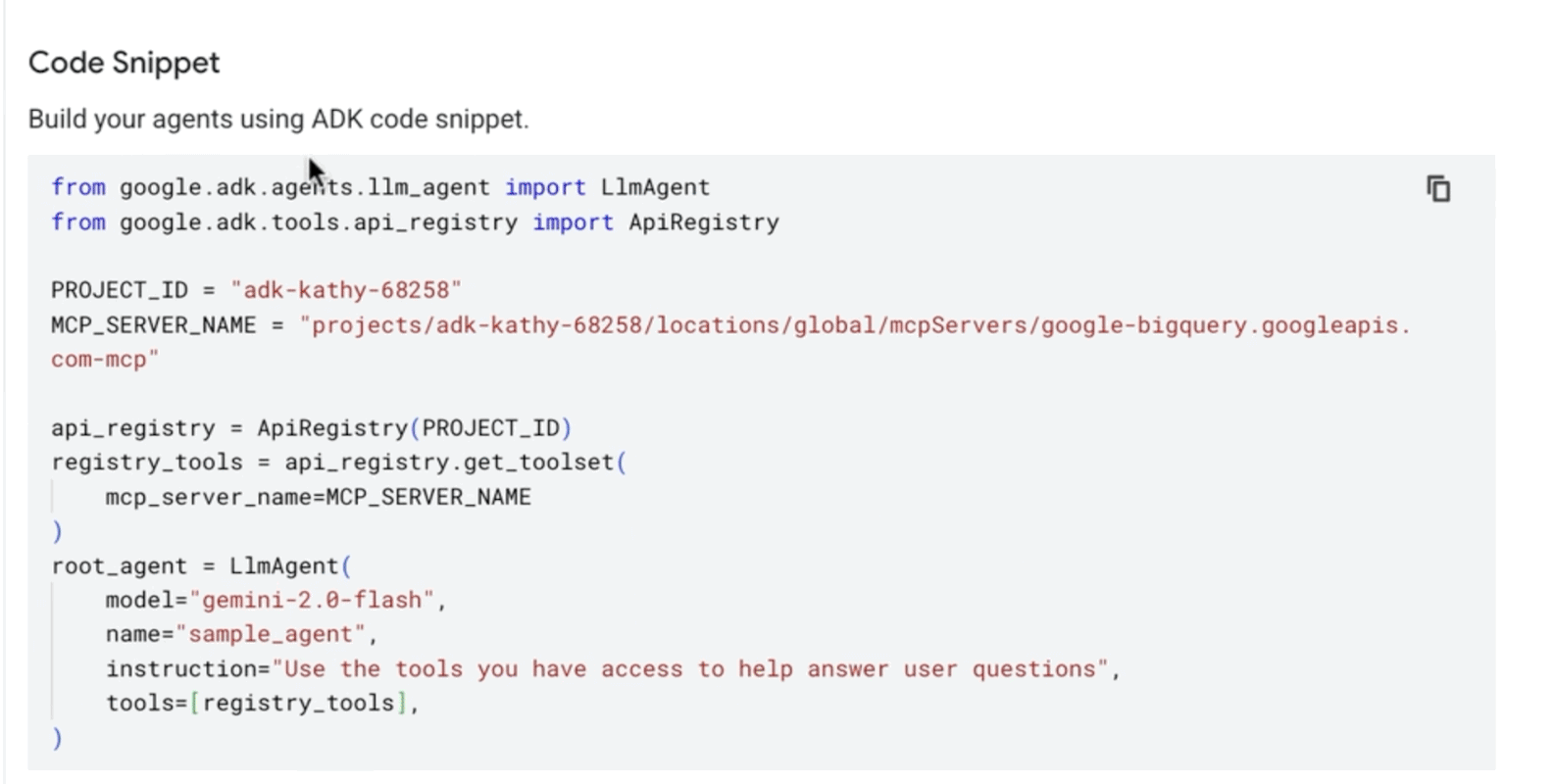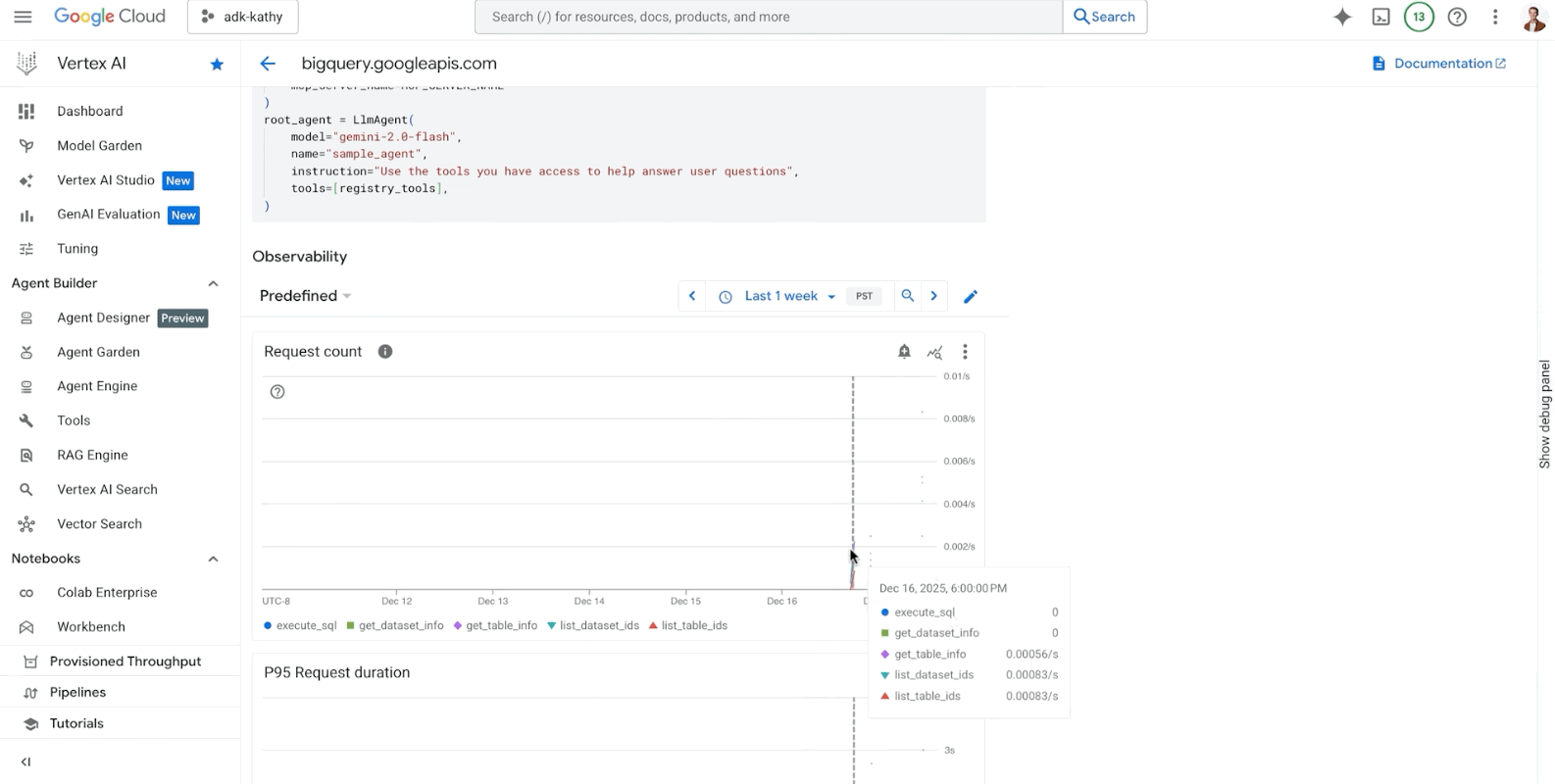
We are bringing enhanced tool governance with the integration of Cloud API Registry in the Vertex AI Agent Builder Console. This acts as a private registry that administrators can use to curate and govern a set of approved tools for developers to use across their organization, providing:
Pre-built tools for Google services: We recently announced MCP support for Google services like BigQuery and Google Maps, which will be available for use in Vertex AI Agent Builder.
Support for custom MCP servers: Unlock your entire API estate for the agentic age. Apigee now empowers you to transform your existing managed APIs into custom MCP servers, bridging your established digital assets with modern AI workflows. Additionally, by bringing these tools from multiple clouds into Apigee API hub, you help ensure your agent developers have instant and secure access to a curated catalog through the Cloud API Registry.
Enhanced tool management: Administrators using the new experience in Vertex AI Agent Builder to view, govern, and manage tools can now ensure the right tools are available to developers in their organization.
Simplified tool access: For developers, Agent Development Kit (ADK) introduces support of Cloud API Registry, introducing a new ApiRegistry object to easily leverage managed tools.
The demo above showcases the new user journey for managing and governing tools directly within the Vertex AI Agent Builder Console
2. Build your AI agents faster
Last month, we released Gemini 3 Pro, our most intelligent model, to every developer and enterprise team. It’s the best model in the world for multimodal understanding, and our most powerful agentic model yet. With full compatibility with ADK, you can now build, test, and deploy powerful AI agents with greater reliability and confidence. We are introducing new capabilities to help you move from concept to interactive product:
Full ADK support of Gemini 3 Pro and Flash: ADK now fully supports Gemini 3 Pro and Flash, allowing you to build reliable, production-ready agents.
ADK for TypeScript: We are extending ADK support for TypeScript, ensuring you can leverage the latest capabilities in ADK directly in whatever language you choose.
State management in ADK: We’ve made significant improvements to our agentic state management within ADK, which is the system for an AI agent to maintain context and memory during and across conversations. New improvements include:
Recovery from failure: If a conversation crashes due to an error, ADK now restores the state natively, requiring no additional work from the developer.
Continue with human-in-the-loop: You can now pause for human input anywhere, even inside complex workflows. ADK automatically remembers exactly where the agent stopped and resumes immediately after approval, so you don’t have to write extra code to track progress.
Rewind state and context: Developers can now rewind to any point in the conversation and invalidate all interactions after that point so the user can remove the “polluted” context rather than send a new message. This allows users to try different approaches to solving a problem without having to open new sessions.
Interactions API integration: ADK and the Agent2Agent protocol (A2A) now support the new Interactions API, providing a consistent way to manage multimodal input/output (text, audio, visual) across your agents, simplifying integration with client applications.
A2UI: Built on top of A2A protocol, A2UI is an early-stage UI toolkit to facilitate LLM-generated UIs for remote agents. This allows you to enable agents to pass shared UI widgets and components directly to user-facing applications without the security risks and overhead of iframes or sending executable code, allowing you to build rich user experiences securely.
Above is a demo showcasing A2UI in action where the user uploads a photo, a remote agent uses Gemini to understand it, and dynamically generates a custom form using A2UI for the specific needs of the customer.
You can start building today with adk-samples on GitHub or on Vertex AI Agent Garden, a growing repository of curated agent samples, solutions, and tools designed to accelerate your development and support one-click deployment of your agents built with ADK. Access our Agent Starter Pack, a template collection that provides a production-ready foundation for building, testing, and deploying AI agents.
3. Scale your AI agents effectively
Once you’ve built your agent, the next challenge is going into a production environment. That’s why we continue to expand the managed services available in Agent Engine to provide the core capabilities needed to scale your agents.
Manage context with confidence: We are movingAgent Engine sessions and memory bank to General Availability (GA). You can now use Agent Engine to manage both short-term and long-term memory for your production workloads. This allows your agents to maintain context across different interactions, which is critical for delivering helpful, personalized responses at scale. This product is powered by Google Cloud AI Research’s novel research method (accepted by ACL 2025), using a topic-based approach that sets a new standard for how agents learn and recall information.
Expanded regional support for Agent Engine services: All Agent Engine services are now available in seven additional regions worldwide. To learn more, refer to the documentation.
Pricing updates for Agent Engine: We lowered pricing for the Agent Engine runtime and will begin billing for additional Agent Engine services starting on January 28, 2026. You can review the Agent Engine pricing documentation for additional detail and hypothetical agent cost scenarios.
Product
Resource
SKU
Prior pricing
New pricing
Price change date
Runtime
vCPU / hour
8A55-0B95-B7DC
$0.0994
$0.0864
December 16, 2025
Memory / GB-hr
0B45-6103-6EC1
$0.0105
$0.0090
December 16, 2025
Code Execution
vCPU / hour
448F-9419-C2EE
Free
$0.0864
January 28, 2026
Memory / GB-hr
AC0F-52B0-CE44
Free
$0.0090
January 28, 2026
Sessions
Stored session events
0D5A-FCD2-CB63
Free
$0.25/1,000 events
January 28, 2026
Memory Bank
Memories stored per month
E954-622B-C859
Free
$0.25/1,000 memories
(LLM costs billed separately)
January 28, 2026
Memories retrieved
6DEC-3026-DDFF
Free
$0.50/1,000 memories
January 28, 2026
The table above shows updated pricing for Agent Engine services and when the changes take place.
How customers are achieving more with Agent Builder
“Burns & McDonnell uses Vertex AI Agent Builder to transform how organizational knowledge is applied across the enterprise. With Experience IQ, we are building an AI agent using ADKthat turns decades of project data and employee experience into real-time, actionable intelligence. Vertex AI enables this innovation to scale responsibly by combining deterministic business rules with probabilistic reasoning, making AI a trusted operational capability — not just a productivity tool. This agent helps teams quickly identify the right experience, reduce manual effort in staffing and planning, and make higher-confidence decisions grounded in verified data. With Vertex AI, Burns & McDonnell isn’t just managing knowledge — we are activating experience to drive faster, more confident decisions.” – Matt Olson, Chief Innovation Officer, Burns & McDonnell
“Payhawk uses Vertex AI Agent Builder to transform agents into financial assistants that truly ‘know’ our customers. Leveraging Memory Bank, we moved from stateless interactions to long-term context retention, allowing agents to recall user constraints and historical patterns with continuity. For example, our Financial Controller Agent now remembers habits like expensing small meals and auto-submits them, reducing submission time by over 50%. Similarly, our Travel Agent proactively applies preferences like aisle seats. This significantly drops cognitive load, allowing agents to anticipate needs based on past behavior rather than just reacting to prompts.” – Diyan Bogdanov, Principal Applied AI Engineer, Payhawk
“Gurunavi uses Vertex AI Agent Builderto power ‘UMAME!’, an AI restaurant discovery app that leverages Agent Engine’s Memory Bank to overcome a significant challenge: achieving a deep understanding of user context. Unlike conventional prompt-based systems, our agent leverages memory bank to remember a user’s past actions, preferences, and temporal patterns to proactively present the best options. This eliminates the need for manual searches, creating a seamless experience. We project this context-aware capability will improve user experience by 30% or more. We view this memory function as a non-negotiable feature for helping everyone forge new culinary experiences together with AI.” – Toshiaki Iwamoto, CTO, Gurunavi
“SeaArt Entertainment uses Vertex AI Agent Builder to personalize the creative experience for digital artists. Before Memory Bank, our AI agents could not reliably remember users’ preferences. For example, when users worked on complex multimodal art projects, they had to repeatedly explain the same details — like their favorite character styles or model choices — across sessions. After integrating Memory Bank, our agents are now able to recall past conversations, actions, and user preferences. We especially like that the agent can seamlessly remember context across sessions, making interactions feel more natural and personal.” – Aleksei Savin, Lead of Multimodal AI Platform, SeaArt Entertainment
Get started
Vertex AI Agent Builder provides the unified platform to manage the entire agent lifecycle, helping you close the gap from prototype to a production-ready agent. To explore these new features, visit the updated Agent Builder documentation and release notes.
If you’re a startup and you’re interested in learning more about building and deploying agents, download the Startup Technical Guide: AI Agents. This guide provides the knowledge needed to go from an idea to prototype to scale, whether your goals are to automate tasks, enhance creativity, or launch entirely new user experiences for your startup.
Amazon WorkSpaces Applications now offers support for Ubuntu Pro 24.04 LTS on Elastic fleets, enabling Independent Software Vendors (ISVs) and central IT organizations to stream Ubuntu desktop applications to users while leveraging the flexibility, scalability, and cost-effectiveness of the AWS Cloud.
Amazon WorkSpaces Applications is a fully managed, secure desktops and applications streaming service that provides users with instant access to their desktops and applications from anywhere. Within Amazon WorkSpaces Applications, Elastic fleet is a server less fleet type that lets you stream desktop applications to your end users from an AWS-managed pool of streaming instances without needing to predict usage, create and manage scaling policies, or create an image. Elastic fleet type is designed for customers that want to stream applications to users without managing any capacity or creating WorkSpaces Applications images.
To get started sign into the WorkSpaces Applications management console and select one of the AWS Region of your choice. For the full list of Regions where WorkSpaces Applications is available, see the AWS Region Table. Amazon WorkSpaces Applications offers pay-as-you-go pricing. For more information, see Amazon WorkSpaces Applications Pricing.
Amazon WorkSpaces now supports IPv6 for WorkSpaces domains and external endpoints, enabling users to connect through an IPv4/IPv6 dual-stack configuration from compatible clients (excluding SAML authentication). This helps customers meet IPv6 compliance requirements and eliminates the need for costly networking equipment to handle address translation between IPv4 and IPv6.
Dual-stack support for WorkSpaces addresses the Internet’s growing demand for IP addresses by offering a vastly larger address space than IPv4. This eliminates the need to manage overlapping address ranges within your Virtual Private Cloud (VPC). Customers can deploy WorkSpaces through dual-stack that supports both IPv4 and IPv6 protocols while maintaining backward compatibility with existing IPv4 systems. Customers can also connect to their WorkSpaces through PrivateLink VPC endpoints over IPv6, enabling them to access the service privately without routing traffic over the public internet.
Connecting to Amazon WorkSpaces over IPv4/IPv6 dual-stack configuration is supported in all AWS Regions where Amazon WorkSpaces is available, including the AWS GovCloud (US East & US West) Regions. There is no additional cost for this feature.