Amazon FSx for NetApp ONTAP second-generation file systems are now available in additional AWS Regions: Asia Pacific (Mumbai), and Asia Pacific (Tokyo).
Amazon FSx makes it easier and more cost effective to launch, run, and scale feature-rich high-performance file systems in the cloud. Second-generation FSx for ONTAP file systems give you more performance scalability and flexibility over first-generation file systems by allowing you to create or expand file systems with up to 12 highly-available (HA) pairs of file servers, providing your workloads with up to 72 GBps of throughput and 1 PiB of provisioned SSD storage.
With this regional expansion, second-generation FSx for ONTAP file systems are available in the following AWS Regions: US East (N. Virginia, Ohio), US West (N. California, Oregon), Europe (Frankfurt, Ireland, Stockholm), and Asia Pacific (Mumbai, Singapore, Sydney, Tokyo). You can create second-generation Multi-AZ file systems with a single HA pair, and Single-AZ file systems with up to 12 HA pairs. To learn more, visit the FSx for ONTAP user guide.
Today, we’re announcing new and improved agentic Amazon Q Developer experience in the AWS Management Console, Microsoft Teams, and Slack. Amazon Q Developer can now answer more complex queries than ever before in the AWS Management Console chat, offering deeper resource introspection and a dynamic, more interactive troubleshooting experience for users.
Till today, Amazon Q Developer helped simplify manual work needed from cloud engineering teams to monitor and troubleshoot resources by answering basic AWS questions and providing specialized guidance. Now, it combines deep AWS expertise with new multi-step reasoning capabilities that enable it to consult multiple information sources and resolve complex queries within the AWS Management Console and chat applications.Customers can ask questions about AWS services and their resources, leaving Amazon Q to automatically identify the appropriate capabilities tools for the task, selecting from AWS APIs across 200+ services. Amazon Q breaks all queries into executable steps, asks for clarification when needed, and combines information from multiple services to solve the task. For example, you can ask, “Why am I getting 500 errors from my payment processing Lambda function?” and Q automatically gathers relevant CloudWatch logs, examines function’s configuration and permissions, checks connected services like API Gateway and DynamoDB and analyzes recent changes – all while showing progress and reasoning to enable builders to work more efficiently.
These new capabilities are accessible in all AWS regions where Amazon Q Developer is available. Learn more in this deep-dive blog.
Amazon Lex now offers AWS CloudFormation support in AWS GovCloud (US-West), extending infrastructure-as-code capabilities to government agencies and their partners.Additionally, CloudFormation support also now includes composite slots and QnAIntent features across all AWS regions where Amazon Lex operates, allowing developers to define, deploy, and manage these advanced conversational components through CloudFormation templates.
With CloudFormation support in AWS GovCloud (US-West), government agencies can now automate the deployment of Amazon Lex chatbots while maintaining compliance with strict security requirements. Additionally, two key conversational AI features are now supported via CloudFormation: composite Slots, which enable more natural interactions by collecting multiple data points in a single prompt (e.g., “Please provide your city and state” instead of separate questions), and QnAIntent, which automatically answers user questions by searching configured knowledge bases and returning relevant information from documents, FAQs, or knowledge bases.
CloudFormation support for Amazon Lex including composite slots and QnAIntent, is available in all AWS Regions where Amazon Lex operates.
Cost Optimization Hub now supports instance and cluster storage recommendations for Amazon Aurora databases. These recommendations help you identify idle database instances and choose the optimal DB instance class and storage configuration for your Aurora databases.
With this launch, you can view, filter, consolidate, and prioritize Aurora optimization recommendations across your organization’s member accounts and AWS Regions through a single dashboard. Cost Optimization Hub quantifies estimated savings from these recommendations, taking into account your specific discounts, such as Reserved Instances, enabling you to evaluate Aurora cost savings alongside other cost optimization opportunities.
The new Amazon Aurora recommendations are now available in Cost Optimization Hub across all AWS Regions where Cost Optimization Hub is supported.
Today, Amazon DataZone and Amazon SageMaker announced a new user interface (UI) capability allowing a DataZone domain to be upgraded and used directly in the next generation of Amazon SageMaker. This makes the investment customers put into developing Amazon DataZone transferable to Amazon SageMaker. All content created and curated through Amazon DataZone such as assets, metadata forms, glossaries, subscriptions, etc. are available to users through Amazon SageMaker Unified Studio after the upgrade.
As an Amazon DataZone administrator, you can choose which of your domains to upgrade to Amazon SageMaker via a UI driven experience. The upgraded domain lets you leverage your existing Amazon DataZone implementation in the new Amazon SageMaker environment and expand to new SQL analytics, data processing and AI uses cases. Additionally, after upgrading both Amazon DataZone and Amazon SageMaker portals remain accessible. This provides administrators flexibility with user rollout of Amazon SageMaker, while ensuring business continuity for users operating within Amazon DataZone. By upgrading to Amazon SageMaker, users can build on their investment from Amazon DataZone by utilizing Amazon SageMaker’s unified platform that serves as the central hub for all data, analytics, and AI needs.
The domain upgrade capability is available in all AWS Regions where Amazon DataZone and Amazon SageMaker is supported, including: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Asia Pacific (Seoul), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (Stockholm), Europe (London), South America (São Paulo), Mumbai (BOM), Stockholm (ARN), and Paris (CDG).
AWS Compute Optimizer now provides Amazon Aurora I/O-Optimized recommendations for Aurora DB Cluster Storage. These recommendations help make informed decisions about adopting Aurora I/O-Optimized configurations to increase pricing predictability and achieve potential cost savings based on your cluster’s storage patterns and usage.
AWS Compute Optimizer automatically analyzes your Aurora DB clusters’ instance storage and I/O costs to provide detailed cost comparisons between Aurora I/O-Optimized and Aurora Standard configurations. By default, Compute Optimizer analyzes 14 days of metrics, which you can extend to 32 days for free or up to 93 days with enhanced infrastructure metrics enabled. With enhanced metrics, you can also view month-over-month I/O usage variations to better evaluate the benefits of each storage configuration.
This new feature is available in all AWS Regions where AWS Compute Optimizer is available except the AWS GovCloud (US) and the China Regions. To learn more about the new feature updates, please visit Compute Optimizer’s product page and user guide.
You can never be sure when you’ll be the target of a distributed denial-of-service (DDoS) attack. For investigative journalist Brian Krebs, that day came on May 12, when his site KrebsOnSecurity experienced one of the largest DDoS attacks seen to date.
At 6.3 terabits per second (Tbps), or roughly 63,000 times the speed of broadband internet in the U.S., the attack was 10 times the size of the DDoS attack Krebs faced in 2016 from the Mirai botnet. That 2016 incident took down KrebsOnSecurity.com for four days, and was so severe that his then-DDoS protection service asked him to find another provider, Krebs said in his report on the May attack.
Following the 2016 incident, Krebs signed up for Project Shield, a free Google service that offers at-risk, eligible organizations protection against DDoS attacks. Since then, his site has stayed reliably online in the face of attacks — including the latest incident.
The brunt of the May 12 attack lasted less than a minute and peaked above 6.3 Tbps, one of the largest DDoS attacks observed to date.
Organizations in eligible categories, including news publishers, government elections, and human rights defenders, can use the power of Google Cloud’s networking services in conjunction with Jigsaw to help keep their websites available and online.
Project Shield acts as a reverse proxy service — customers change their DNS settings to send traffic to an IP address provided by Project Shield, and configure Project Shield with information about their hosting server. The customer retains control over both their DNS settings and their hosting server, making it easy to enable or disable Project Shield at any time with a simple DNS switch.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3eb979a834c0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Built on the strength of Google Cloud networking services, including Cloud Load Balancing, Cloud CDN, and Cloud Armor, Project Shield’s services can be configured through the Project Shield dashboard as a managed experience. This solution works together to mitigate attacks and serve cached content from multiple points on Google’s edge network. It’s a combination that has protected KrebsOnSecurity before, and has successfully defended many websites against some of the world’s largest DDoS attacks.
In the May incident against Krebs, the attack was filtered instantly by Google Cloud’s network. Requests for websites protected by Project Shield pass through Google Cloud Load Balancing, which automatically blocks layer 3 and layer 4 volumetric DDoS attacks.
In the May incident, the attacker sent large data packets to random ports at a rate of approximately 585 million packets per second, which is over 1,000 times the usual rate for KrebsOnSecurity.
The attack came from infected devices all around the world.
Cloud Armor, which embeds protection into every load balancer deployment, blocked the attack at the load balancing level because Project Shield sits behind the Google Cloud Load Balancer, which proxies only HTTP/HTTPS traffic. Had the attack occurred with well-formed requests (such as at Layer 7, also known as the application layer), additional defenses from the Google Cloud global front end would have been ready to defend the site.
Cloud CDN, for example, makes it possible to serve content for sites like KrebsOnSecurity from cache, lessening the load on a site’s servers. Cloud Armor would have actively filtered incoming requests for any remaining traffic that may have bypassed the cache to allow only legitimate traffic through.
Additionally, Cloud Armor’s Adaptive Protection uses real-time machine learning, which helps identify attack signatures and dynamically tailor rate limits. These rate limits are actively and continuously refined, allowing Project Shield to harness Google Cloud’s capabilities to mitigate almost all DDoS attacks in seconds.
Project Shield defenses are automated, with no customer defense configuration needed. They’re optimized to capitalize on the powerful blend of defensive tools in Google Cloud’s networking arsenal, which are available to any Google Cloud customer.
As KrebsOnSecurity and others have experienced, DDoS attacks have been getting larger, more sophisticated, and more frequent in recent years. Let the power and scale of Google Cloud help protect your site against attacks when you least expect them. Eligible organizations can apply for Project Shield today, and all organizations can set up their own Cloud Networking configuration like Project Shield by following this guide.
Developers love Cloud Run, Google Cloud’s serverless runtime, for its simplicity, flexibility, and scalability. And today, we’re thrilled to announce that NVIDIA GPU support for Cloud Run is now generally available, offering a powerful runtime for a variety of use cases that’s also remarkably cost-efficient.
Now, you can enjoy the following benefits across both GPUs and CPUs:
Pay-per-second billing: You are only charged for the GPU resources you consume, down to the second.
Scale to zero: Cloud Run automatically scales your GPU instances down to zero when no requests are received, eliminating idle costs. This is a game-changer for sporadic or unpredictable workloads.
Rapid startup and scaling Go from zero to an instance with a GPU and drivers installed in under 5 seconds, allowing your applications to respond to demand very quickly. For example, when scaling from zero (cold start), we achieved an impressive Time-to-First-Token of approximately 19 seconds for a gemma3:4b model (this includes startup time, model loading time, and running the inference)
Full streaming support: Build truly interactive applications with out-of-the box support for HTTP and WebSocket streaming, allowing you to provide LLM responses to your users as they are generated.
Support for GPUs in Cloud Run is a significant milestone, underscoring our leadership in making GPU-accelerated applications simpler, faster, and more cost-effective than ever before.
“Serverless GPU acceleration represents a major advancement in making cutting-edge AI computing more accessible. With seamless access to NVIDIA L4 GPUs, developers can now bring AI applications to production faster and more cost-effectively than ever before.” – Dave Salvator, director of accelerated computing products, NVIDIA
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3eb98c7c11c0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
AI inference for everyone
One of the most exciting aspects of this GA release is that Cloud Run GPUs are now available to everyone for NVIDIA L4 GPUs, with no quota request required.This removes a significant barrier to entry, allowing you to immediately tap into GPU acceleration for your Cloud Run services. Simply use --gpu 1 from the Cloud Run command line, or check the “GPU” checkbox in the console, no need to request quota:
Production-ready
With general availability, Cloud Run with GPU support is now covered by Cloud Run’s Service Level Agreement (SLA), providing you with assurances for reliability and uptime. By default, Cloud Run offers zonal redundancy, helping to ensure enough capacity for your service to be resilient to a zonal outage; this also applies to Cloud Run with GPUs. Alternatively, you can turn off zonal redundancy and benefit from a lower price for best-effort failover of your GPU workloads in case of a zonal outage.
Multi-regional GPUs
To support global applications, Cloud Run GPUs are available in five Google Cloud regions: us-central1 (Iowa, USA), europe-west1 (Belgium), europe-west4 (Netherlands), asia-southeast1 (Singapore), and asia-south1 (Mumbai, India), with more to come.
Cloud Run also simplifies deploying your services across multiple regions. For instance, you can deploy a service across the US, Europe and Asia with a single command, providing global users with lower latency and higher availability. For instance, here’s how to deploy Ollama, one of the easiest way to run open models, on Cloud Run across three regions:
See it in action: 0 to 100 NVIDIA GPUs in four minutes
You can witness the incredible scalability of Cloud Run with GPUs for yourself with this live demo from Google Cloud Next 25, showcasing how we scaled from 0 to 100 GPUs in just four minutes.
Load testing a Stable Diffusion service running on Cloud Run GPUs to 100 GPU instances in four minutes.
Unlock new use cases with NVIDIA GPUs on Cloud Run jobs
The power of Cloud Run with GPUs isn’t just for real-time inference using request-driven Cloud Run services. We’re also excited to announce the availability of GPUs on Cloud Run jobs, unlocking new use cases, particularly for batch processing and asynchronous tasks:
Model fine-tuning: Easily fine-tune a pre-trained model on specific datasets without having to manage the underlying infrastructure. Spin up a GPU-powered job, process your data, and scale down to zero when it’s complete.
Batch AI inferencing: Run large-scale batch inference tasks efficiently. Whether you’re analyzing images, processing natural language, or generating recommendations, Cloud Run jobs with GPUs can handle the load.
Batch media processing: Transcode videos, generate thumbnails, or perform complex image manipulations at scale.
What Cloud Run customers are saying
Don’t just take our word for it. Here’s what some early adopters of Cloud Run GPUs are saying:
“Cloud Run helps vivo quickly iterate AI applications and greatly reduces our operation and maintenance costs. The automatically scalable GPU service also greatly improves the efficiency of our AI going overseas.” – Guangchao Li, AI Architect, vivo
“L4 GPUs offer really strong performance at a reasonable cost profile. Combined with the fast auto scaling, we were really able to optimize our costs and saw an 85% reduction in cost. We’ve been very excited about the availability of GPUs on Cloud Run.” – John Gill at Next’25, Sr. Software Engineer, Wayfair
“At Midjourney, we have found Cloud Run GPUs to be incredibly valuable for our image processing tasks. Cloud Run has a simple developer experience that lets us focus more on innovation and less on infrastructure management. Cloud Run GPU’s scalability also lets us easily analyze and process millions of images.” – Sam Schickler, Data Team Lead, Midjourney
Amazon Managed Workflows for Apache Airflow (MWAA) now provides the option to update environments without interrupting running tasks on supported Apache Airflow versions (v2.4.3 or later).
Amazon MWAA is a managed service for Apache Airflow that lets you use the same familiar Apache Airflow platform as you do today to orchestrate your workflows and enjoy improved scalability, availability, and security without the operational burden of having to manage the underlying infrastructure. Amazon MWAA now allows you to update your environment without disrupting your ongoing workflow tasks. By choosing this option, you are now able to update an MWAA environment in graceful manner where MWAA will replace Airflow Scheduler and Webserver components, provision new workers, and wait for ongoing worker tasks to complete before removing older workers. The graceful option is available only for supported Apache Airflow versions (v2.4.3 or later) on MWAA.
Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundationin the United States and/or other countries.
Red Hat Enterprise Linux (RHEL) for AWS, starting with RHEL 10, is now generally available, combining Red Hat’s enterprise-grade Linux software with native AWS integration. RHEL for AWS isbuilt to achieve optimum performance of RHEL running on AWS. This offering features pre-tuned images with AWS-specific performance profiles, built-in Amazon CloudWatch telemetry, integrated AWS Command Line Interface (CLI), image mode using container-native tooling, enhanced security from boot to runtime, and optimized networking with Elastic Network Adapter (ENA) support.
For organizations looking to accelerate innovation and meet customer demands, RHEL for AWS combines the stability of RHEL with native AWS integration. This purpose-built solution is designed to deliver optimized performance, improved security, and simplified management through AWS-specific configurations and tooling. Whether migrating existing workloads or deploying new instances, RHEL for AWS provides a standardized, ready-to-use software that can help teams reduce operational overhead and focus on business initiatives rather than infrastructure management. Customers can save valuable time with built-in AWS service integration, automated monitoring, and streamlined deployment options.
Customers can access RHEL for AWS Amazon Machine Images (AMIs) through the Amazon EC2 Console or AWS Marketplace with flexible procurement options. Please visit Red Hat Enterprise Linux on Amazon EC2 FAQs page for more details.
The service is available across all AWS Commercial and AWS GovCloud (US) Regions. To get started with RHEL for AWS, visit EC2 console or AWS Marketplace.
Kubernetes version 1.33 introduced several new features and bug fixes, and AWS is excited to announce that you can now use Amazon Elastic Kubernetes Service (EKS) and Amazon EKS Distro to run Kubernetes version 1.33. Starting today, you can create new EKS clusters using version 1.33 and upgrade existing clusters to version 1.33 using the EKS console, the eksctl command line interface, or through an infrastructure-as-code tool.
Kubernetes version 1.33 includes stable support for sidecar containers, topology-aware routing and traffic distribution, and consideration of taints and tolerations when calculating pod topology spread constraints, ensuring that pods are distributed across different topologies according to their specified tolerance. This release also adds support for user namespaces within Linux pods, dynamic resource allocation for network interfaces, and in-place resource resizing for vertical scaling of pods. To learn more about the changes in Kubernetes version 1.33, see our documentation and the Kubernetes project release notes.
EKS now supports Kubernetes version 1.33 in all the AWS Regions where EKS is available, including the AWS GovCloud (US) Regions.
You can learn more about the Kubernetes versions available on EKS and instructions to update your cluster to version 1.33 by visiting EKS documentation. You can use EKS cluster insights to check if there any issues that can impact your Kubernetes cluster upgrades. EKS Distro builds of Kubernetes version 1.33 are available through ECR Public Gallery and GitHub. Learn more about the EKS version lifecycle policies in the documentation.
Today, AWS announces the general availability of the AWS Pricing Calculator in the AWS console. This launch enables customers to create more accurate and comprehensive cost estimates by providing two types of cost estimates: cost estimation for a workload, and estimation of a full AWS bill. You can also import your historical usage or create net new usage when creating a cost estimate. Additionally, the AWS Pricing Calculator now offers three rate configurations, including an after discounts and commitments view, allowing customers to see how both AWS pricing and volume discounts, as well as existing commitments, impact the total estimated cost of a workload estimate.
With the new rate configuration inclusive of both pricing discounts and purchase commitments, customers can gain a clearer picture of potential savings and cost optimizations for their cost scenarios. This feature is particularly useful for organizations looking to understand the impact of their existing commitments, such as Savings Plans or Reserved Instances, on their overall AWS costs. Additionally, customers can now export workload estimates directly from the console in both CSV and JSON formats, including resource-level details for estimated and historical costs. This enhancement facilitates easier analysis, sharing, and integration of estimates with internal financial planning tools.
The enhanced Pricing Calculator is available in all AWS commercial regions, excluding China. To get started with new Pricing Calculator, visit the AWS Billing and Cost Management Console. To learn more visit the AWS Pricing Calculator user guide.
Mountpoint for Amazon S3 now lets you automatically mount an S3 bucket when your Amazon EC2 instance starts up. This simplifies how you define a consistent mounting configuration that automatically applies when your instance starts up and persists the mount when the instance reboots.
Previously, to use Mountpoint for Amazon S3, you had to manually mount an S3 bucket after every boot and validate the correct mount options. Now, with support for automatic bucket mounting, you can add your Mountpoint configuration to the fstab file so it is automatically applied every time your instance starts up. Linux system administrators commonly use fstab to manage mount configurations centrally. It contains information about all the available mounts on your compute instance. Once you modify the fstab file to add a new entry for Mountpoint for Amazon S3, your EC2 instance will read the configuration to automatically mount the S3 bucket whenever it restarts.
Mountpoint for Amazon S3 is an open source project backed by AWS support, which means customers with AWS Business and Enterprise Support plans get 24/7 access to cloud support engineers. To get started, visit the GitHub page and product overview page.
Today, Amazon Elastic Kubernetes Services (Amazon EKS) announced the general availability of configuration insights for Amazon EKS Hybrid Nodes. These new insights surface configuration issues impacting the functionality of Amazon EKS clusters with hybrid nodes, and provide actionable guidance on how to remediate identified misconfigurations. Configuration insights are available through the Amazon EKS cluster insights APIs and on the observability dashboard in the Amazon EKS console.
Amazon EKS cluster insights now automatically scans Amazon EKS clusters with hybrid nodes to identify configuration issues impairing Kubernetes control plane-to-webhook communication, kubectl commands like exec and logs, and more. Configuration insights surface issues and provide remediation recommendations, accelerating the time to a fully functioning hybrid nodes setup.
Configuration insights for Amazon EKS Hybrid Nodes are available in all AWS Regions where Amazon EKS Hybrid Nodes is available. To get started visit the Amazon EKS User Guide.
Today, AWS announces the general availability of the AWS CDK Toolkit Library, a Node.js library that provides programmatic access to core AWS CDK functionalities such as synthesis, deployment, and destruction of stacks. This library enables developers to integrate CDK operations directly into their applications, custom CLIs, and automation workflows, offering greater flexibility and control over infrastructure management.
Prior to this release, interacting with CDK required using the CDK CLI, which could present challenges when integrating CDK actions into automated workflows or custom tools. With the CDK Toolkit Library, developers can now build custom CLIs, integrate CDK actions in their existing CI/CD workflows, programmatically enforce guardrails and policies, and manage ephemeral environments.
The AWS CDK Toolkit Library is available in all AWS Regions where the AWS CDK is supported.
For more information and a walkthrough of the feature, check out the blog. To get started with the CDK Toolkit Library, please find the documentation here.
Amazon Redshift now enables cluster relocation by default for RA3 provisioned clusters when creating new clusters or restoring from snapshots. This feature allows you to move a cluster to another Availability Zone (AZ) when resource constraints disrupt cluster operations, maintaining the same endpoint so applications continue without modifications.
Amazon Redshift already provides resiliency by automatically detecting and recovering from drive and node failures. Cluster relocation adds another layer of availability protection against AZ-level issues that might prevent optimal cluster operations. While this setting is now enabled by default for new or restored clusters, existing RA3 provisioned clusters maintain their current configuration unless manually changed. You can manage cluster relocation settings through the AWS Management Console, AWS CLI, or API.
This feature is available at no additional cost for RA3 provisioned clusters across all AWS Regions where RA3 instance types are supported. For more information about cluster relocation, visit our documentation page.
Welcome to the second Cloud CISO Perspectives for May 2025. Today, Enrique Alvarez, public sector advisor, Office of the CISO, explores how government agencies can use AI to improve threat detection — and save money at the same time.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0babaf3580>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Do more with less: How governments can use AI to save money and improve threat detection
By Enrique Alvarez, public sector advisor, Office of the CISO
Enrique Alvarez, public sector advisor, Office of the CISO
Government agencies have long been a pressure chamber for some of cybersecurity’s most confounding problems, particularly constrained budgets and alert fatigue. While there may not be a single, sharp kopis that can slice through this Gordian knot, AI offers a potential solution that we’d be foolish to ignore.
By many measures, the situation government agencies face is dire. Headcounts and budgets are shrinking, cyber threats are increasing, and security alerts routinely threaten to overwhelm security operations center (SOC) team members, increasing toil and reducing effectiveness. The fiscal austerity facing government agencies is further exacerbated by not being able to fill open cybersecurity positions — nor replace departing experienced workers.
Fortunately, advances in AI models and tools provide a way forward.
Cybersecurity threats present significant challenges for government agencies, one exacerbated by decades of patchwork defensive measures.
Discussions around what AI is and what it can do are often sensationalized. For government agencies, a clear understanding of the different AI types is crucial. At its core, AI refers to the ability of machines to simulate human-like cognitive functions such as learning, problem-solving, and decision-making. This broad definition encompasses everything from rule-based systems to complex neural networks.
Scoping the threat: Unique risk profile for government agencies
Cybersecurity threats present significant challenges for government agencies, one exacerbated by decades of patchwork defensive measures.
The lack of a clear strategy and standardization across agencies has led to a fragmented security posture and a limited common operational picture, hindering effective threat detection and coordinated response. This decentralized approach creates vulnerabilities and makes it difficult to share timely and actionable threat intelligence.
Many public sector entities operate smaller SOCs with limited teams. This resource constraint makes it challenging to effectively monitor complex networks, analyze the ever-increasing volume of alerts, and proactively hunt for threats. Alert fatigue and burnout are significant concerns in these environments.
Heightened risk from vendor lock-in
A crucial additional factor is that many government agencies operate in de facto vendor lock-in environments. A heavy reliance on one vendor for operating systems, productivity software, and mission-critical operations comes with greatly-increased risk.
While these tools are familiar to the workforce, their ubiquity makes them an attractive vector for phishing campaigns and vulnerability exploitation. The Department of Homeland Security’s Cyber Safety Review Board highlighted this risk and provided recommendations focused on protecting digital identity standards. Agencies should be vigilant about securing these environments and mitigating the risks associated with vendor lock-in, which can limit flexibility and increase costs in the long run.
By automating the initial triage and analysis of security alerts, agencies can better respond, predict resource allocation, and develop more accurate cybersecurity budgets. This automation can reduce the need for constant manual intervention in routine tasks, leading to more predictable operational costs and a more effective cybersecurity team.
The prevalence of legacy on-premises databases and increasingly complex multicloud infrastructure adds another layer of difficulty. Securing outdated systems alongside diverse cloud environments requires specialized skills and tools, further straining resources and potentially introducing vulnerabilities.
Addressing these multifaceted challenges requires a strategic and coordinated effort focused on standardization, robust security practices, and resource optimization.
How AI can help: Automating the future (of threat detection)
AI-based threat detection models offer a promising path toward a more resilient cybersecurity posture. By combining AI’s advanced capabilities with real-time cybersecurity intelligence and tooling, key cybersecurity workflows can be greatly streamlined.
Previously, these workflows required heavy personnel investment, such as root cause analysis, threat analysis, and vulnerability impact. As we’ve seen, AI-driven automation can provide a crucial assist in scaling for the true scope of the threat landscape, while also accelerating time-to-completion. At Google Cloud, we are seeing the benefits of AI in security today, as these three examples demonstrate.
However, achieving optimal effectiveness for government agencies requires a tailored approach.
Public sector networks often have unique configurations, legacy systems, and security-focused workflows that differ from commercial enterprises. By ingesting agency-specific data — logs, network traffic patterns, and historical incident data — AI models can learn baseline behaviors, identify deviations more accurately, reduce false positives, and improve detection rates for threats specific to public sector networks.
Adding the automation inherent in agentic AI-driven threat detection leads to better security and more sustainable operations. By automating the initial triage and analysis of security alerts, agencies can better respond, predict resource allocation, and develop more accurate cybersecurity budgets. This automation can reduce the need for constant manual intervention in routine tasks, leading to more predictable operational costs and a more effective cybersecurity team.
Ultimately, automating threat detection will maximize the capabilities of SOC staff and reduce toil so that teams can focus on the most important alerts. By offloading repetitive tasks like initial alert analysis and basic threat correlation to agentic AI, human analysts can focus on more complex investigations, proactive threat hunting, and strategic security planning. This shift can improve job satisfaction and also enhance the overall effectiveness and efficiency of the SOC.
At Google Cloud’s Office of the CISO, we’re optimistic that embracing AI can help improve threat detection even as overall budgets are reduced. Sometimes, you really can do more with less.
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0babaf3520>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
10 actionable lessons for modernizing security operations: Google Cloud’s Office of the CISO shares lessons learned from the manufacturing sector on how to modernize security operations. Read more.
Tracking the cost of quantum factoring: Our latest research updates how we characterize the size and performance of a future quantum computer that could likely break current cryptography algorithms. Read more.
How Confidential Computing lays the foundation for trusted AI: Confidential Computing has redefined how organizations can securely process their most sensitive data in the cloud. Here’s what’s new. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Fact of the month’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0babaf3af0>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://cloud.google.com/blog/topics/threat-intelligence/m-trends-2025’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
How cybercriminals weaponize fake AI-themed websites: Mandiant Threat Defense has been investigating since November an UNC6032 campaign that uses fake AI video generator websites to distribute malware. Here’s what we know. Read more.
Pwning calendars for command and control: Google Threat Intelligence Group (GTIG) has observed malware that took advantage of Google Calendar for command and control being hosted on an exploited government website, and subsequently used to attack other government websites. The activity has been attributed to APT41. Read more.
Cybercrime hardening guidance from the frontlines: The U.S. retail sector is currently being targeted in ransomware operations that GTIG suspects is linked to UNC3944, also known as Scattered Spider. UNC3944 is a financially-motivated threat actor characterized by its persistent use of social engineering and brazen communications with victims. Here’s our latest proactive hardening recommendations to combat their threat activities. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
Betting on the future of security operations with AI-native MDR: What does AI-first managed detection and response get right? What does it miss? How does it compare to traditional security operations? Tenex.AI’s Eric Foster and Venkata Koppaka join hosts Anton Chuvakin and Tim Peacock for a lively discussion about the future of MDR Listen here.
AI supply chain security: Old lessons, new poisons, and agentic dreams: How does the AI supply chain differ from other software supply chains? Can agentic AI secure itself? Christine Sizemore, Google Cloud security architect connects the supply-chain links with Anton and Tim. Listen here.
What we learned at RSAC 2025: Anton and Tim discuss their RSA Conference experiences this year. How did the show floor hold up to the complicated reality of today’s information security landscape? Listen here.
How boards can address AI risk: Christian Karam, strategic advisor and investor, joins Office of the CISO’s Alicja Cade and David Homovich to chat about the important role that board can play in addressing AI-driven risks. Listen here.
Defender’s Advantage: Confronting a North Korean IT worker incident: Mandiant Consulting’s J.P. Glab joins host Luke McNamara to walk through North Korean IT worker activity — and how Mandiant responds. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
In today’s rapidly evolving technological landscape, artificial intelligence (AI) stands as a transformative force, reshaping industries and redefining possibilities. Recognizing AI’s potential and leveraging its data landscape on Google Cloud, Magyar Telekom, Deutsche Telekom’s Hungarian operator, embarked on a journey to empower its workforce with AI knowledge and tools. This endeavor led to the creation of Pluto AI — an internal AI platform that has grown into a comprehensive framework for diverse AI solutions.
As one of Hungary’s largest telecommunications operators, Magyar Telekom’s ultimate vision is to embed AI into every aspect of its operations, empowering every employee to leverage AI’s potential. Pluto AI is a significant step toward achieving this goal, fostering a culture of innovation and data-driven decision-making.
Magyar Telekom’s leadership recognized that AI proficiency is now essential for future success. However, the company faced challenges, including employees with varying levels of AI understanding and a lack of accessible tools for experimentation and practical application. As a result, Magyar Telekom aimed to democratize AI knowledge and foster a culture of experimentation by building a scalable solution that could adapt to its evolving AI needs and support a wide range of use cases.
To enable business teams across Magyar Telekom to utilize generative AI, the Pluto AI team developed a simple tool that provided a safe and compliant way to prompt large language models (LLMs). They also created educational content and training for business teams on how to use gen AI and what opportunities it brings. This approach provided other teams with the building blocks to quickly construct the AI solutions they needed.
With Pluto AI, Magyar Telekom spearheaded the successful adoption of gen AI across the company, quickly expanding the platform to support additional use cases without the need for the central platform team to have a deep understanding of them.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0bae7034f0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Developing Pluto AI
Magyar Telekom’s AI Team partnered with Google Cloud Consulting to accelerate the development of Pluto AI. This collaboration ensured that the platform was built on best practices, aligned with industry standards, and met security and compliance requirements of a regulated industry.
Here are some of the key features and functionality of Pluto AI:
1. Modular framework
Pluto AI’s modular architecture allows teams to seamlessly integrate, change, and update various AI models, tools and various architectural patterns. This flexibility enables the platform to cater to a wide range of use cases and rapidly evolve alongside Magyar Telekom’s AI strategy.
The core modules of Pluto AI include:
Large language models: Pluto AI integrates with state-of-the-art LLMs, enabling natural language understanding, text and image generation, and conversational AI applications.
Code generation and assistance: The platform supports code generation, autocompletion, and debugging, boosting developer productivity and code quality. Pluto AI provides both a coding model, accessible via its user interface, for all development levels and IDE integration for experienced coders.
API: Pluto AI’s models can be called via API, enabling all parts of Magyar Telekom to utilize and integrate AI capabilities into their existing and new solutions.
Retrieval augmented generation (RAG) with grounding capabilities: RAG combines LLMs with internal knowledge sources, including multimodal content like images and videos. This enables teams to build AI assistants that can access and synthesize information from vast datasets and add evidence like extended citations from both corporate and public data to their responses.
Customizable AI assistants: Users can create tailored, personalized AI assistants by defining system prompts, uploading documents, and fine-tuning model behavior to meet their business needs.
2. Technical implementation
Pluto AI runs on Compute Engine using virtual machines, providing scalability, reliability, and efficient resource management. The platform also utilizes foundation models from the Model Garden on Vertex AI, including Google’s Gemini, Imagen, and Veo models, Anthropic’s Claude 3.5 Sonnet, and more. Magyar Telekom also deployed ElasticSearch on Google Cloudto store the knowledge bases necessary for enabling RAG workflows.
In addition to these core components, Pluto AI also utilizes other Google Cloud services to help develop production-ready applications, such as Cloud Logging, Pub/Sub, Cloud Storage, Firestore, and Looker.
3. User interface and experience
Pluto AI’s intuitive interface makes AI tools accessible to users with varying technical expertise. A dropdown menu allows users to easily navigate between different modules and functionalities. The platform’s design prioritizes user experience, ensuring that employees can leverage AI capabilities without a steep learning curve.
Impact and adoption
Pluto AI has seen impressive adoption rates, with hundreds of daily active users across different departments. The platform’s user-friendly design and practical applications have garnered positive feedback from Magyar Telekom employees.
In addition, Pluto AI has enabled the development of various AI assistants, including legal and compliance assistants that accelerate contract review, identify compliance risks, and analyze legal documents. Knowledge management assistants have enhanced knowledge sharing and retrieval across the organization, while software development has benefited from code generation and assistance tools. Additionally, AI-powered chatbots that handle routine inquiries have significantly improved customer support experiences.
Magyar Telekom has seen quantifiable results since rolling out Pluto AI. These include hundreds of daily unique users, tens of thousands of API calls, an estimated 20% reduction in the time spent reviewing legal documents, and a 15% decrease in code defects.
Vision and future roadmap for Pluto AI
Magyar Telekom sees Pluto AI as a key part of its AI strategy going forward. To maximize its impact, the company intends to expand the platform to more markets, business units, and departments within the organization. Additionally, Magyar Telekom is looking into the possibility of offering Pluto AI as a service or a product to other Deutsche Telekom markets. The company is also planning to build a library of reusable AI modules and frameworks that can be easily adapted to different use cases.
Magyar Telekom is pursuing several key initiatives to enhance Pluto AI and expand its capabilities. These efforts include investigating the potential of agent-based AI systems to automate complex tasks and workflows, adding a language selector for multilingual support to cater to a diverse user base, and developing an enhanced interface for managing RAG solutions, monitoring usage, and tracking performance metrics. Magyar Telecom also plans to continue developing dashboards for monitoring and optimizing cloud resource usage and costs.
Pluto AI has transformed Magyar Telekom’s AI landscape, making AI accessible, practical, and impactful. By providing a user-friendly platform, fostering experimentation, and delivering tangible business value, Pluto AI has set a new standard for internal AI adoption.
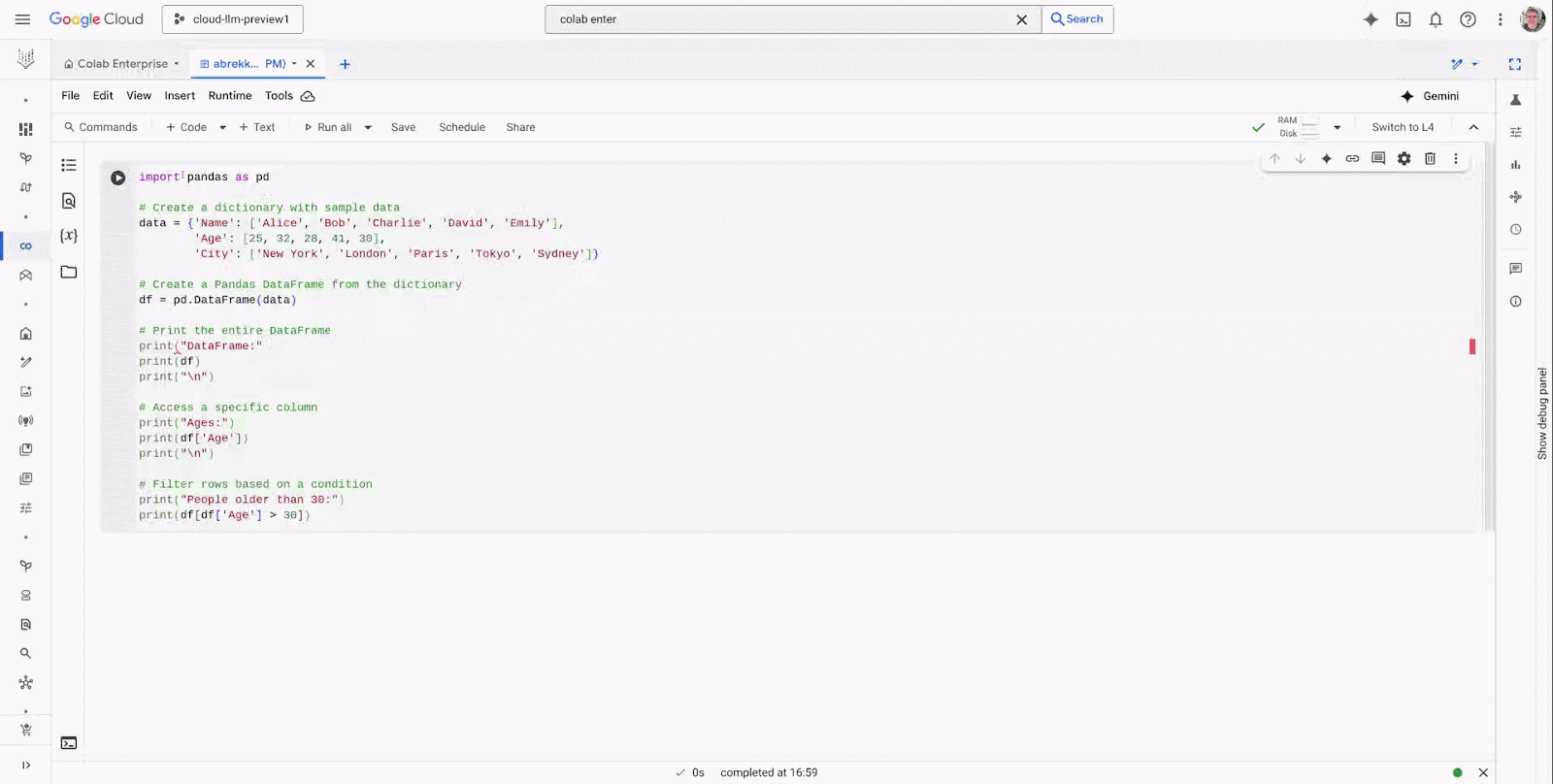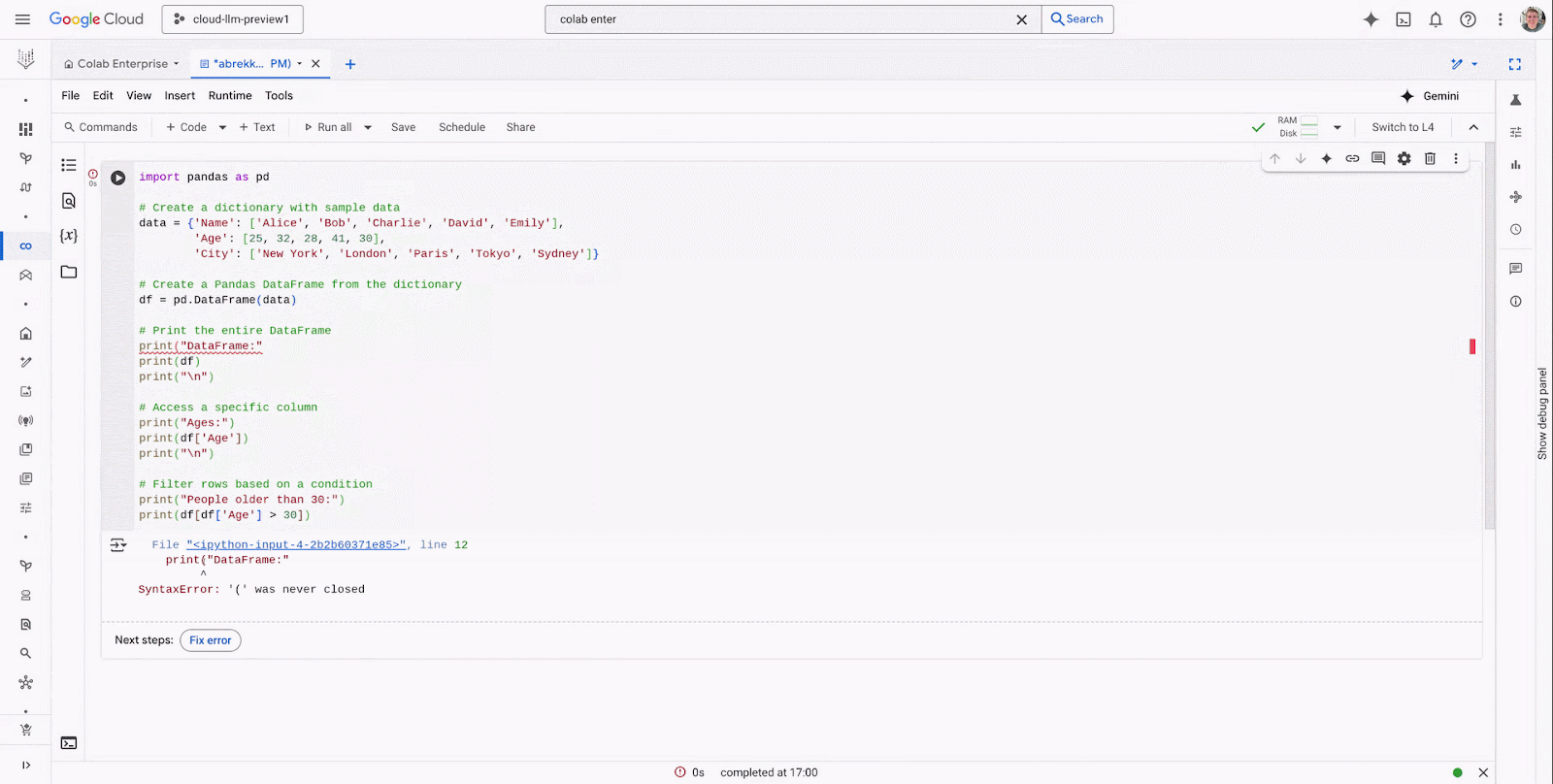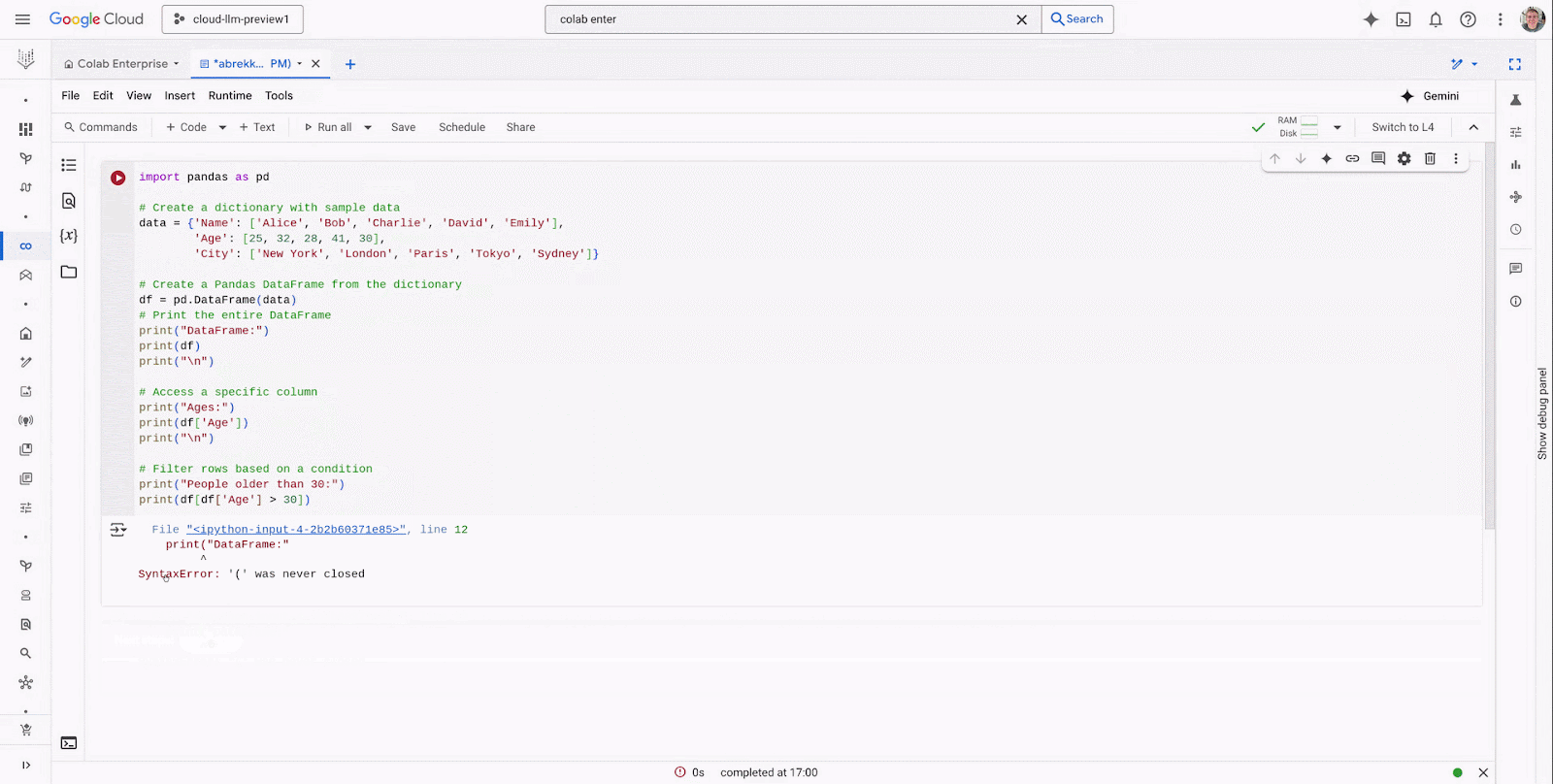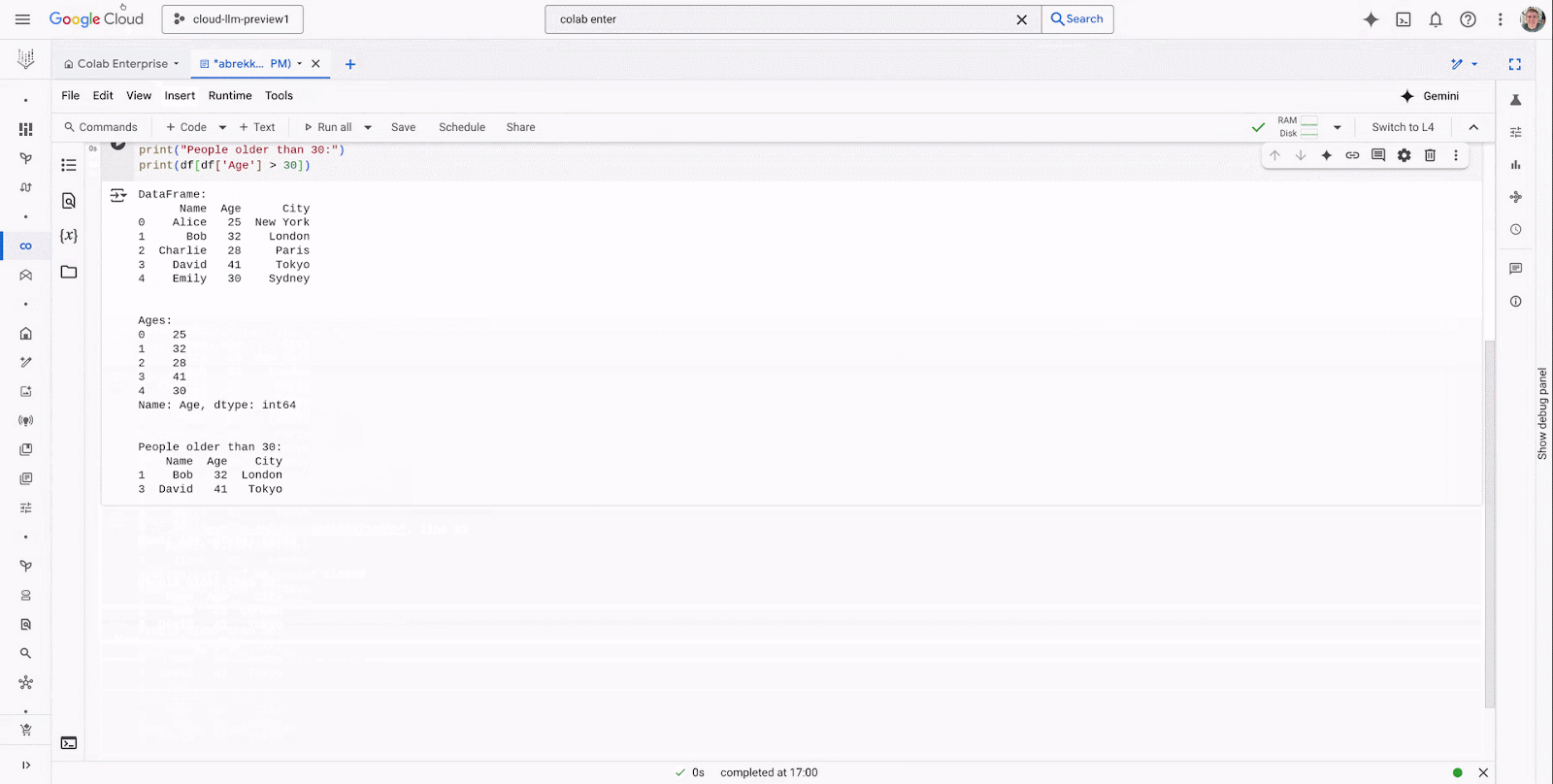
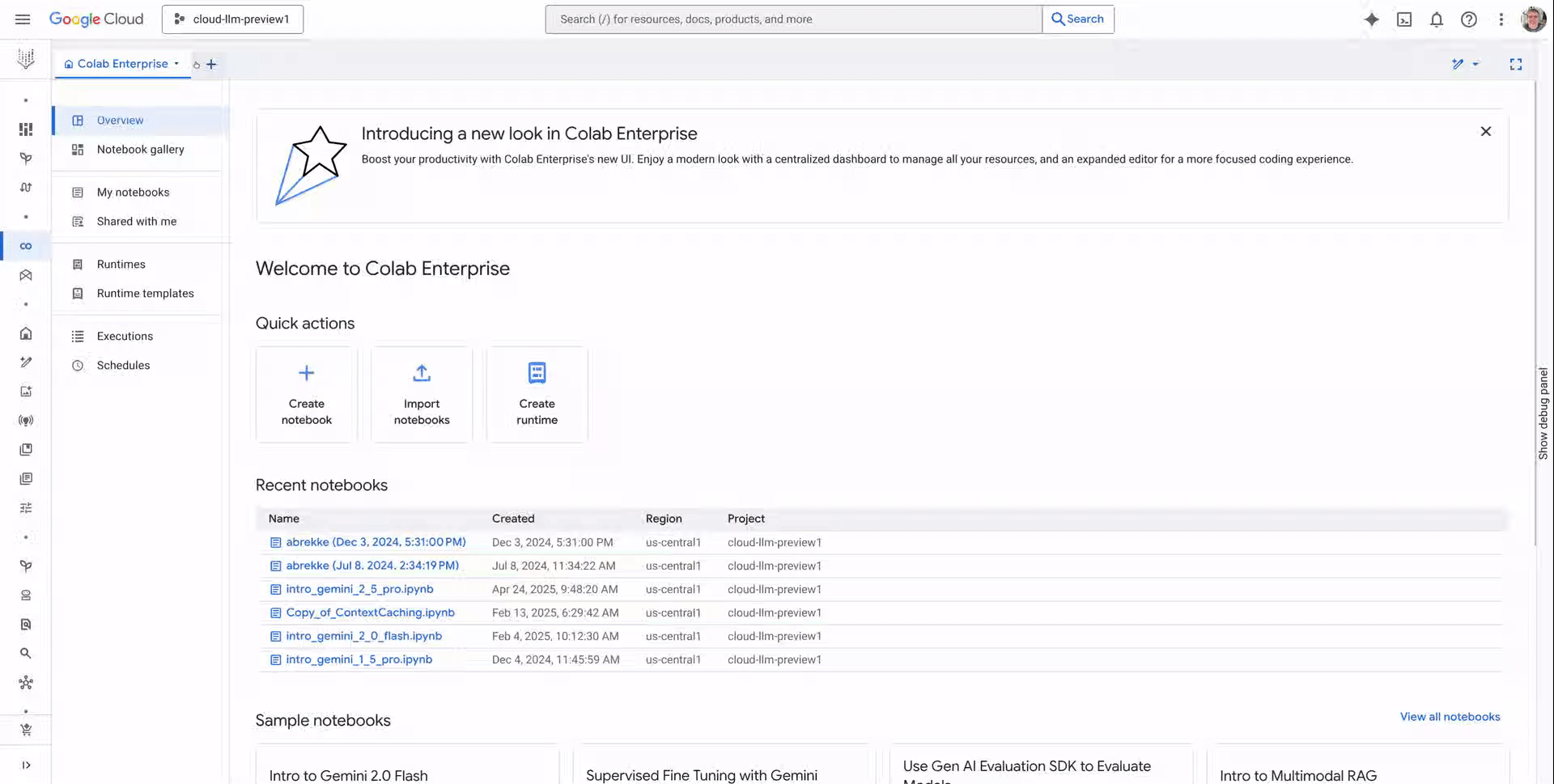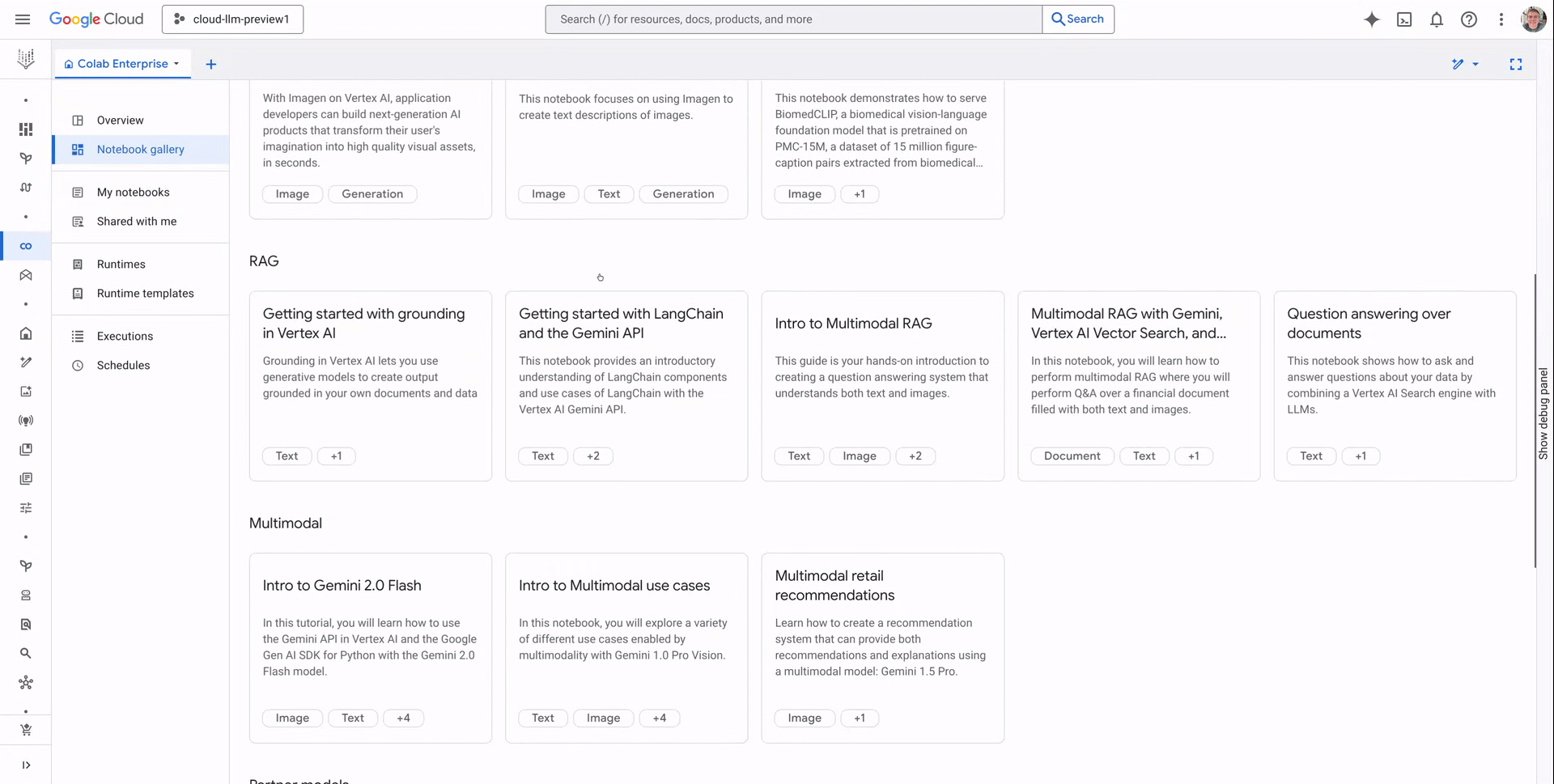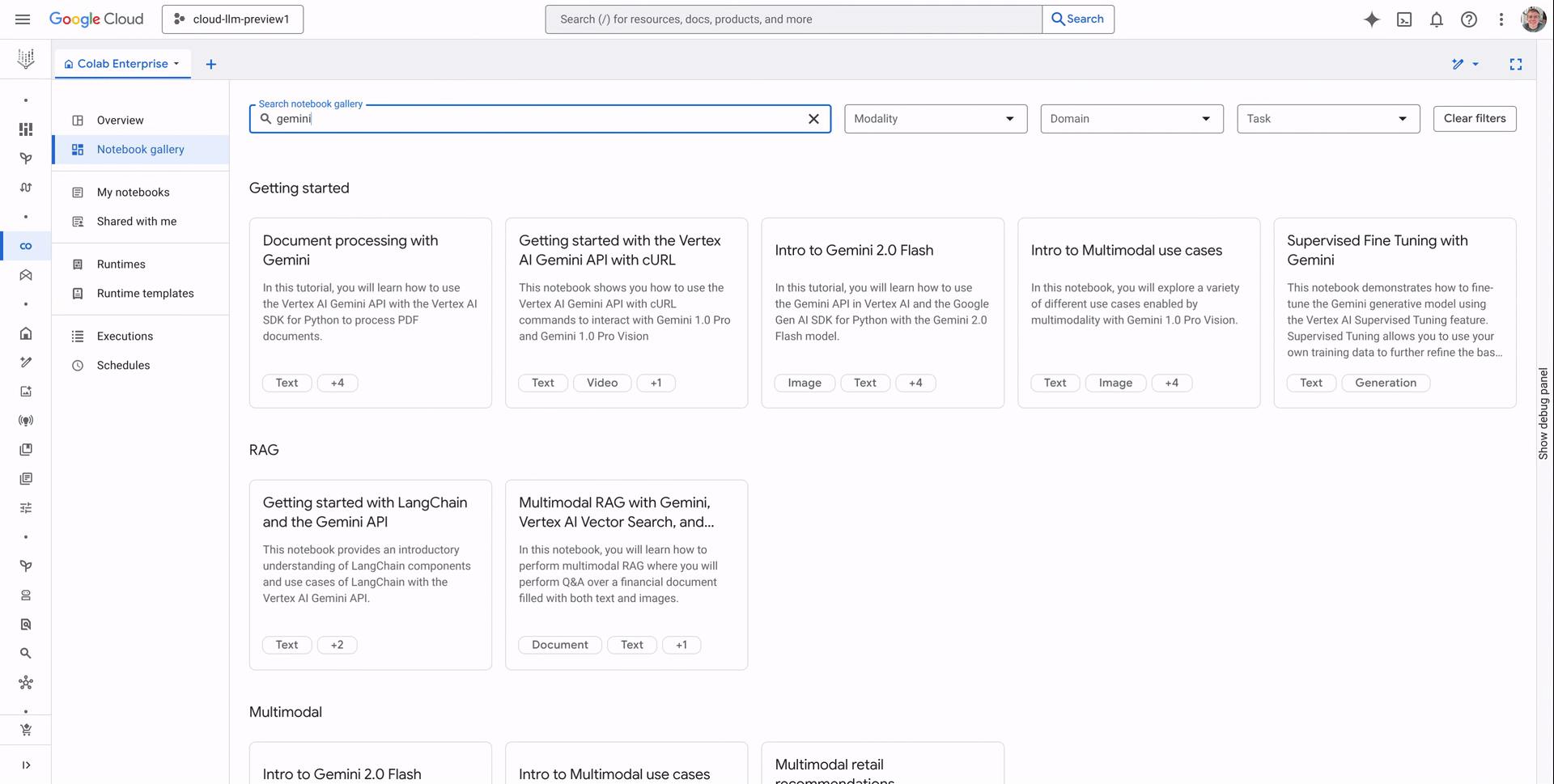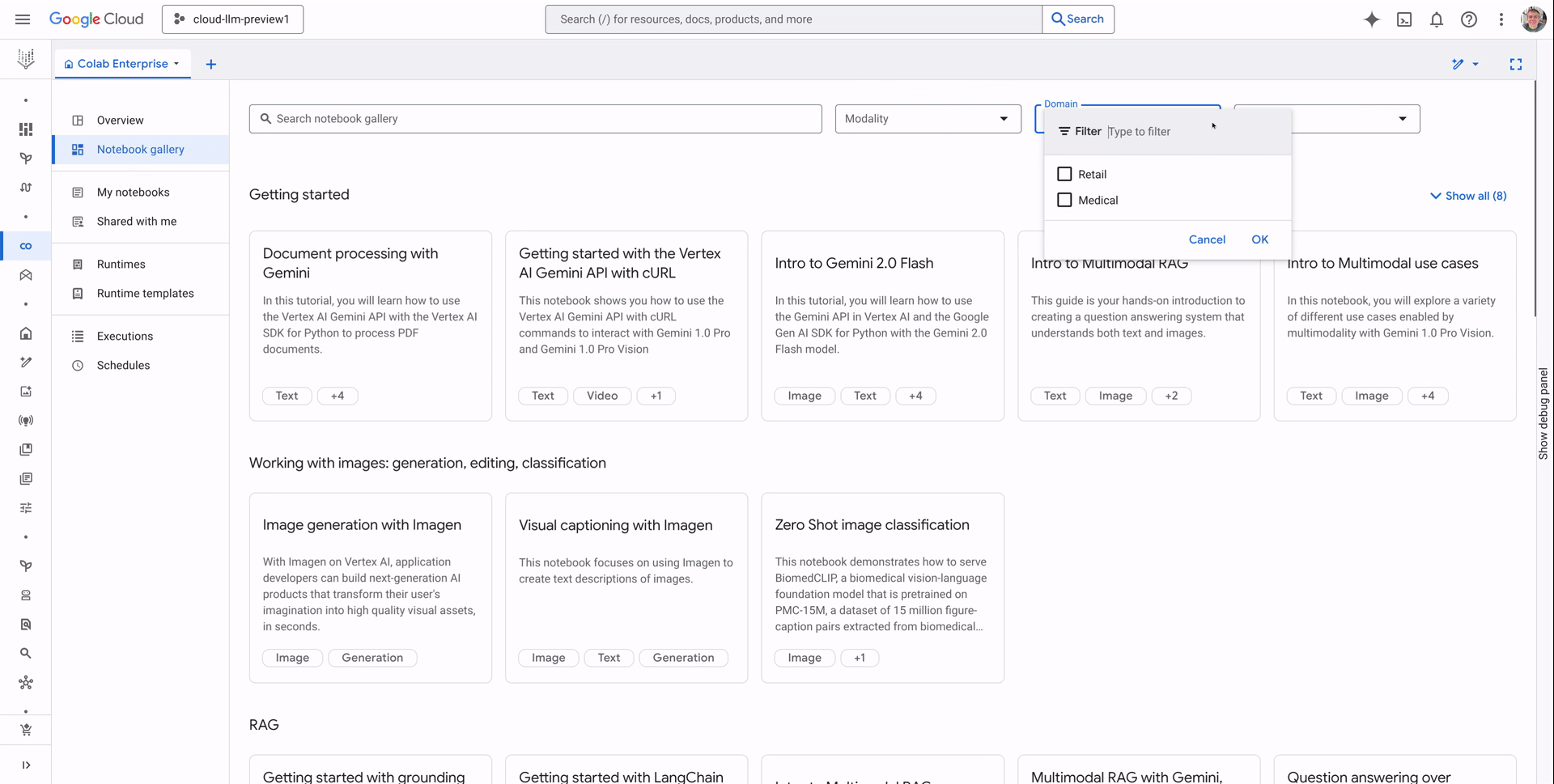
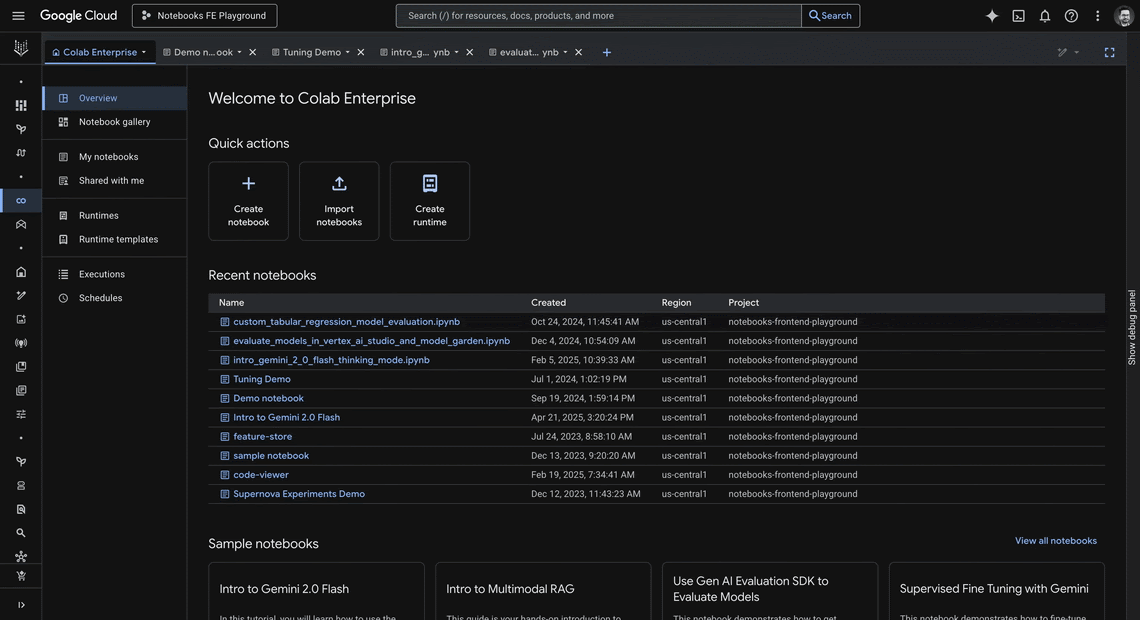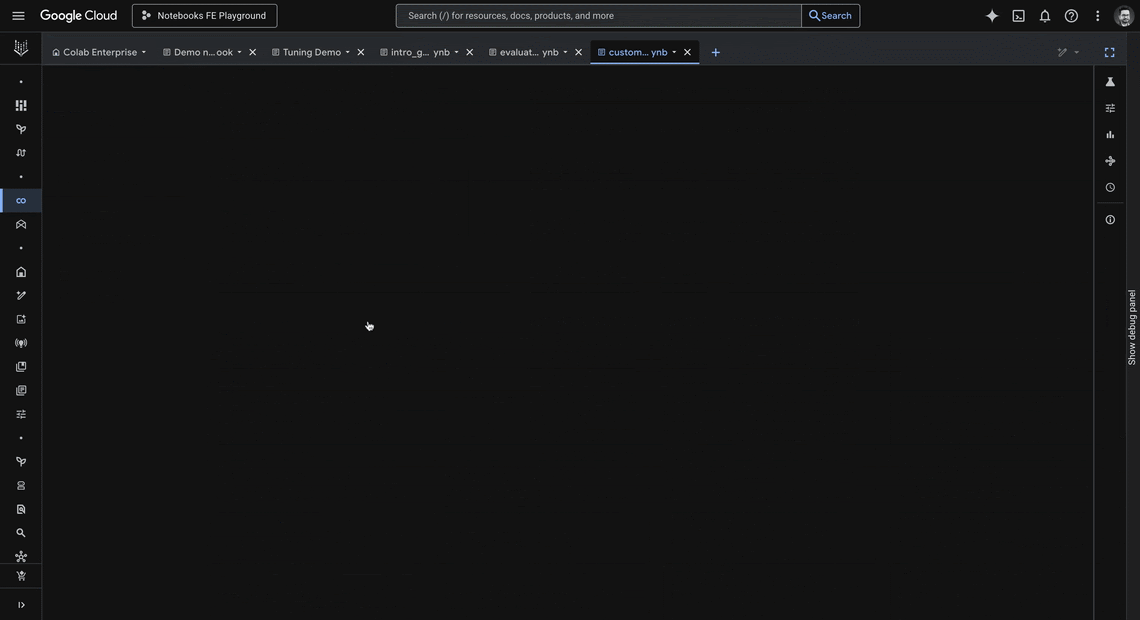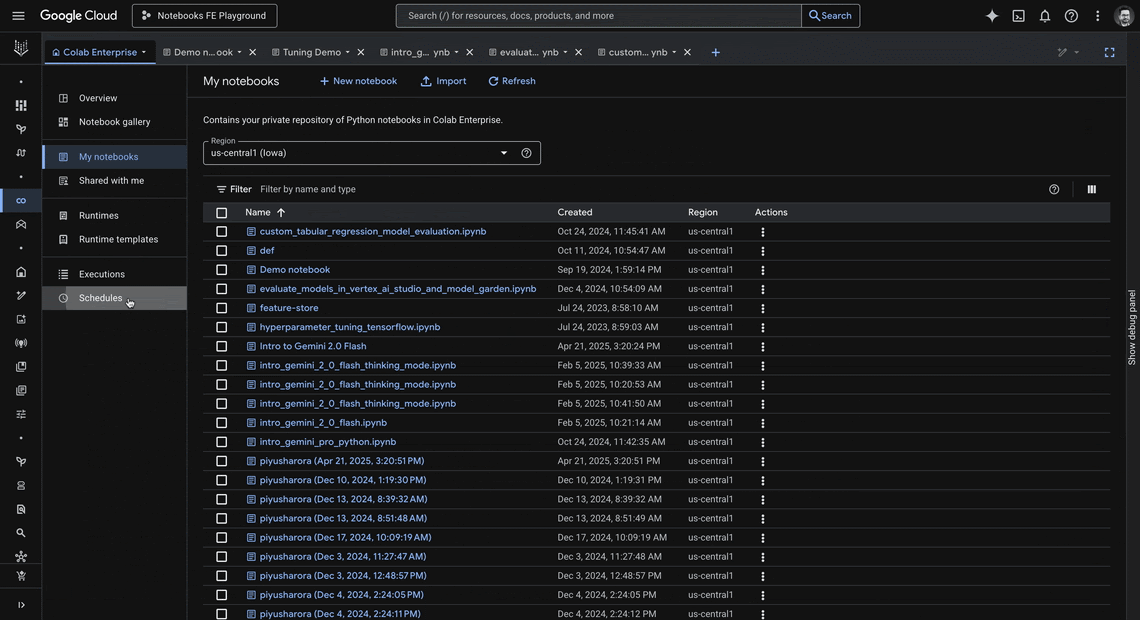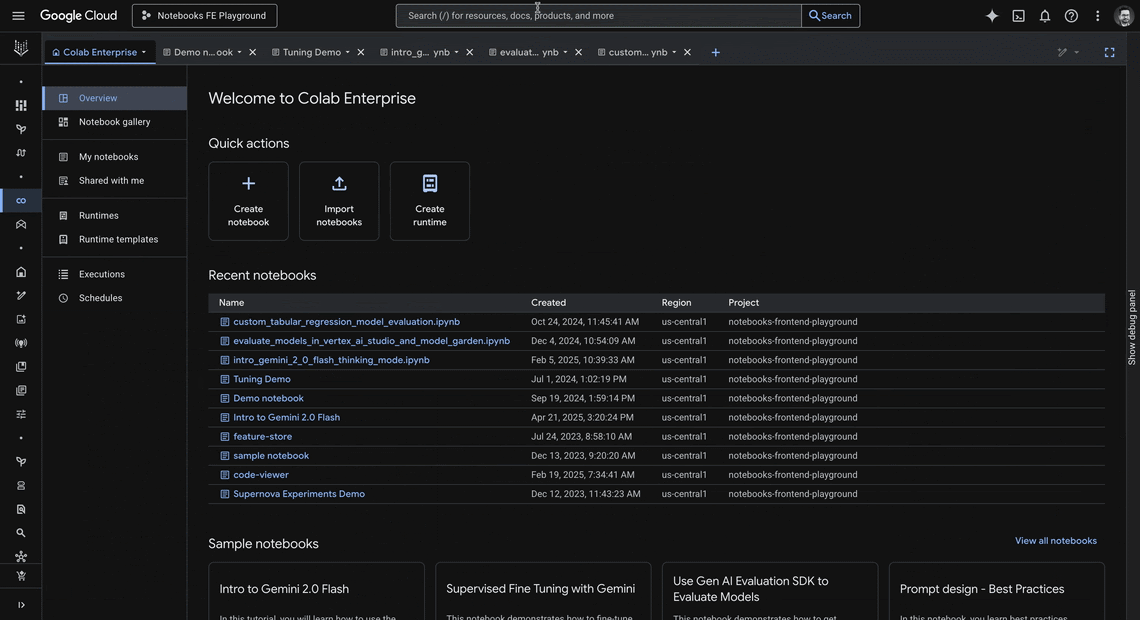
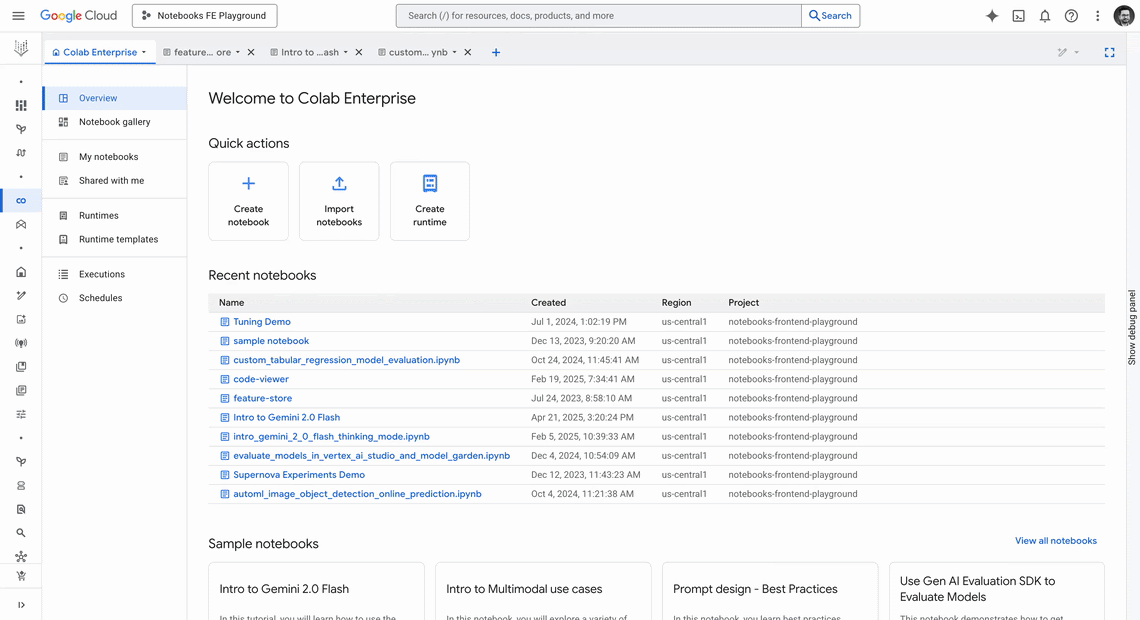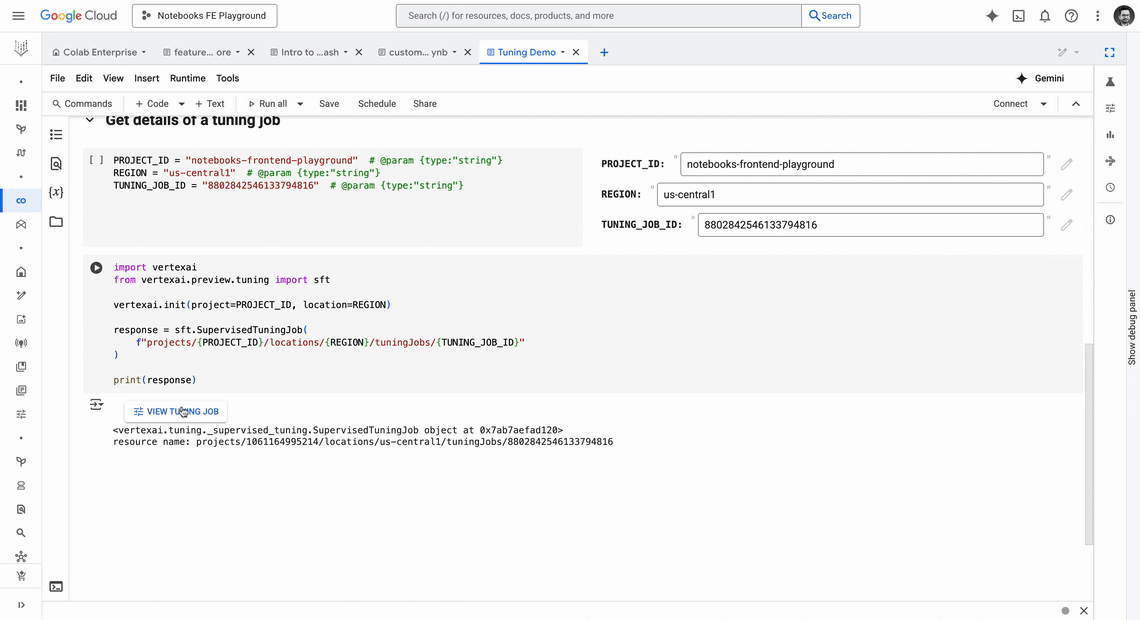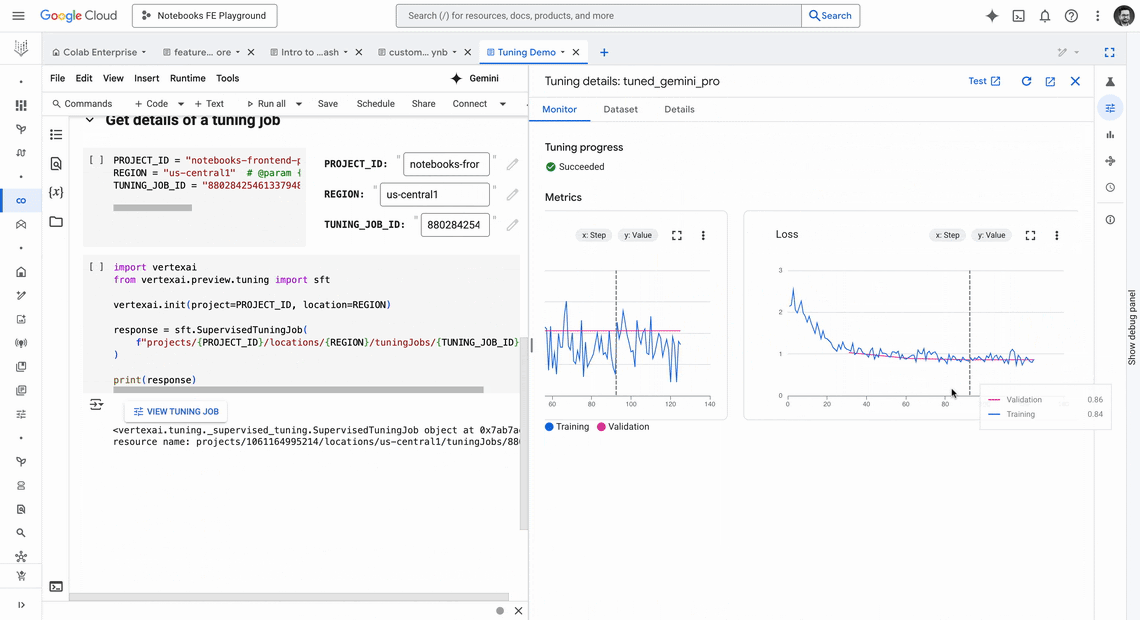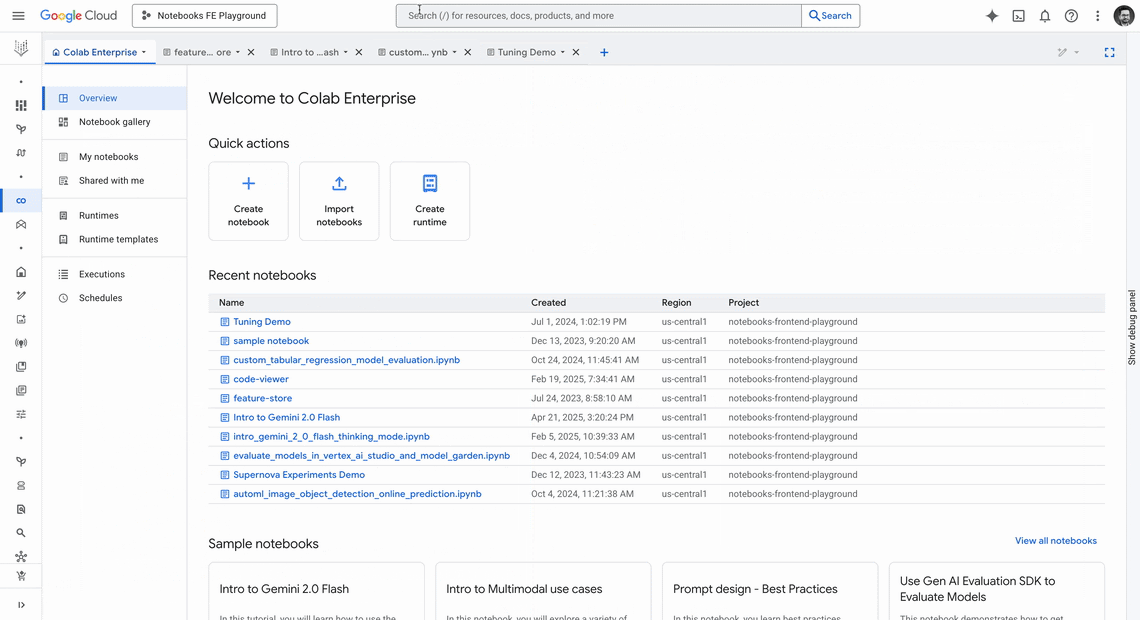
Colab Enterprise is a collaborative, managed notebook environment with the security and compliance capabilities of Google Cloud. Powerful integrated AI, seamless collaboration tools, enterprise readiness, and zero-config flexible compute are some of the many features making Colab Enterprise a trusted tool for developers at companies of all sizes.
Today, we’re excited to announce new productivity boosting capabilities in Colab Enterprise, including:
Code assistance powered by Gemini to improve code development
A Notebook gallery that helps you find sample notebooks to jumpstart your workflows
A UX redesign to improve the editor experience and asset organization
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0bacffd9d0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Gemini in Colab Enterprise
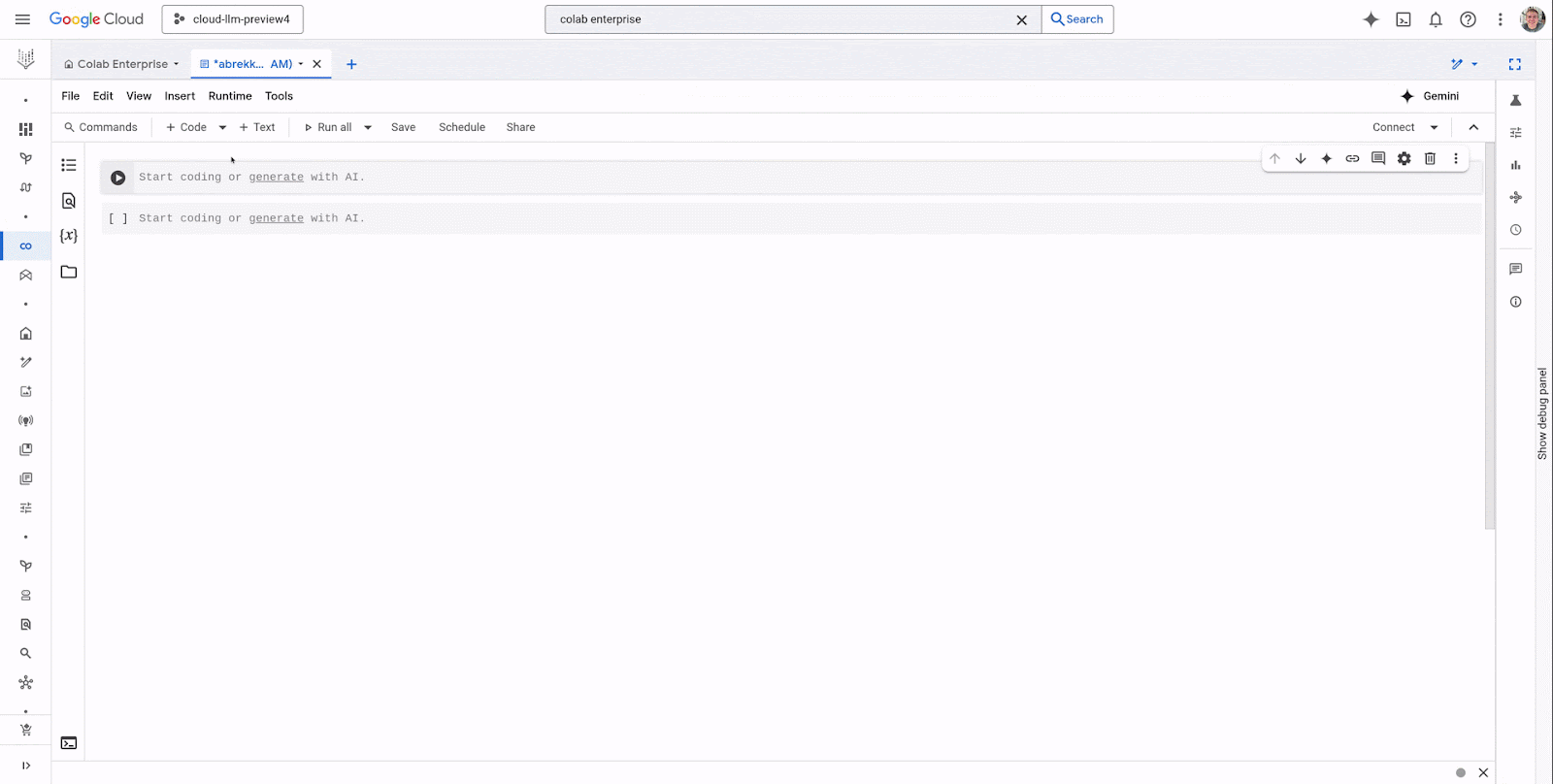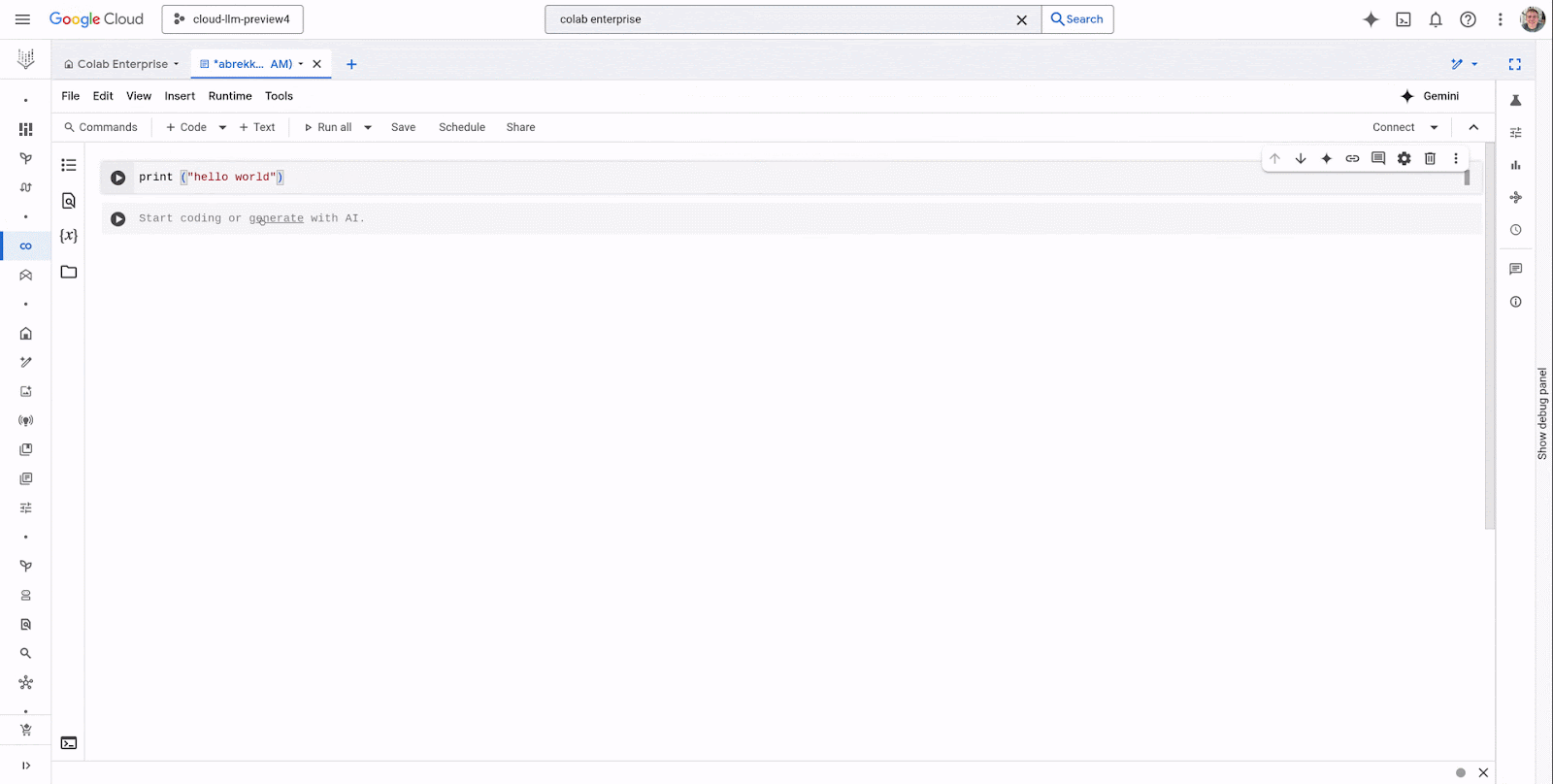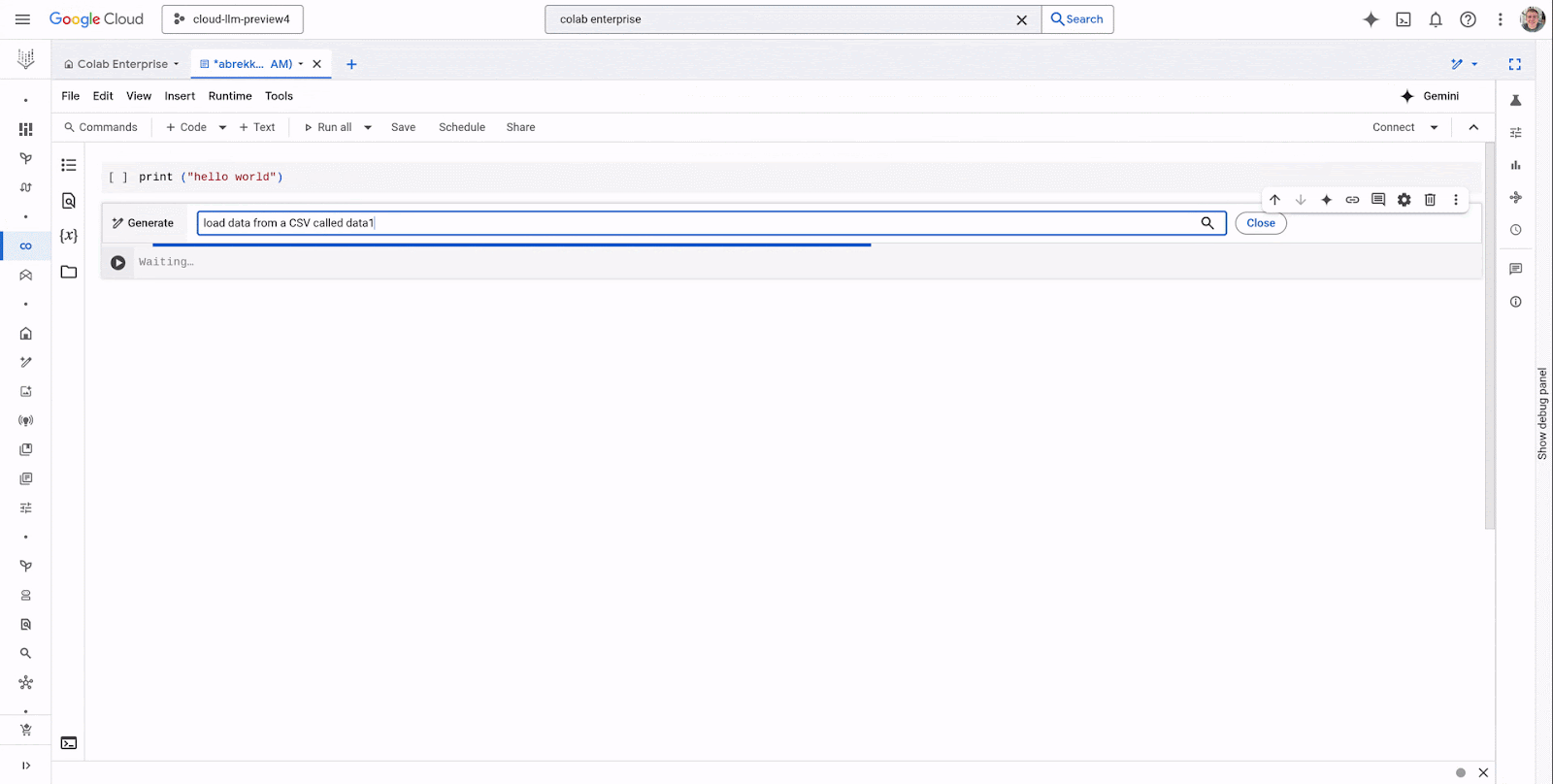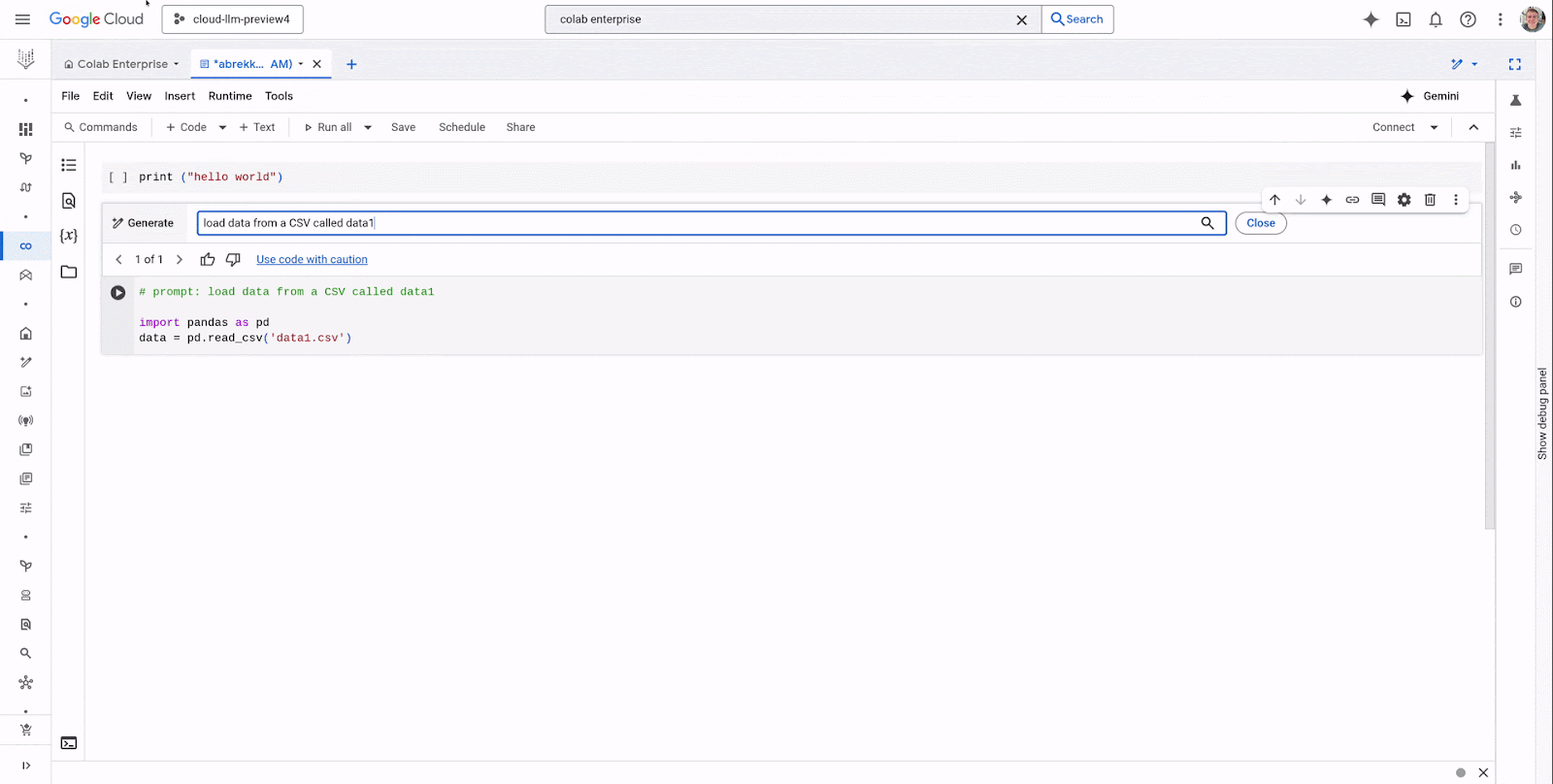
The latest version of Gemini, Google’s largest and most capable AI model, is now directly available in Colab Enterprise. With this integration, users can now use AI to assist with code completion and generation, increasing their productivity and decreasing time to value:
Code completion: With Code completion, customers can now start coding in their notebook and receive suggestions about potential ways to complete their code.
Code generation: With Code generation, customers can use Gemini to generate code for them based on a prompt.
Explain error: With Explain Error, customers can get an explanation of why errors occurred, giving information that’s helpful in debugging.
Fix error: With Fix Error, customers can ask for help to fix errors in your code so that you don’t have to consult external sources.
Sample Notebook Gallery
The Notebook gallery offers a one-stop shop to effortlessly discover, search, and build off of sample notebooks. These samples, code snippets, and getting started guides provide a practical, hands-on approach to learning new techniques, understanding best practices, and jumpstarting projects with ready-to-use templates and examples.
Notebook categories
Notebooks in the gallery are organized by categories including “Getting Started”, “Partner Models”, and “RAG” making it easy to find relevant samples to build off of and accelerate your workflows. Use the dropdown arrows to explore notebooks within each category, and simply click to open.
Notebook tags and metadata
See detailed information about sample notebooks before opening them, including a short description of the notebook’s contents, what modalities the notebook covers (e.g. text, image, video), and which AI models are used.
Search
Use the gallery search bar to find sample notebooks using freeform text. Search based on keywords such as the name of the notebook or any of the listed metadata like type of model, and modality.
A UX refresh
We’ve redesigned Colab Enterprise to improve developer productivity. You can now access a new centralized dashboard to manage all your assets, an expanded editor for a more focused coding experience, a new dark mode, and integrations with other Vertex AI services such as Experiments, Model Evaluations, Tuning, Scheduler and Ray.
The new centralized dashboard which includes:
Your private and shared notebooks
Runtimes, templates, executions, and schedules
A sample notebook gallery.
The new dark mode in Colab Enterprise boosts developer productivity by creating a more comfortable coding environment that minimizes eye fatigue during extended work periods.
We’ve also enhanced the core editor experience, which now includes:
Expanded editor real estate, giving you more room to focus on what matters most: – writing code.
A deeply integrated editor with MLOps tooling, so you can access your experiments, see model evaluation results, connect to Ray clusters, schedule a notebook run and much more, all accessible in a single MLOps panel.
An easily accessible File menu system to find all the quick actions related to your notebook file and the editor.
A stateful UI, so you can browse all your assets on the dashboard without losing all your open notebooks.
Get started today
Check these features out in Vertex AI Colab Enterprise today (console, documentation).
The AI era has supercharged expectations: users now issue more complex queries and demand pinpoint results, meaning there’s an 82% chance of losing a customer if they can’t quickly find what they need. Similarly, AI agents require ultra-relevant context for reliable task execution. However, when traditional search methods deliver noise – with generally up to 70% of retrieved passages lacking a true answer – both agentic workflows and user experiences suffer from untrustworthy and unreliable results.
To help businesses meet these rising expectations, we’re launching our new state-of-the-art Vertex AI Ranking API. It makes it easy to boost the precision of information surfaced within search, agentic workflows, and retrieval-augmented generation (RAG) systems. This means you can elevate your legacy search system and AI application in minutes, not months.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0bae7740a0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Go beyond simple retrieval
This is where precise ranking becomes essential. Think of the Vertex AI Ranking API as the precision filter at the crucial final stage of your retrieval pipeline. It intelligently sifts through the initial candidate set, identifying and elevating only the most pertinent information. This refinement step is key to unlocking higher quality, more trustworthy, and more efficient AI applications.
Vertex AI Ranking API acts as this powerful, yet easy-to-integrate, refinement layer. It takes the candidate list from your existing search or retrieval system and re-orders it based on deep semantic understanding, ensuring the best results rise to the top. Here’s how it helps you uplevel your systems:
Upgrade legacy search systems: Easily add state-of-the-art relevance scoring to existing search outputs, improving user satisfaction and business outcomes on commercial searches without overhauling your current stack.
Strengthen RAG systems: Send fewer, more relevant documents to your generative models. This improves answer trustworthiness while reducing latency and operating costs by optimizing context window usage.
Support intelligent agents: Guide AI agents with highly relevant information, streamlining their context and traces, and significantly improving the success rate of task completion.
Figure 1: Ranking API usage in a typical search and retrieval flow
What’s new in Ranking API
Today, we’re launching our new semantic reranker models:
semantic-ranker-default-004 – our most accurate model for any use case
semantic-ranker-fast-004 – our fastest model for latency-critical use cases
Our model establishing a new benchmark for ranking performance:
State-of-the-art ranking: Based on evaluations using the industry-standard BEIR dataset, our model leads in accuracy among competitive standalone reranking API services. The nDCG is a metric that’s used to evaluate the quality of a ranking system by assessing how well ranked items align with their actual relevance and prioritizes relevant results at the top. We’ve published our evaluation scripts to ensure reproducibility of results.
Figure 2: semantic-ranker-default-004 leads in NDCG@5 on BEIR datasets compared to other rankers.
Industry-leading low latency: Our default model (semantic-ranker-default-004) is at least 2x faster than competitive reranking API services at any scale. Our fast model (semantic-ranker-fast-004) is tuned for latency-critical applications and typically exhibits 3x lower latency than our default model.
We’re also launching long context ranking with a limit of 200k total tokens per API request. Providing longer documents to the Ranking API allows it to better understand nuanced relationships between queries and information such as for customer reviews or product specifications in Retail.
Real-world impact across domains
The benefits aren’t just theoretical. Benchmarks on industry-specific datasets demonstrate that integrating the Ranking API can significantly boost the quality of search results across diverse high-value domains such as retail, news, finance, and healthcare.
Figure 3: nDCG@5 performance improvement with semantic-ranker-default-004 in various high-value domains based on internal datasets. Lexical & Semantic search baseline uses the best result of Vertex AI text-embedding-004 and BM25 based retrieval.
Elevate your search results in minutes
We designed the Vertex AI Ranking API for seamless integration. Adding this powerful relevance layer is straightforward, with several options:
Try it live: Experience the difference on real-world data by enabling our Ranking API in the interactive Vertex Vector Search demo (link)
Build with Vertex AI: Integrate directly into any existing system for maximum flexibility (link)
Enable it in RAG Engine: Select Ranking API in your RAG Engine to get more robust and accurate answers from your generative AI applications (link)
Use it in AlloyDB: For a truly streamlined experience, leverage the built-in ai.rank() SQL function directly within AlloyDB – a novel integration simplifying search use cases with AlloyDB (link)
AI Frameworks: Use our native integrations with popular AI frameworks like GenKit and LangChain (link)
Use it in Elasticsearch: Quickly boost accuracy with our built-in Ranking API integration in Elasticsearch (link)