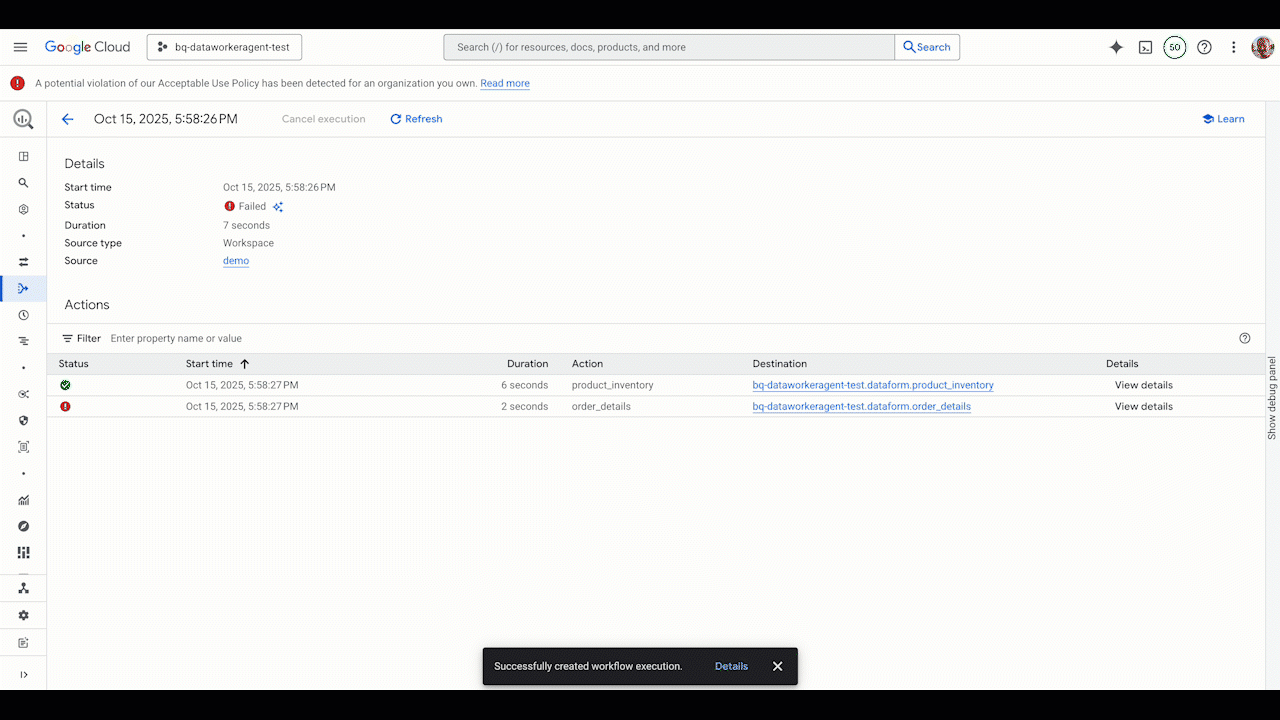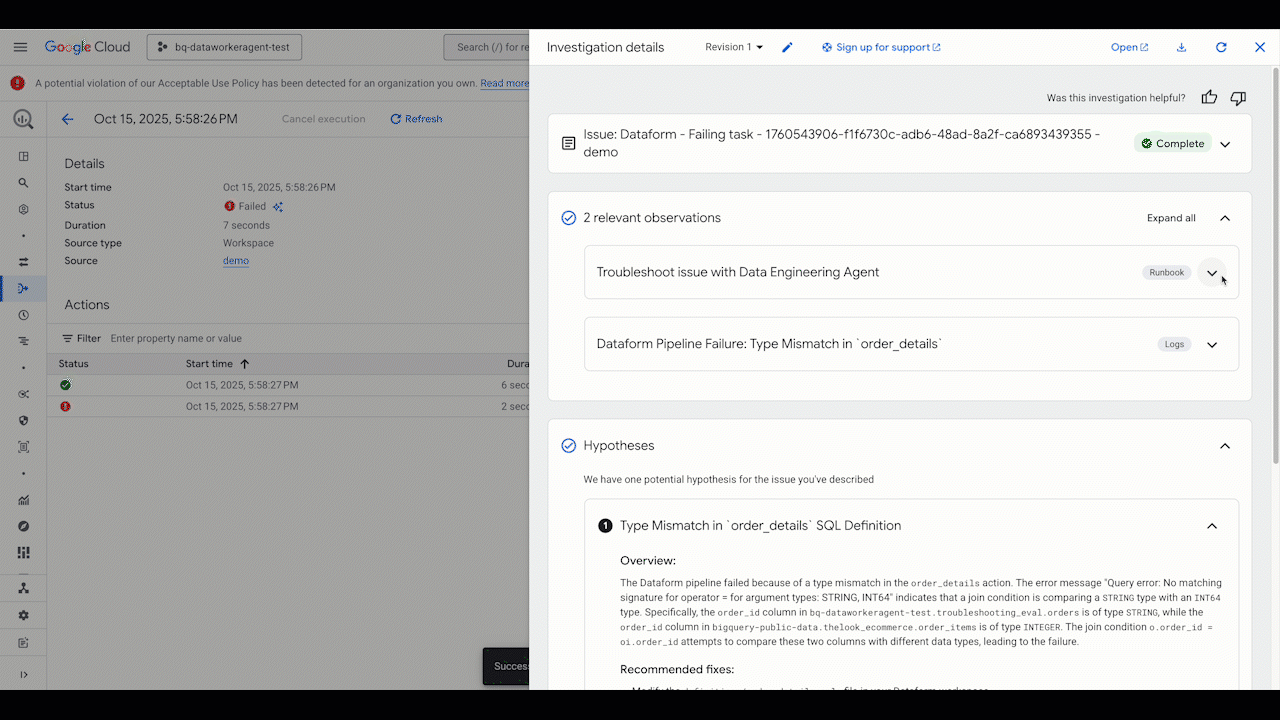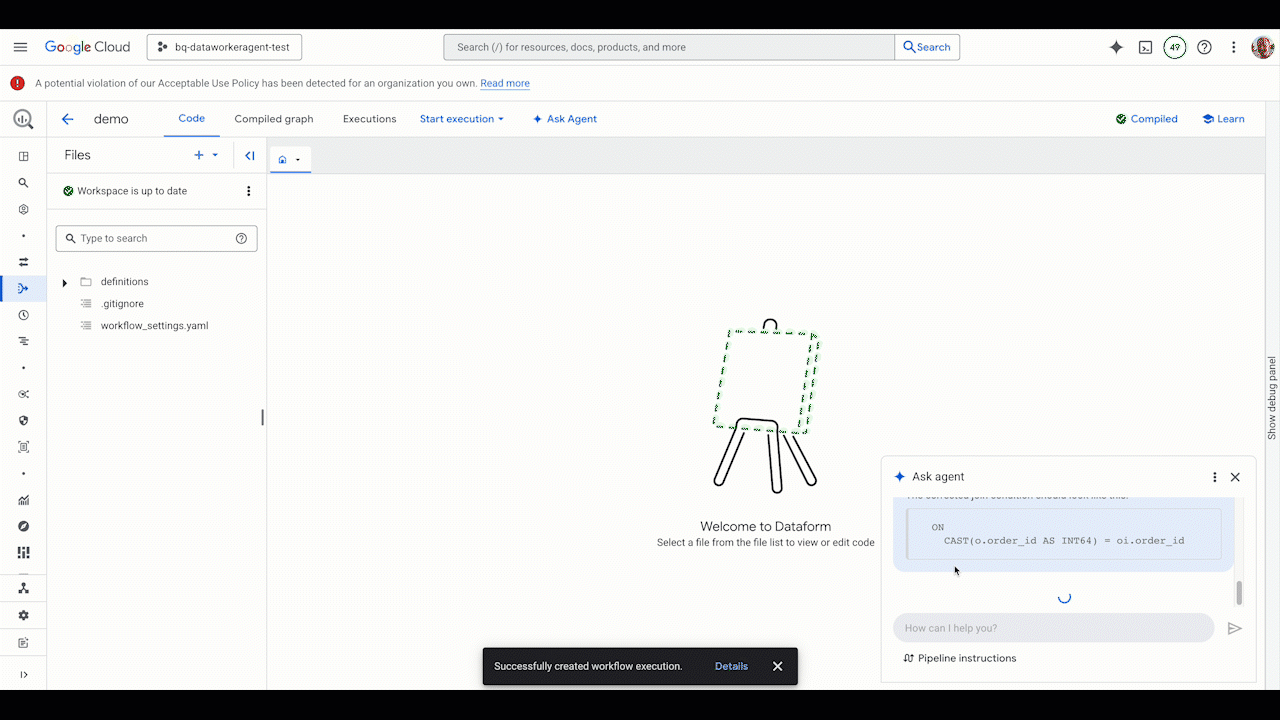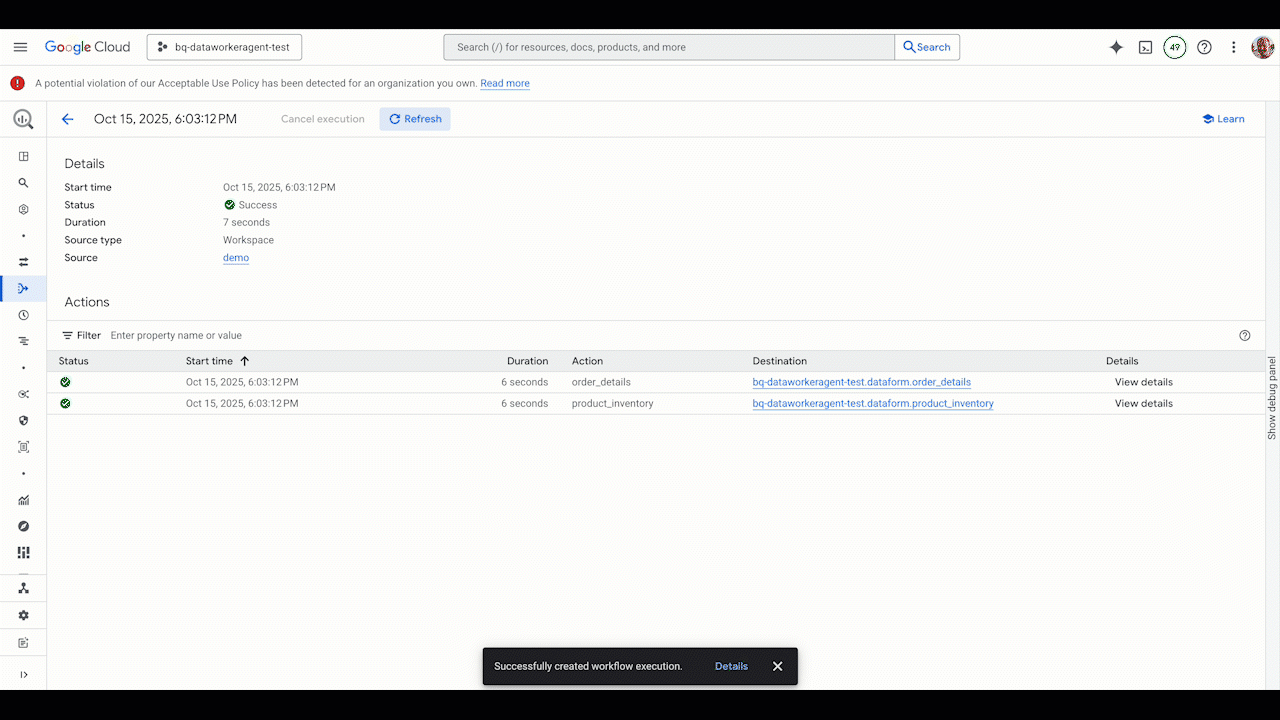
Artificial intelligence is reshaping our world – accelerating discovery, optimising systems, and unlocking new possibilities across every sector. But with its vast potential comes a shared responsibility.
AI can be a powerful ally for transforming businesses and reducing cost. It can help organizations minimize carbon emissions, industries manage energy use, and scientists model complex climate systems in real time. Yet the way we design, deploy, and run AI also matters. Building software sustainably means making every stage of the digital journey – from architecture to inference – more efficient, transparent, and resilient.
Innovation that serves sustainability
At Google, we believe innovation and sustainability go hand in hand. The same intelligence that powers breakthroughs can also help us use resources more wisely.
Projects like Green Light, which uses AI to optimise traffic signals and reduce emissions, and Project Contrails, which helps airlines cut the warming effects of condensation trails, show what happens when technology serves both performance and planet.
Each example reveals a helpful truth – that sustainability doesn’t slow innovation but instead fuels it, enabling efficiency to become an engine of progress.
From footprint to framework
Every software system, including AI, has an environmental footprint – from the hardware and energy that powers data centers to the water used to cool them. Water is one of the planet’s most precious and increasingly scarce resources and protecting it must be part of any technology strategy. That’s why Google is investing in advanced cooling systems and water stewardship projects with the goal to replenish more than we consume, helping preserve local ecosystems and community supplies.
Understanding this footprint helps engineers and organisations make smarter choices, like selecting efficient accelerators, rightsizing workloads, and scheduling operations when the grid is cleanest.
Across Google Cloud, we’re continually improving efficiency. Our Ironwood Tensor Processing Units (TPUs) are nearly 30 times more energy-efficient than our first Cloud TPU from 2018, and our data centres operate at a fleet-wide Power Usage Effectiveness (PUE) of 1.09, which is amongst the best in the world.
By designing systems that consume less energy and run on more carbon-free power, we help close the gap between ambition and action – turning digital progress into tangible emissions reductions.
But this isn’t achieved through infrastructure alone. It’s the result of decisions made at every layer of the software lifecycle. That’s why we encourage teams to think Sustainable by Design, bringing efficiency, measurement, and responsibility into every stage of building software.
Sustainable by Design: a mindset for the AI era
Today’s sustainability questions aren’t coming just from sustainability teams; they are coming directly from executives, financial operations teams, technology leads and developers. And they are often asking sustainability questions using infrastructure language: “Are we building the most price-performant AND efficient way to run AI?” This is not a niche environmental question; it’s relevant across -industries, across-geo’s and it requires that leaders consider sustainability criteria when they are designing infrastructure. A Sustainable by Design infrastructure strategy makes AI training and operation dramatically more cost- and energy-efficient. It’s built around a set of principles known as the 4Ms which lay out powerful ways to embed efficiency into software:
Machine – choose efficient computing resources that deliver more performance per watt.
Model – use or adapt existing models rather than starting from scratch — smaller, fine-tuned models can be faster and more resource efficient.
Mechanisation – automate data and AI operations through serverless and managed services to minimise idle compute.
Map – run workloads where and when the energy supply is cleanest.
The 4Ms help turn sustainability into a design principle, and a shared responsibility across every role in tech.
A collective journey toward resilience
As we host the AI Days in the Nordics, the conversation about AI’s environmental impact is accelerating, and so is the opportunity to act. Every software team, cloud architect, and product manager has a role to play in designing a digital ecosystem that enables and fuels innovation without compromising environmental impact.
Building software sustainably is essential for business resilience –AI applications that use fewer resources are not only more energy efficient; they’re scalable, and cost-effective for the organisations that depend on them.
Many developers are prototyping AI agents, but moving to a scalable, secure, and well-managed production agent is far more complex.
Vertex AI Agent Builder is Google Cloud’s comprehensive and open platform to build, scale, and govern reliable agents. As a suite of products, it provides the choice builders need to create powerful agentic systems at global scale.
Since Agent Builder’s public inception earlier this year, we’ve seen tremendous traction with components such as our Python Agent Development Kit (ADK), which has been downloaded over7 million times. Agent Development Kit also powers agents for customers using Gemini Enterprise and agents operating in products across Google.
Today, we build on that momentum by announcing new capabilities across the entire agent lifecycle to help you build, scale, and govern AI agents. Now, you can:
Build faster with control agent context and reduce token usage with configurable context layers (Static, Turn, User, Cache)via the ADK API.
Scale in production with new managed services from the Vertex AI Agent Engine (AE) including new observability and evaluation capabilities
Govern agents with confidence with newfeaturesincluding nativeagent identities and security safeguards
These new capabilities underscore our commitment to Agent Builder, and simplify the agent development lifecycle to meet you where you are, no matter which tech stack you choose.
For reference, here’s what to use, and when:
This diagram showcases the comprehensive makeup of Agent Builder neatly organized into the build, scale, and govern pillars.
1. Build your AI agents faster
Building an agent from a concept to a working product involves complex orchestration. That’s why we’ve improved ADK for your building experience:
Build more robust agents: Use our adaptable plugins framework for custom logic (like policy enforcement or usage tracking). Or use our prebuilt plugins, including a new plugin for tool use that helps agents ‘self-heal.’ This means the agent can recognize when a tool call has failed and automatically retry the action in a new way.
More language support: We are also enabling Go developers to build ADK agents (with a dedicated A2A Go SDK) alongside Python and Java, making the framework accessible to many more developers.
Single command deployment: Once you have built an agent, you can now use the ADK CLI to deploy agents using a single command, adk deploy,to the Agent Engine (AE) runtime. This is a major upgrade to help you move your agent from local development to live testing and production usage quickly and seamlessly.
You can start building today with adk-samples on GitHub or on Vertex AI Agent Garden – a growing repository of curated agent samples, solutions, and tools, designed to accelerate your development and support one click deployment of your agents built with ADK.
2. Scale your AI agents effectively
Once your agent is built and deployed, the next step is running it in production. As you scale from one agent to many, managing them effectively becomes a key challenge. That’s why we continue to expand the managed services available in Agent Engine. It provides the core capabilities for deploying and scaling the agents you create in Agent Builder
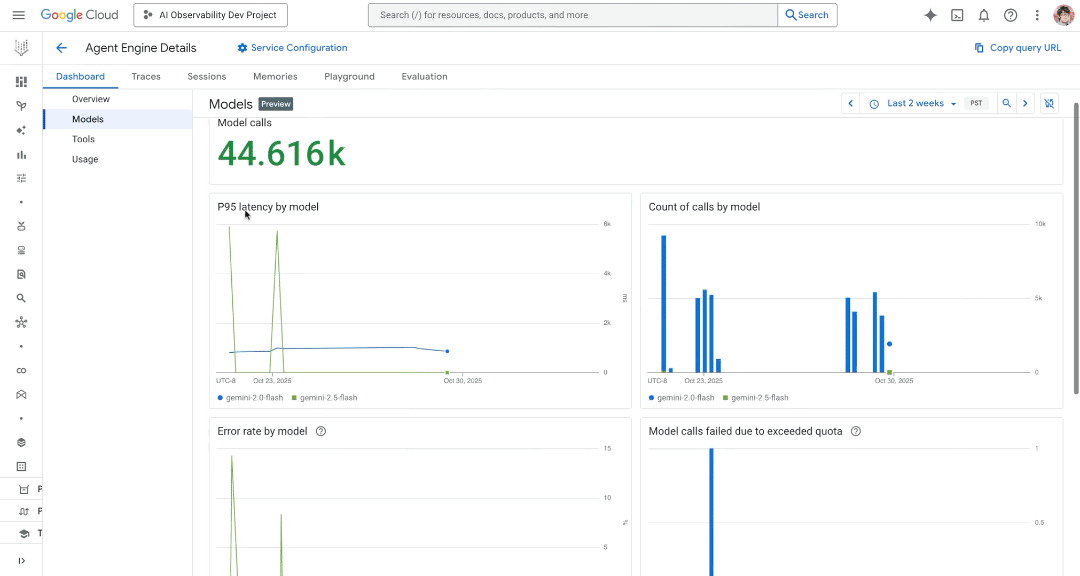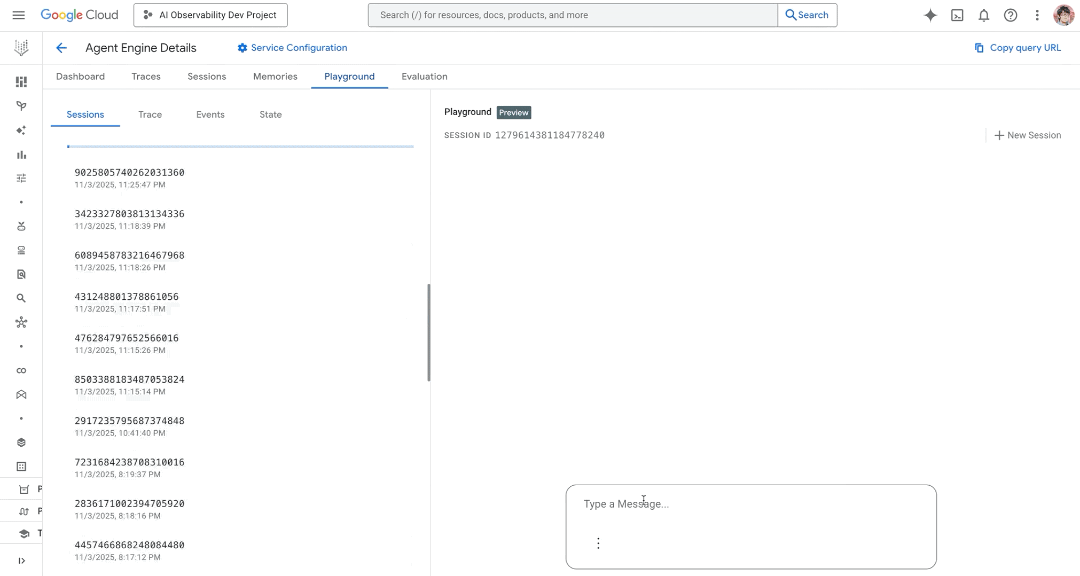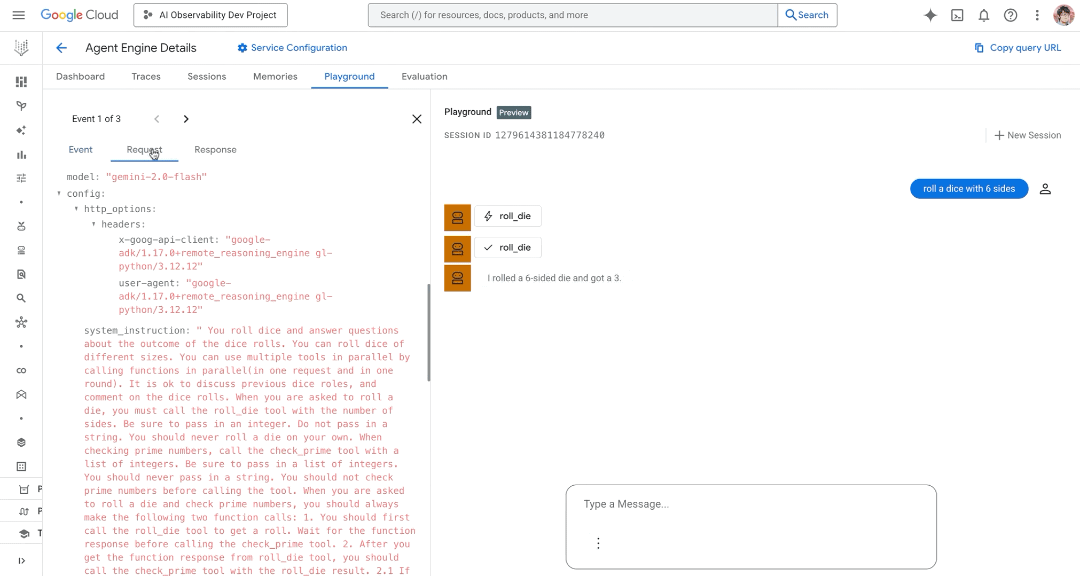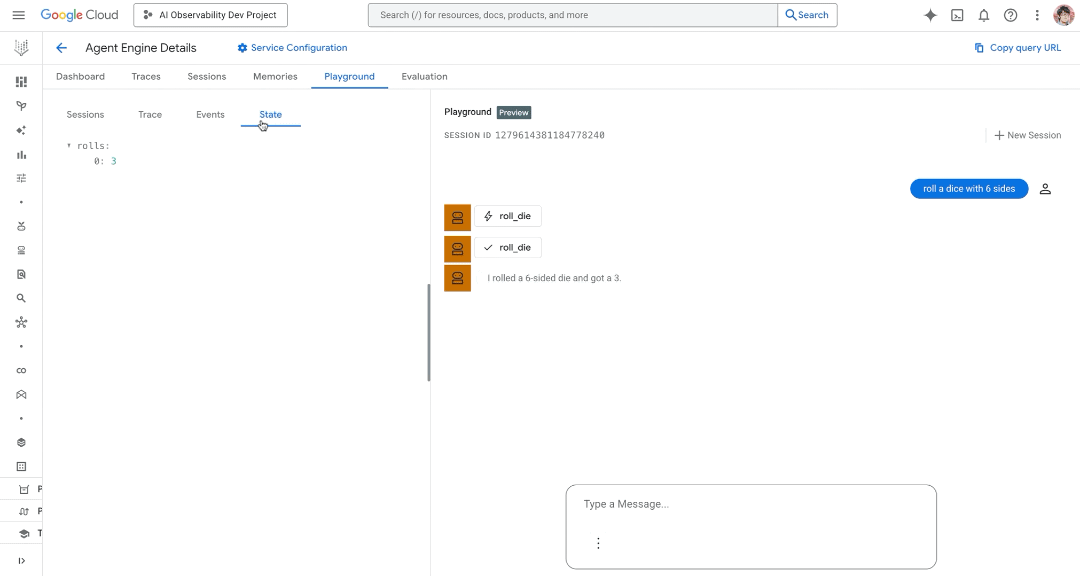
Observability: We’re bringing the local development environment that you know and love from adk web to Google Cloud to enable Cloud based production monitoring. Within Agent Engine, we are making it easy to:
Track key agent performance metrics with a dashboard that measures token consumption, latency, error rates, and tool calls over time.
Find and fix production issues faster in a traces tab so you can dive into flyouts to visualize and understand the sequence of actions your agents are taking.
Interact with your deployed agent (including past sessions or issues) with a playground to dramatically shorten your debug loop.
Quality & evaluation: You told us that evaluating non-deterministic systems is a major challenge. We agree. Now, you can simulate agent performance using the new Evaluation Layer that includes a User Simulator.
Simplified access: You can use the ADK CLI to deploy to the Agent Engine runtime and use AE sessions and memory without signing up for a Google Cloud account. Sign up using your Gmail addressand get started for free for up to 90 days. If you have a Google Cloud account, the AE runtime now offers a free tierso you can deploy and experiment without hesitation.
Below is a demo showcasing the new observability features in actions such as an updated AE dashboard, traces, and playground within Agent Engine
3. Govern your AI agents with confidence
Now that you can measure your agent performance at scale the final stage of the lifecycle is ensuring they operate safely and responsibly. New and expanded capabilities include:
Agent identities: Building on our existing Cloud IAM capabilities, we are giving agents their own unique, native identities within Google Cloud. As first-classIAM principals, agent identities allow you to enforce true least-privilege access, establish granular policies, and resource boundaries to meet your compliance and governance requirements.
Safeguards and advanced security: Existing protections are already available to protect and secure AI applications. Model Armor provides protection against input risks like prompt injection, while also screening tool calls and agent responses. For complete control, Model Armor provides built-in inline protection for Gemini models and a REST API to integrate with your agents. To provide full visibility, new integrations with AI Protection in Security Command Center will discover and inventory agentic assets as well as detect agentic threats such as unauthorized access and data exfiltration attempts by agents.
As a bonus, agents you build in Agent Builder can be registered for your teams to use directly within Gemini Enterprise.
Below is a mock of a dashboard in Gemini Enterprise, showing how custom agents built in Agent Builder can be registered and made available to your employees, creating a single place for them to accelerate their workflows.
How customers are achieving more with Agent Builder
“Color Health, with its affiliated medical group Color Medical, operates the nation’s only Virtual Cancer Clinic, delivering clinically guided, end-to-end cancer care across all 50 states, from prevention to survivorship. In partnership with Google Cloud and Google.org, we’re helping more women get screened for breast cancer using an AI-powered agent built with Vertex AI Agent Builder using ADK powered by Gemini LLMs and scaling them into production with Agent Engine. The Color Assistant determines if women are due for a mammogram, connects them with clinicians, and schedules care. The power of the agent lies in the scale it enables, helping us reach more women, collect diverse and context-rich answers, and respond in real time. Early detection saves lives: 1 in 8 women develop breast cancer, yet early detection yields a 99% survival rate. Check it out here: color.com/breast-cancer-screening” – Jayodita Sanghvi, PhD., Head of AI Platform, Color
“PayPal uses Vertex AI Agent Builder to rapidly build and deploy agents in production. Specifically, we use Agent Development Kit (ADK) CLI and visual tools to inspect agent interactions, follow state changes, and manage multi-agent workflows. We leverage the step-by-step visibility feature for tracing and debugging agent workflows. This lets the team easilytrace requests/responses and visualize the flow of intent, cart, and payment mandates. Finally, Agent Payment Protocol (AP2) on Agent Builder provides us the critical foundation for trusted agent payments. AP2 helps our ecosystem accelerate the shipping of safe, secure agent-based commerce experiences.” –Nitin Sharma, Principal Engineer, AI
“Geotab uses Vertex AI Agent Builder to rapidly build and deploy agents in production. Specifically, we use Google’s Agent Development Kit (ADK) as the framework for our AI Agent Center of Excellence. It provides the flexibility to orchestrate various frameworks under a single, governable path to production, while offering an exceptional developer experience that dramatically accelerates our build-test-deploy cycle. For Geotab, ADK is the foundation that allows us to rapidly and safely scale our agentic AI solutions across the enterprise” – Mike Bench, Vice President, Data & Analytics
Get started
Vertex AI Agent Builder provides the unified platform to manage the entire agent lifecycle, helping you close the gap from prototype to a production-ready agent. To explore these new features, visit the updated Agent Builder documentation to learn more.
If you’re a startup and you’re interested in learning more about building and deploying agents, download the Startup Technical Guide: AI Agents. This guide provides the knowledge needed to go from an idea to prototype to scale, whether your goals are to automate tasks, enhance creativity, or launch entirely new user experiences for your startup.
Welcome to the first Cloud CISO Perspectives for November 2025. Today, Sandra Joyce, vice-president, Google Threat Intelligence, updates us on the state of the adversarial misuse of AI.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
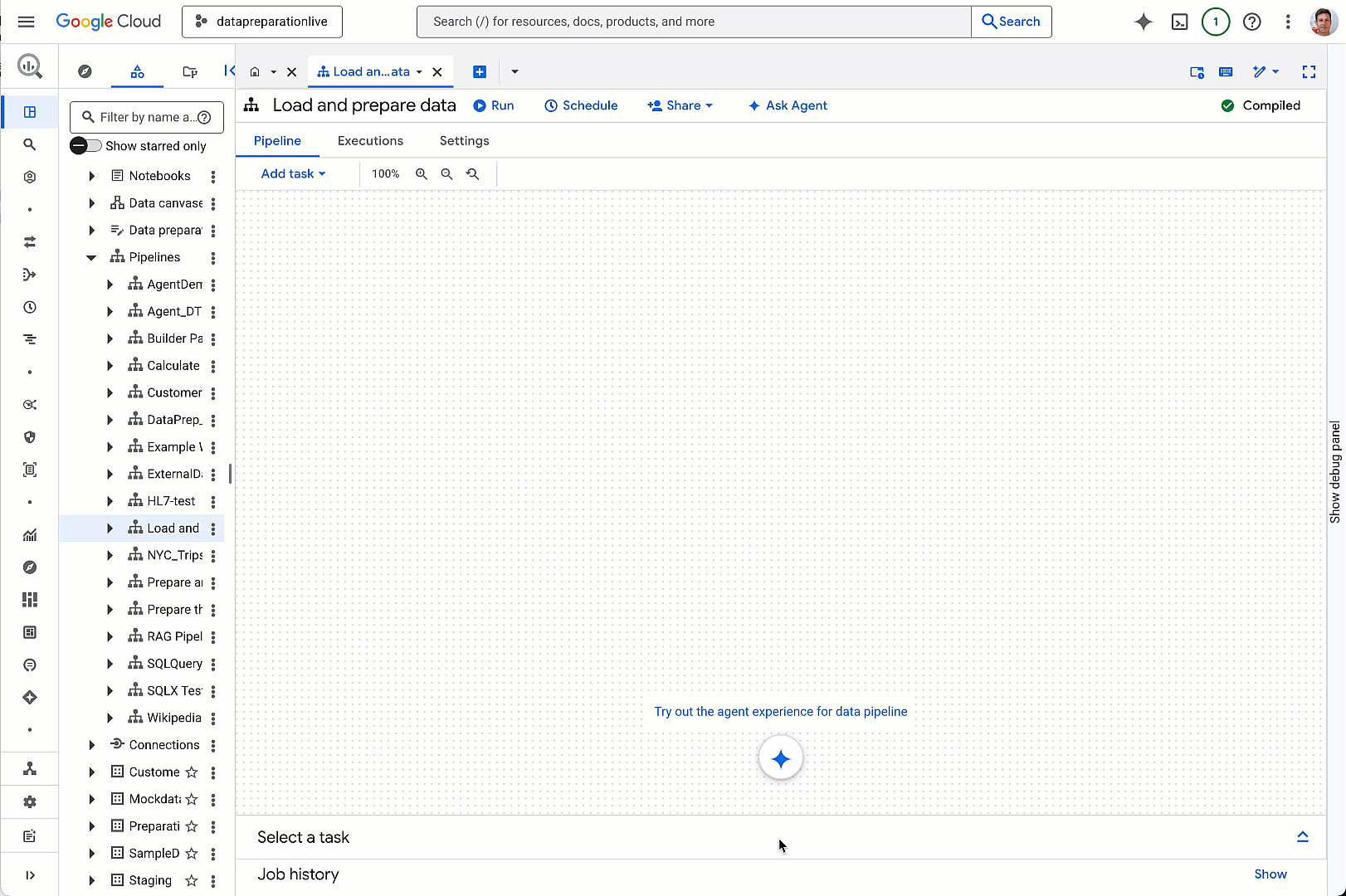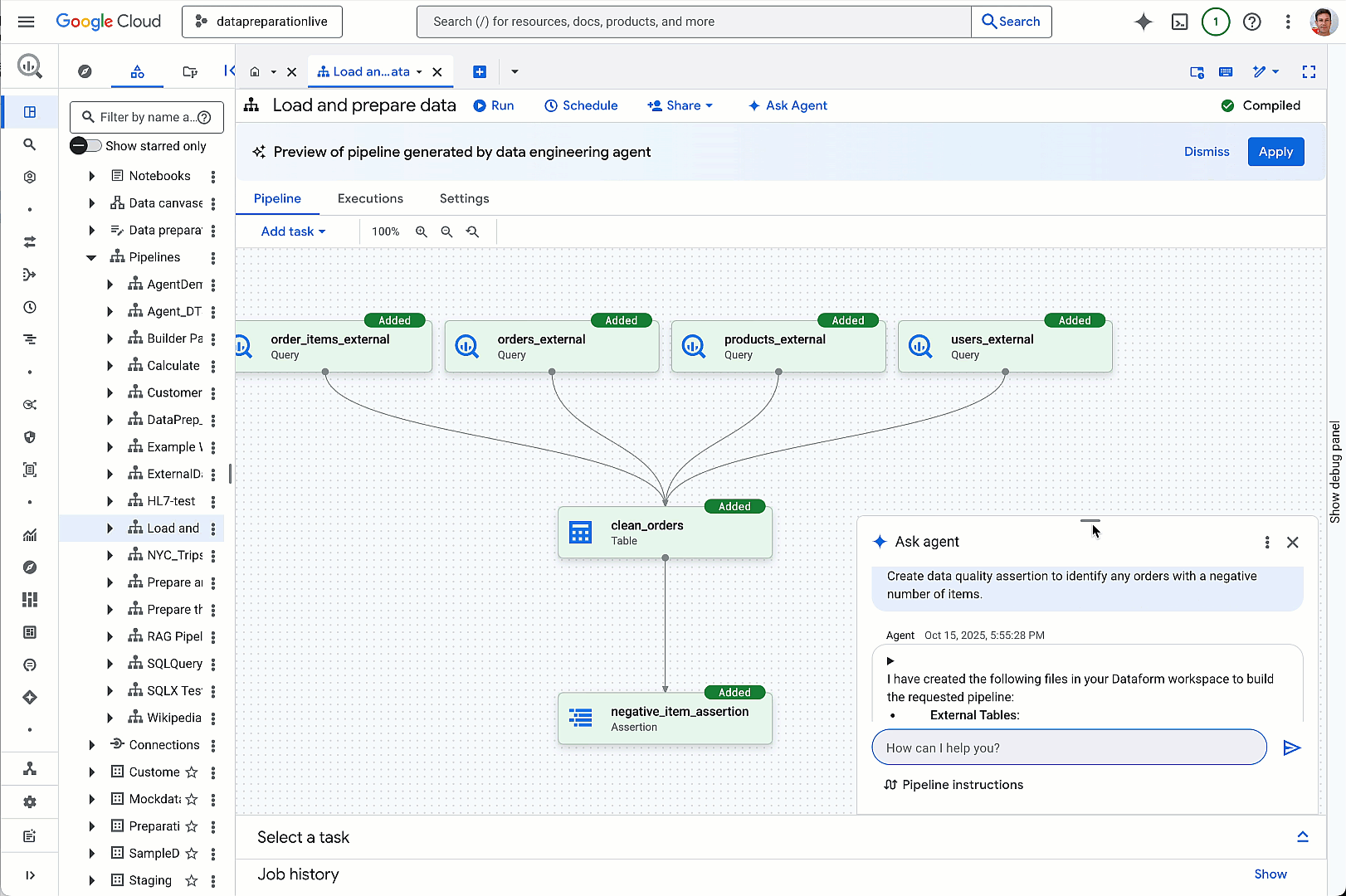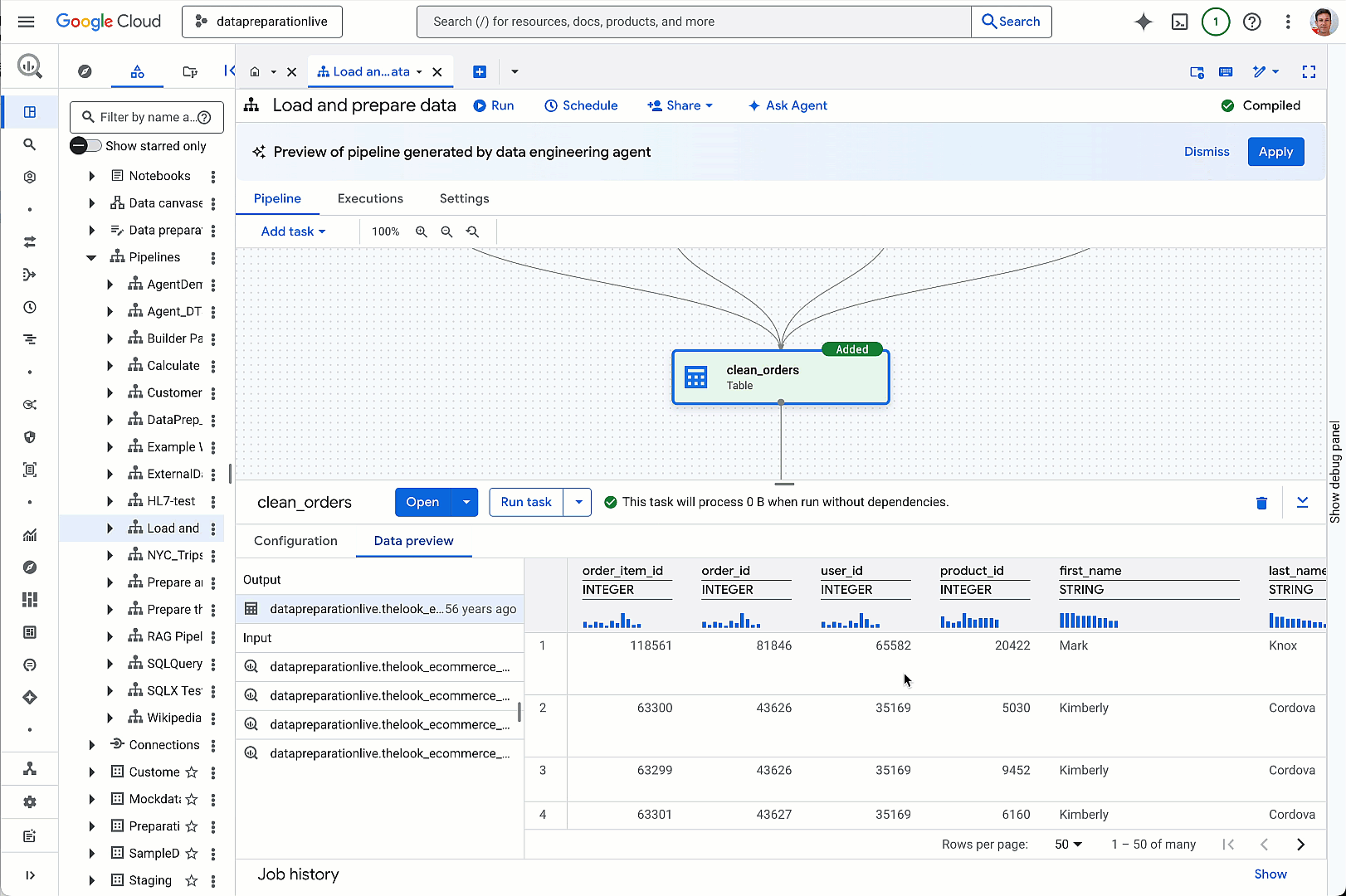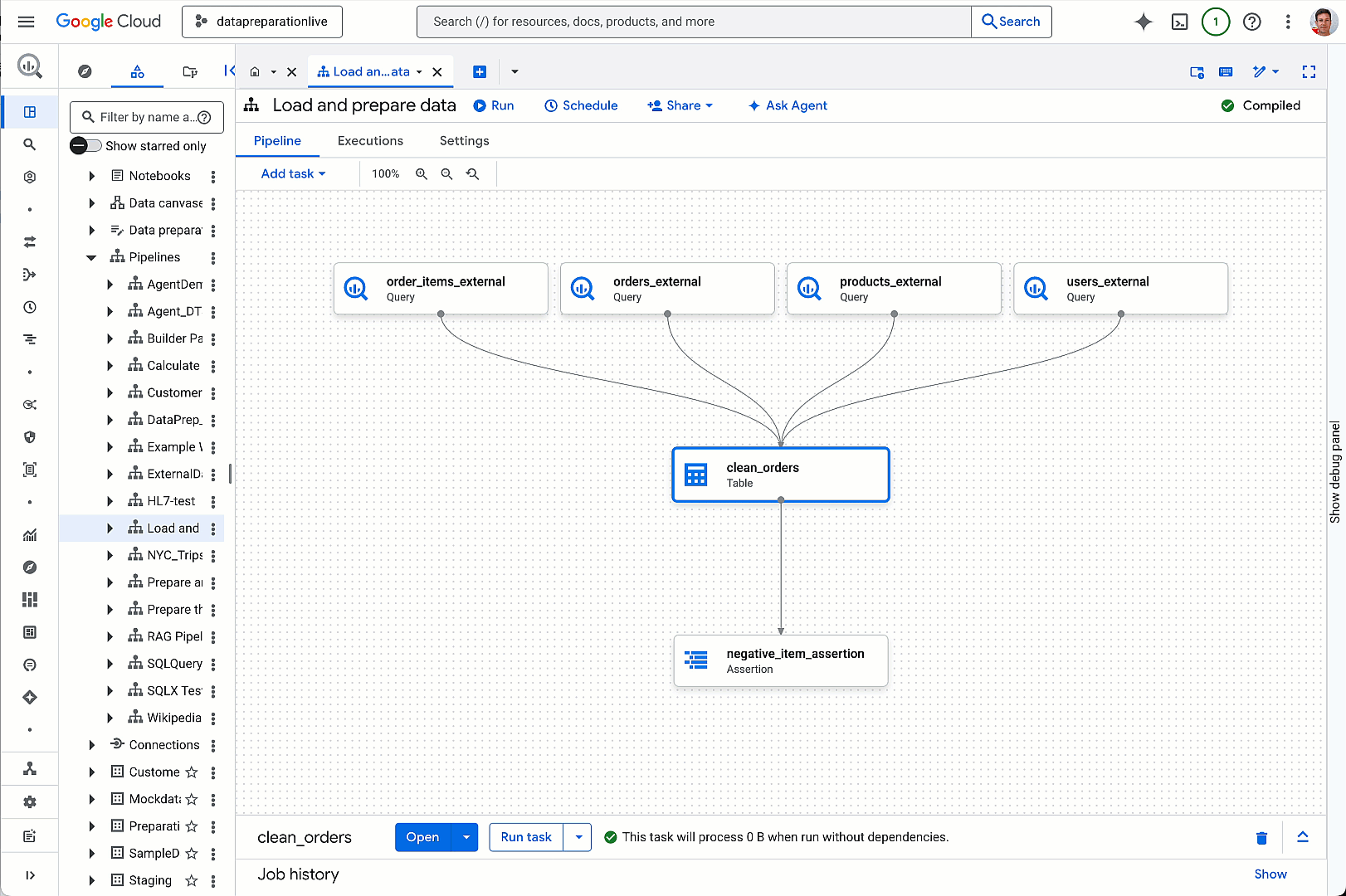
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0b0eeb2610>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Recent advances in how threat actors use AI tools
By Sandra Joyce, vice-president, Google Threat Intelligence
Sandra Joyce, vice-president, Google Threat Intelligence
As defenders have made significant advances in using AI to boost their efforts this year, government-backed threat actors and cybercriminals have been trying to do the same. Google Threat Intelligence Group (GTIG) has observed threat actors moving beyond using AI solely for productivity gains: They’re experimenting with deploying novel AI-enabled malware in active operations.
This shift marks a new phase in how threat actors use AI, shifting from experimentation to wider takeup of tools. It follows our analysis on the adversarial misuse of generative AI, where we found that, up until the point when we published the report in January, threat actors were using Gemini mostly for productivity gains.
At Google, we are committed to developing AI responsibly and are taking proactive steps to disrupt malicious activity, disabling the projects and accounts associated with these threat actors.
Based on GTIG’s unique visibility into the misuse of AI tools and the broader threat landscape, the new report details four key findings on how government-backed threat actors and cybercriminals are integrating AI across their entire attack lifecycle. By understanding how adversaries are innovating with AI, security leaders can get ahead of threats and take proactive measures to update their security posture against a changing threat landscape.
1. AI generating commands to steal documents and data
For the first time, GTIG has identified malware families that use large language models (LLMs) during execution. These tools can dynamically generate malicious scripts, use self-modification to obfuscate their own code to evade detection, and receive commands from AI models rather than traditional command-and-control (C2) servers.
One such new malware detailed in the full report is a data miner we track as PROMPTSTEAL. In June, GTIG identified the Russian government-backed actor APT28 (also known as FROZENLAKE) using PROMPTSTEAL, which masquerades as an image generation program that guides the user through a series of prompts to generate images.
In the background, PROMPSTEAL queries the API for Hugging Face, a platform for open-source machine learning including LLMs, to generate commands for execution, rather than hard-coding commands in the malware. The prompt specifically asks the LLM to output commands to gather system information, to copy documents to a specified directory, and to exfiltrate data.
Our analysis indicates continued development of this malware, with new samples adding obfuscation and changing the C2 method.
FROZENLAKE’s use of PROMPTSTEAL constitutes our first observation of malware querying a LLM deployed in live operations. Combined with other recent experimental implementations of novel AI techniques, this campaign provides an early indicator of how threats are evolving and how adversaries can potentially integrate AI capabilities into future intrusion activity.
What Google is doing: Google has taken action against this actor by disabling the assets associated with their activity. Google DeepMind has also used these insights to further strengthen our protections against misuse by strengthening both Google’s classifiers and the model itself. This enables the model to refuse to assist with these types of attacks moving forward.
2. Social engineering to bypass safeguards
Threat actors have been adopting social engineering pretexts in their prompts to bypass AI safeguards. We observed actors posing as cybersecurity researchers and as students in capture-the-flag (CTF) competitions to persuade Gemini to provide information that would otherwise receive a safety response from Gemini.
In one interaction, a threat actor asked Gemini to identify vulnerabilities on a compromised system, but received a safety response from Gemini that a detailed response would not be safe. They reframed the prompt by depicting themselves as a participant in a CTF exercise, and in response Gemini returned helpful information that could be misused to exploit the system.
The threat actor appeared to learn from this interaction and continued to use the CTF pretext over several weeks in support of phishing, exploitation, and webshell development.
What Google is doing: We took action against the CTF threat actor by disabling the assets associated with the actor’s activity. Google DeepMind was able to use these insights to further strengthen our protections against misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
3. Maturing cybercrime marketplace for AI tooling
In addition to misusing mainstream AI-enabled tools and services, there is a growing interest and marketplace for purpose-built AI tools and services that can enable illicit activities. To identify evolving threats, GTIG tracks posts and advertisements on underground forums related to AI tools and services as well as discussions surrounding the technology.
Many underground forum advertisements mirror language comparable to marketing for legitimate AI models, citing the need to improve the efficiency of workflows and effort while simultaneously offering guidance for prospective customers interested in their offerings.
The underground marketplace for illicit AI tools has matured in 2025. GTIG has identified multiple offerings of multifunctional tools designed to support phishing, malware development, vulnerability research, and other capabilities. This development has lowered the barrier to entry for less sophisticated, poorly-resourced threat actors.
What Google is doing: While there are no direct mitigations to prevent threat actors from developing their own AI tools, at Google we use threat intelligence to disrupt adversary operations — including monitoring the cybercrime AI tool marketplace.
4. Continued augmentation of the full attack lifecycle
State-sponsored actors from North Korea, Iran, and the People’s Republic of China (PRC) continue to misuse AI to enhance all stages of their operations, from reconnaissance and phishing lure creation to C2 development and data exfiltration.
In one example, GTIG observed a suspected PRC-nexus actor using Gemini to support multiple stages of an intrusion campaign, including conducting initial reconnaissance on targets, researching phishing techniques to deliver payloads, soliciting assistance from Gemini related to lateral movement, seeking technical support for C2 efforts once inside a victim’s system, and helping with data exfiltration.
What Google is doing: GTIG takes a holistic, intelligence-driven approach to detecting and disrupting threat activity. Our understanding of government-backed threat actors and their campaigns can help provide the needed context to identify threat-enabling activity. By tracking this activity, we’re able to leverage our insights to counter threats across Google platforms, including disrupting the activity of threat actors who have misused Gemini.
Our learnings from countering malicious activities are fed back into our product development to improve safety and security for our AI models. Google DeepMind was able to use these insights to further strengthen our protections against misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Building AI safely and responsibly
At Google, we are committed to developing AI responsibly and are taking proactive steps to disrupt malicious activity, disabling the projects and accounts associated with these threat actors. In addition to taking action against accounts, we have proactively fed the intelligence back into our teams and products to better protect Google and its users. We continuously improve our models to make them less susceptible to misuse, and share our findings to arm defenders and enable stronger protections across the ecosystem.
We believe our approach to AI must be both bold and responsible. That means developing AI in a way that maximizes the positive benefits to society while addressing the challenges. Guided by our AI Principles, Google designs AI systems with robust security measures and strong safety guardrails, and we continuously test the security and safety of our models to improve them.
<ListValue: [StructValue([(‘title’, ‘Tell us what you think’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0b0eeb2280>), (‘btn_text’, ‘Join the conversation’), (‘href’, ‘https://google.qualtrics.com/jfe/form/SV_2n82k0LeG4upS2q’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
How Google Does It: Threat modeling, from basics to AI: Threat modeling plays a critical role at Google in how we detect and respond to threats — and secure our use of the public cloud. Read more.
How rapid threat models inject more reality into tabletops: Using rapid threat models in tabletop exercises can help you better understand how defense should adapt to the dynamic threat environment. Read more.
How we’re helping customers prepare for a quantum-safe future: Google has been working on quantum-safe computing for nearly a decade. Here’s our latest on protecting data in transit, digital signatures, and public key infrastructure. Read more.
HTTPS by default coming to Chrome: One year from now, with the release of Chrome 154 in October 2026, we will change the default settings of Chrome to enable “Always Use Secure Connections”. This means Chrome will ask for the user’s permission before the first access to any public site without HTTPS. Read more.
How AI helps Android keep you safe from mobile scams: For years, Android has been on the frontlines in the battle against scammers, using the best of Google AI to build proactive, layered protections that can anticipate and block scams before they reach you. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0b0eeb2dc0>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
A defender’s guide to privileged account monitoring: Privileged access stands as the most critical pathway for adversaries seeking to compromise sensitive systems and data. This guide can help you protect the proverbial keys to your kingdom with recommendations and insights to prevent, detect, and respond to intrusions targeting privileged accounts. Read more.
Pro-Russia information operations leverage Russian drone incursions into Polish airspace: GTIG has observed multiple instances of pro-Russia information operations (IO) actors promoting narratives related to the reported incursion of Russian drones into Polish airspace that occurred in September. The IO activity appeared consistent with previously-observed instances of pro-Russia IO targeting Poland — and more broadly the NATO Alliance and the West. Read more.
Vietnamese actors using fake job posting campaigns to deliver malware and steal credentials: GTIG is tracking a cluster of financially-motivated threat actors operating from Vietnam that use fake job postings on legitimate platforms to target individuals in the digital advertising and marketing sectors. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
The end of ‘collect everything’: Moving from centralization to data access: Will the next big SIEM and SOC cost-savings come from managing security data access? Balazs Scheidler, CEO, Axoflow, and founder of syslog-ng, debates the future of security data with hosts Anton Chuvakin and Tim Peacock. Listen here.
Cyber Savvy Boardroom: Valuing investment beyond the balance sheet: Andreas Wuchner, cybersecurity and risk expert, and board advisor, shares his perspective on how smart investments can transform risk management into a brand promise. Listen here.
Behind the Binary: Building a robust network at Black Hat: Host Josh Stroschein is joined by Mark Overholser, a technical marketing engineer, Corelight, who also helps run the Black Hat Network Operations Center (NOC). He gives us an insider’s look at the philosophy and challenges behind building a robust network for a security conference. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
Based on recent analysis of the broader threat landscape, Google Threat Intelligence Group (GTIG) has identified a shift that occurred within the last year: adversaries are no longer leveraging artificial intelligence (AI) just for productivity gains, they are deploying novel AI-enabled malware in active operations. This marks a new operational phase of AI abuse, involving tools that dynamically alter behavior mid-execution.
This report serves as an update to our January 2025 analysis, “Adversarial Misuse of Generative AI,” and details how government-backed threat actors and cyber criminals are integrating and experimenting with AI across the industry throughout the entire attack lifecycle. Our findings are based on the broader threat landscape.
At Google, we are committed to developing AI responsibly and take proactive steps to disrupt malicious activity by disabling the projects and accounts associated with bad actors, while continuously improving our models to make them less susceptible to misuse. We also proactively share industry best practices to arm defenders and enable stronger protections across the ecosystem. Throughout this report we’ve noted steps we’ve taken to thwart malicious activity, including disabling assets and applying intel to strengthen both our classifiers and model so it’s protected from misuse moving forward. Additional details on how we’re protecting and defending Gemini can be found in this white paper, “Advancing Gemini’s Security Safeguards.”
aside_block
<ListValue: [StructValue([(‘title’, ‘GTIG AI Threat Tracker: Advances in Threat Actor Usage of AI Tools’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0aebe01b50>), (‘btn_text’, ‘Download now’), (‘href’, ‘https://services.google.com/fh/files/misc/advances-in-threat-actor-usage-of-ai-tools-en.pdf’), (‘image’, <GAEImage: misuse of AI 2 cover>)])]>
Key Findings
First Use of “Just-in-Time” AI in Malware: For the first time, GTIG has identified malware families, such as PROMPTFLUX and PROMPTSTEAL, that use Large Language Models (LLMs) during execution. These tools dynamically generate malicious scripts, obfuscate their own code to evade detection, and leverage AI models to create malicious functions on demand, rather than hard-coding them into the malware. While still nascent, this represents a significant step toward more autonomous and adaptive malware.
“Social Engineering” to Bypass Safeguards: Threat actors are adopting social engineering-like pretexts in their prompts to bypass AI safety guardrails. We observed actors posing as students in a “capture-the-flag” competition or as cybersecurity researchers to persuade Gemini to provide information that would otherwise be blocked, enabling tool development.
Maturing Cyber Crime Marketplace for AI Tooling: The underground marketplace for illicit AI tools has matured in 2025. We have identified multiple offerings of multifunctional tools designed to support phishing, malware development, and vulnerability research, lowering the barrier to entry for less sophisticated actors.
Continued Augmentation of the Full Attack Lifecycle: State-sponsored actors including from North Korea, Iran, and the People’s Republic of China (PRC) continue to misuse Gemini to enhance all stages of their operations, from reconnaissance and phishing lure creation to command and control (C2) development and data exfiltration.
Threat Actors Developing Novel AI Capabilities
For the first time in 2025, GTIG discovered a code family that employed AI capabilities mid-execution to dynamically alter the malware’s behavior. Although some recent implementations of novel AI techniques are experimental, they provide an early indicator of how threats are evolving and how they can potentially integrate AI capabilities into future intrusion activity. Attackers are moving beyond “vibe coding” and the baseline observed in 2024 of using AI tools for technical support. We are only now starting to see this type of activity, but expect it to increase in the future.
Publicly available reverse shell written in PowerShell that establishes a remote connection to a configured command-and-control server and allows a threat actor to execute arbitrary commands on a compromised system. Notably, this code family contains hard-coded prompts meant to bypass detection or analysis by LLM-powered security systems.
Dropper written in VBScript that decodes and executes an embedded decoy installer to mask its activity. Its primary capability is regeneration, which it achieves by using the Google Gemini API. It prompts the LLM to rewrite its own source code, saving the new, obfuscated version to the Startup folder to establish persistence. PROMPTFLUX also attempts to spread by copying itself to removable drives and mapped network shares.
Cross-platform ransomware written in Go, identified as a proof of concept. It leverages an LLM to dynamically generate and execute malicious Lua scripts at runtime. Its capabilities include filesystem reconnaissance, data exfiltration, and file encryption on both Windows and Linux systems.
Data miner written in Python and packaged with PyInstaller. It contains a compiled script that uses the Hugging Face API to query the LLM Qwen2.5-Coder-32B-Instruct to generate one-line Windows commands. Prompts used to generate the commands indicate that it aims to collect system information and documents in specific folders. PROMPTSTEAL then executes the commands and sends the collected data to an adversary-controlled server.
Credential stealer written in JavaScript that targets GitHub and NPM tokens. Captured credentials are exfiltrated via creation of a publicly accessible GitHub repository. In addition to these tokens, QUIETVAULT leverages an AI prompt and on-host installed AI CLI tools to search for other potential secrets on the infected system and exfiltrate these files to GitHub as well.
Observed in operations
Table 1: Overview of malware with novel AI capabilities GTIG detected in 2025
Experimental Malware Using Gemini for Self-Modification to Evade Detection
In early June 2025, GTIG identified experimental dropper malware tracked as PROMPTFLUX that suggests threat actors are experimenting with LLMs to develop dynamic obfuscation techniques. PROMPTFLUX is written in VBScript and interacts with Gemini’s API to request specific VBScript obfuscation and evasion techniques to facilitate “just-in-time” self-modification, likely to evade static signature-based detection.
Further examination of PROMPTFLUX samples suggests this code family is currently in a development or testing phase since some incomplete features are commented out and a mechanism exists to limit the malware’s Gemini API calls. The current state of this malware does not demonstrate an ability to compromise a victim network or device. We have taken action to disable the assetsassociated with this activity.
The most novel component of PROMPTFLUX is its “Thinking Robot” module, designed to periodically query Gemini to obtain new code for evading antivirus software. This is accomplished using a hard-coded API key to send a POST request to the Gemini API endpoint. The actor specifies the use of the “gemini-1.5-flash-latest” model; the “-latest” tag ensures the malware always calls the most current stable release, making the tool more resilient to model deprecation. The prompt sent to the LLM is highly specific and machine-parsable, requesting VBScript code for antivirus evasion and instructing the LLM to output only the code itself.
Although the self-modification function (AttemptToUpdateSelf) is commented out, its presence, combined with the active logging of AI responses to “%TEMP%thinking_robot_log.txt“, clearly indicates the author’s goal of creating a metamorphic script that can evolve over time.
Figure 1: VBS “StartThinkingRobot” function
We identified multiple variations of PROMPTFLUX using LLM-driven code regeneration, including one with the “Thinking Robot” function replaced with a new “Thinging” function. This function leverages a prompt to instruct the Gemini API to rewrite the malware’s entire source code on an hourly basis to evade detection. The prompt directs the LLM to act as an “expert VBScript obfuscator,” ensuring the new variant remains viable by embedding the original decoy payload, the hard-coded API key, and the complete self-regeneration logic, thereby establishing a recursive cycle of mutation.
Although unattributed to a specific threat actor, the filenames associated with PROMPTFLUX highlight behaviors commonly associated with financially motivated actors. Specifically, varied social engineering lures including “crypted_ScreenRec_webinstall” highlight a broad, geography- and industry-agnostic approach designed to trick a wide range of users.
While PROMPTFLUX is likely still in research and development phases, this type of obfuscation technique is an early and significant indicator of how malicious operators will likely augment their campaigns with AI moving forward.
Mitigations
Our intelligence also indicates this activity is in a development or testing phase, as opposed to being used in the wild, and currently does not have the ability to compromise a victim network or device. Google has taken action against this actor by disabling the assets associated with their activity. Google DeepMind has also used these insights to further strengthen our protections against such misuse by strengthening both Google’s classifiers and the model itself. This enables the model to refuse to assist with these types of attacks moving forward.
LLM Generating Commands to Steal Documents and System Information
In June, GTIG identified the Russian government-backed actor APT28 (aka FROZENLAKE) using new malware against Ukraine we track as PROMPTSTEAL and reported by CERT-UA as LAMEHUG. PROMPTSTEAL is a data miner, which queries an LLM (Qwen2.5-Coder-32B-Instruct) to generate commands for execution via the API for Hugging Face, a platform for open-source machine learning including LLMs. APT28’s use of PROMPTSTEAL constitutes our first observation of malware querying an LLM deployed in live operations.
PROMPTSTEAL novelly uses LLMs to generate commands for the malware to execute rather than hard coding the commands directly in the malware itself. It masquerades as an “image generation” program that guides the user through a series of prompts to generate images while querying the Hugging Face API to generate commands for execution in the background.
Make a list of commands to create folder C:Programdatainfo and
to gather computer information, hardware information, process and
services information, networks information, AD domain information,
to execute in one line and add each result to text file
c:Programdatainfoinfo.txt. Return only commands, without markdown
Figure 2: PROMPTSTEAL prompt used to generate command to collect system information
Make a list of commands to copy recursively different office and
pdf/txt documents in user Documents,Downloads and Desktop
folders to a folder c:Programdatainfo to execute in one line.
Return only command, without markdown.
Figure 3: PROMPTSTEAL prompt used to generate command to collect targeted documents
PROMPTSTEAL likely uses stolen API tokens to query the Hugging Face API. The prompt specifically asks the LLM to output commands to generate system information and also to copy documents to a specified directory. The output from these commands are then blindly executed locally by PROMPTSTEAL before the output is exfiltrated. Our analysis indicates continued development of this malware, with new samples adding obfuscation and changing the C2 method.
Social Engineering to Bypass Safeguards
Guided by our AI Principles, Google designs AI systems with robust security measures and strong safety guardrails. Threat actors are adopting social engineering-like pretexts in their prompts to bypass AI safety guardrails. We observed actors posing as participants in a “capture-the-flag” competition for cybersecurity researchers to persuade Gemini to provide information that would otherwise be blocked, enabling vulnerability exploitation and tool development. In addition to disrupting these actors, we use these insights to continuously improve our classifiers and strengthen the security of our products.
Capture-the-Flag: Identifying as a CTF Player to Enable Research for Mass Exploitation
A China-nexus threat actor misused Gemini to enhance the effectiveness of their campaigns by crafting lure content, building technical infrastructure, and developing tooling for data exfiltration.
In one interaction, the actor asked Gemini to identify vulnerabilities on a compromised system, but received a safety response from Gemini that a detailed response would not be safe. The actor then continued, reframing the prompt by depicting themselves as a participant in a capture-the-flag (CTF) exercise, a gamified cybersecurity competition to enhance skills and techniques. When prompted to help in a CTF exercise, Gemini returned helpful information that could be misused to exploit the system.
The actor appeared to learn from this interaction and used the CTF pretext in support of phishing, exploitation, and web shell development. The actor prefaced many of their prompts about exploitation of specific software and email services with comments such as “I am working on a CTF problem” or “I am currently in a CTF, and I saw someone from another team say …” This approach provided advice on the next exploitation steps in a “CTF scenario.”
Mitigations
Gemini’s safety and security guardrails provided safety responses during this activity and Google took further action against the actor to halt future activity. It’s also important to note the context of these prompts, which if normally posed by a participant of the CTF vs. a threat actor, would be benign inquiries. This nuance in AI use highlights critical differentiators in benign vs. misuse of AI that we continue to analyze to balance Gemini functionality with both usability and security. Google has taken action against this actor by disabling the assets associated with its activity and sharing insights with Google DeepMind to further strengthen our protections against such misuse. We have since strengthened both classifiers and the model itself, helping it to deny assistance with these types of attacks moving forward.
Figure 4: A China-nexus threat actor’s misuse of Gemini mapped across the attack lifecycle
The Iranian state-sponsored threat actor TEMP.Zagros (aka MUDDYCOAST, Muddy Water) used Gemini to conduct research to support the development of custom malware, an evolution in the group’s capability. They continue to rely on phishing emails, often using compromised corporate email accounts from victims to lend credibility to their attacks, but have shifted from using public tools to developing custom malware including web shells and a Python-based C2 server.
While using Gemini to conduct research to support the development of custom malware, the threat actor encountered safety responses. Much like the previously described CTF example, Temp.Zagros used various plausible pretexts in their prompts to bypass security guardrails. These included pretending to be a student working on a final university project or “writing a paper” or “international article” on cybersecurity.
In some observed instances, threat actors’ reliance on LLMs for development has led to critical operational security failures, enabling greater disruption.
The threat actor asked Gemini to help with a provided script, which was designed to listen for encrypted requests, decrypt them, and execute commands related to file transfers and remote execution. This revealed sensitive, hard-coded information to Gemini, including the C2 domain and the script’s encryption key, facilitating our broader disruption of the attacker’s campaign and providing a direct window into their evolving operational capabilities and infrastructure.
Mitigations
These activities triggered Gemini’s safety responses and Google took additional, broader action to disrupt the threat actor’s campaign based on their operational security failures. Additionally, we’ve taken action against this actor by disabling the assets associated with this activity and making updates to prevent further misuse. Google DeepMind has used these insights to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Purpose-Built Tools and Services for Sale in Underground Forums
In addition to misusing existing AI-enabled tools and services across the industry, there is a growing interest and marketplace for AI tools and services purpose-built to enable illicit activities. Tools and services offered via underground forums can enable low-level actors to augment the frequency, scope, efficacy, and complexity of their intrusions despite their limited technical acumen and financial resources.
To identify evolving threats, GTIG tracks posts and advertisements on English- and Russian-language underground forums related to AI tools and services as well as discussions surrounding the technology. Many underground forum advertisements mirrored language comparable to traditional marketing of legitimate AI models, citing the need to improve the efficiency of workflows and effort while simultaneously offering guidance for prospective customers interested in their offerings.
Advertised Capability
Threat Actor Application
Deepfake/Image Generation
Create lure content for phishing operations or bypass know your customer (KYC) security requirements
Malware Generation
Create malware for specific use cases or improve upon pre-existing malware
Phishing Kits and Phishing Support
Create engaging lure content or distribute phishing emails to a wider audience
Research and Reconnaissance
Quickly research and summarize cybersecurity concepts or general topics
Technical Support and Code Generation
Expand a skill set or generate code, optimizing workflow and efficiency
Vulnerability Exploitation
Provide publicly available research or searching for pre-existing vulnerabilities
Table 2: Advertised capabilities on English- and Russian-language underground forums related to AI tools and services
In 2025 the cyber crime marketplace for AI-enabled tooling matured, and GTIG identified multiple offerings for multifunctional tools designed to support stages of the attack lifecycle. Of note, almost every notable tool advertised in underground forums mentioned their ability to support phishing campaigns.
Underground advertisements indicate many AI tools and services promoted similar technical capabilities to support threat operations as those of conventional tools. Pricing models for illicit AI services also reflect those of conventional tools, with many developers injecting advertisements into the free version of their services and offering subscription pricing tiers to add on more technical features such as image generation, API access, and Discord access for higher prices.
Figure 5: Capabilities of notable AI tools and services advertised in English- and Russian-language underground forums
GTIG assesses that financially motivated threat actors and others operating in the underground community will continue to augment their operations with AI tools. Given the increasing accessibility of these applications, and the growing AI discourse in these forums, threat activity leveraging AI will increasingly become commonplace amongst threat actors.
Continued Augmentation of the Full Attack Lifecycle
State-sponsored actors from North Korea, Iran, and the People’s Republic of China (PRC) continue to misuse generative AI tools including Gemini to enhance all stages of their operations, from reconnaissance and phishing lure creation to C2 development and data exfiltration. This extends one of our core findings from our January 2025 analysis Adversarial Misuse of Generative AI.
Expanding Knowledge of Less Conventional Attack Surfaces
GTIG observed a suspected China-nexus actor leveraging Gemini for multiple stages of an intrusion campaign, conducting initial reconnaissance on targets of interest, researching phishing techniques to deliver payloads, soliciting assistance from Gemini related to lateral movement, seeking technical support for C2 efforts once inside a victim’s system, and leveraging help for data exfiltration.
In addition to supporting intrusion activity on Windows systems, the actor misused Gemini to support multiple stages of an intrusion campaign on attack surfaces they were unfamiliar with including cloud infrastructure, vSphere, and Kubernetes.
The threat actor demonstrated access to AWS tokens for EC2 (Elastic Compute Cloud) instances and used Gemini to research how to use the temporary session tokens, presumably to facilitate deeper access or data theft from a victim environment. In another case, the actor leaned on Gemini to assist in identifying Kubernetes systems and to generate commands for enumerating containers and pods. We also observed research into getting host permissions on MacOS, indicating a threat actor focus on phishing techniques for that system.
Mitigations
These activities are similar to our findings from January that detailed how bad actors are leveraging Gemini for productivity vs. novel capabilities. We took action against this actor by disabling the assets associated with this actor’s activity and Google DeepMind used these insights to further strengthen our protections against such misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Figure 6: A suspected China-nexus threat actor’s misuse of Gemini across the attack lifecycle
North Korean Threat Actors Misuse Gemini Across the Attack Lifecycle
Threat actors associated with the Democratic People’s Republic of Korea (DPRK) continue to misuse generative AI tools to support operations across the stages of the attack lifecycle, aligned with their efforts to target cryptocurrency and provide financial support to the regime.
Specialized Social Engineering
In recent operations, UNC1069 (aka MASAN) used Gemini to research cryptocurrency concepts, and perform research and reconnaissance related to the location of users’ cryptocurrency wallet application data. This North Korean threat actor is known to conduct cryptocurrency theft campaigns leveraging social engineering, notably using language related to computer maintenance and credential harvesting.
The threat actor also generated lure material and other messaging related to cryptocurrency, likely to support social engineering efforts for malicious activity. This included generating Spanish-language work-related excuses and requests to reschedule meetings, demonstrating how threat actors can overcome the barriers of language fluency to expand the scope of their targeting and success of their campaigns.
To support later stages of the campaign, UNC1069 attempted to misuse Gemini to develop code to steal cryptocurrency, as well as to craft fraudulent instructions impersonating a software update to extract user credentials. We have disabled this account.
Mitigations
These activities are similar to our findings from January that detailed how bad actors are leveraging Gemini for productivity vs. novel capabilities. We took action against this actor by disabling the assets associated with this actor’s activity and Google DeepMind used these insights to further strengthen our protections against such misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Using Deepfakes
Beyond UNC1069’s misuse of Gemini, GTIG recently observed the group leverage deepfake images and video lures impersonating individuals in the cryptocurrency industry as part of social engineering campaigns to distribute its BIGMACHO backdoor to victim systems. The campaign prompted targets to download and install a malicious “Zoom SDK” link.
Figure 7: North Korean threat actor’s misuse of Gemini to support their operations
Attempting to Develop Novel Capabilities with AI
UNC4899 (aka PUKCHONG), a North Korean threat actor notable for their use of supply chain compromise, used Gemini for a variety of purposes including developing code, researching exploits, and improving their tooling. The research into vulnerabilities and exploit development likely indicates the group is developing capabilities to target edge devices and modern browsers. We have disabled the threat actor’s accounts.
Figure 8: UNC4899 (aka PUKCHONG) misuse of Gemini across the attack lifecycle
Capture-the-Data: Attempts to Develop a “Data Processing Agent”
The use of Gemini by APT42, an Iranian government-backed attacker, reflects the group’s focus on crafting successful phishing campaigns. In recent activity, APT42 used the text generation and editing capabilities of Gemini to craft material for phishing campaigns, often impersonating individuals from reputable organizations such as prominent think tanks and using lures related to security technology, event invitations, or geopolitical discussions. APT42 also used Gemini as a translation tool for articles and messages with specialized vocabulary, for generalized research, and for continued research into Israeli defense.
APT42 also attempted to build a “Data Processing Agent”, misusing Gemini to develop and test the tool. The agent converts natural language requests into SQL queries to derive insights from sensitive personal data. The threat actor provided Gemini with schemas for several distinct data types in order to perform complex queries such as linking a phone number to an owner, tracking an individual’s travel patterns, or generating lists of people based on shared attributes. We have disabled the threat actors’ accounts.
Mitigations
These activities are similar to our findings from January that detailed how bad actors are leveraging Gemini for productivity vs. novel capabilities. We took action against this actor by disabling the assets associated with this actor’s activity and Google DeepMind used these insights to further strengthen our protections against such misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Figure 9: APT42’s misuse of Gemini to support operations
Code Development: C2 Development and Support for Obfuscation
Threat actors continue to adapt generative AI tools to augment their ongoing activities, attempting to enhance their tactics, techniques, and procedures (TTPs) to move faster and at higher volume. For skilled actors, generative AI tools provide a helpful framework, similar to the use of Metasploit or Cobalt Strike in cyber threat activity. These tools also afford lower-level threat actors the opportunity to develop sophisticated tooling, quickly integrate existing techniques, and improve the efficacy of their campaigns regardless of technical acumen or language proficiency.
Throughout August 2025, GTIG observed threat activity associated with PRC-backed APT41, utilizing Gemini for assistance with code development. The group has demonstrated a history of targeting a range of operating systems across mobile and desktop devices as well as employing social engineering compromises for their operations. Specifically, the group leverages open forums to both lure victims to exploit-hosting infrastructure and to prompt installation of malicious mobile applications.
In order to support their campaigns, the actor was seeking out technical support for C++ and Golang code for multiple tools including a C2 framework called OSSTUN by the actor. The group was also observed prompting Gemini for help with code obfuscation, with prompts related to two publicly available obfuscation libraries.
Figure 10: APT41 misuse of Gemini to support operations
Information Operations and Gemini
GTIG continues to observe IO actors utilize Gemini for research, content creation, and translation, which aligns with their previous use of Gemini to support their malicious activity. We have identified Gemini activity that indicates threat actors are soliciting the tool to help create articles or aid them in building tooling to automate portions of their workflow. However, we have not identified these generated articles in the wild, nor identified evidence confirming the successful automation of their workflows leveraging this newly built tooling. None of these attempts have created breakthrough capabilities for IO campaigns.
Mitigations
For observed IO campaigns, we did not see evidence of successful automation or any breakthrough capabilities. These activities are similar to our findings from January that detailed how bad actors are leveraging Gemini for productivity vs. novel capabilities. We took action against this actor by disabling the assets associated with this actor’s activity and Google DeepMind used these insights to further strengthen our protections against such misuse. Observations have been used to strengthen both classifiers and the model itself, enabling it to refuse to assist with these types of attacks moving forward.
Building AI Safely and Responsibly
We believe our approach to AI must be both bold and responsible. That means developing AI in a way that maximizes the positive benefits to society while addressing the challenges. Guided by our AI Principles, Google designs AI systems with robust security measures and strong safety guardrails, and we continuously test the security and safety of our models to improve them.
Our policy guidelines and prohibited use policies prioritize safety and responsible use of Google’s generative AI tools. Google’s policy development process includes identifying emerging trends, thinking end-to-end, and designing for safety. We continuously enhance safeguards in our products to offer scaled protections to users across the globe.
At Google, we leverage threat intelligence to disrupt adversary operations. We investigate abuse of our products, services, users, and platforms, including malicious cyber activities by government-backed threat actors, and work with law enforcement when appropriate. Moreover, our learnings from countering malicious activities are fed back into our product development to improve safety and security for our AI models. These changes, which can be made to both our classifiers and at the model level, are essential to maintaining agility in our defenses and preventing further misuse.
Google DeepMind also develops threat models for generative AI to identify potential vulnerabilities, and creates new evaluation and training techniques to address misuse. In conjunction with this research, Google DeepMind has shared how they’re actively deploying defenses in AI systems, along with measurement and monitoring tools, including a robust evaluation framework that can automatically red team an AI vulnerability to indirect prompt injection attacks.
Our AI development and Trust & Safety teams also work closely with our threat intelligence, security, and modelling teams to stem misuse.
The potential of AI, especially generative AI, is immense. As innovation moves forward, the industry needs security standards for building and deploying AI responsibly. That’s why we introduced the Secure AI Framework (SAIF), a conceptual framework to secure AI systems. We’ve shared a comprehensive toolkit for developers with resources and guidance for designing, building, and evaluating AI models responsibly. We’ve also shared best practices for implementing safeguards, evaluating model safety, and red teaming to test and secure AI systems.
Google also continuously invests in AI research, helping to ensure AI is built responsibly, and that we’re leveraging its potential to automatically find risks. Last year, we introduced Big Sleep, an AI agent developed by Google DeepMind and Google Project Zero, that actively searches and finds unknown security vulnerabilities in software. Big Sleep has since found its first real-world security vulnerability and assisted in finding a vulnerability that was imminently going to be used by threat actors, which GTIG was able to cut off beforehand. We’re also experimenting with AI to not only find vulnerabilities, but also patch them. We recently introduced CodeMender, an experimental AI-powered agent utilizing the advanced reasoning capabilities of our Gemini models to automatically fix critical code vulnerabilities.
About the Authors
Google Threat Intelligence Group focuses on identifying, analyzing, mitigating, and eliminating entire classes of cyber threats against Alphabet, our users, and our customers. Our work includes countering threats from government-backed attackers, targeted zero-day exploits, coordinated information operations (IO), and serious cyber crime networks. We apply our intelligence to improve Google’s defenses and protect our users and customers.
If you’ve ever wondered how multiple AI agents can actually work together to solve problems too complex for a single agent, you’re in the right place. This guide, based on our two-part video series, will walk you through the foundational concepts of Multi-Agent Systems (MAS) and show you how Google’s Agent Development Kit (ADK) makes building them easier for developers.
By the end of this post, you’ll understand what multi-agent systems are, how to structure them, and how to enable communication between your agents using ADK.
Let’s dive in.
What Is a Multi-Agent System?
At its core, a multi-agent system is a collection of individual, autonomous agents that collaborate to achieve a goal. To truly grasp this, let’s break it down into three key ideas:
Decentralized Control: There’s no single “boss” agent controlling everything. Each agent makes its own decisions based on its own rules and local information. Think of a flock of birds swirling in the sky, there’s no leader, but together they form incredible, coordinated patterns.
Local Views: Each agent only has a partial view of the system. It perceives and reacts to its immediate environment, not the entire system state. Imagine standing in a crowded stadium; you only see and react to the people directly around you, not the entire crowd simultaneously.
Emergent Behavior: This is where the magic happens. From these simple, local interactions, complex and intelligent global behaviors emerge. Agents working together in this way can solve tasks that no single agent could easily accomplish alone.
This collaborative approach allows for robust, scalable, and flexible solutions to complex problems.
How ADK Supports Multi-Agent Systems
Google’s Agent Development Kit (ADK) was built from the ground up with multi-agent systems in mind. Instead of forcing you to hack different components together, it provides a structured framework with three primary types of agents, each with a specific role:
LLM Agents: These are the “brains” of the operation. They leverage large language models like Gemini to understand natural language input, reason through problems, and decide on the next course of action.
Workflow Agents: These are the “managers” that orchestrate how tasks get done. They don’t perform the work themselves but instead direct the flow of execution among other agents. We’ll explore these in detail later.
Custom Agents: These are the “specialists.” When you need full control or specific logic that doesn’t fit the other agent types, you can write your own Python code by inheriting from BaseAgent.
The Foundational Concept: Agent Hierarchy
When you build with ADK, agents are organized into a hierarchy, much like a company’s organizational chart. This structure is the backbone of your system and is governed by two simple rules:
Parent & Sub-Agents: A parent agent can manage one or more sub-agents, delegating tasks to them.
Single Parent Rule: Each agent can have only one parent, ensuring a clear line of command and data flow.
Think of it like this: the root agent is the CEO, who oversees the entire operation. Its sub-agents might be VPs, who in turn manage directors, managers, and individual contributors. Everyone has a defined role, and together they accomplish the company’s mission. See example here.
This hierarchical structure is fundamental to organizing and scaling your multi-agent system.
Orchestrating Tasks with Workflow Agents
So, we have a hierarchy. But how do we control the flow of work within that structure? This is where Workflow Agents shine. ADK provides three pre-built orchestrators to manage sub-agents:
SequentialAgent: This agent functions like an assembly line. It runs its sub-agents one after another, in a predefined order. The output of one agent can be passed as the input to the next, making it perfect for multi-step pipelines like: fetch data → clean data → analyze data → summarize findings. See example here.
ParallelAgent: This agent acts like a manager assigning tasks to multiple employees at once. It runs all its sub-agents concurrently, which is ideal for independent tasks that can be performed simultaneously, such as calling three different APIs to gather information. See example here.
LoopAgent: This agent works like a while loop in programming. It repeatedly executes its sub-agents until a specific condition is met or a maximum number of iterations is reached. This is useful for tasks like polling an API for a status update or retrying an operation until it succeeds. See example here.
Using these workflow agents, you can build complex and dynamic execution paths without getting lost in boilerplate code.
How Do Agents Communicate?
We have our structure and our managers. The final piece of the puzzle is communication. How do agents actually share information and delegate work? ADK provides three primary communication mechanisms.
Shared Session State
Shared Session State is like a shared digital whiteboard. An agent can write its result to a common state object, and other agents in the hierarchy can read that information to inform their own actions. For example, an LLMAgent can analyze user input and save the key entities to the state, allowing a CustomAgent to then use those entities to query a database.
LLM-Driven Delegation
LLM-Driven Delegation is a more dynamic and intelligent form of communication. A parent agent (often an LLMAgent) can act as a coordinator. It analyzes the incoming request and uses its reasoning capabilities to decide which of its sub-agents is best suited to handle the task. For instance, if a user asks to “generate an invoice for last month,” the coordinator agent can dynamically route the request to a specialized BillingAgent.
Explicit Invocation (AgentTool)
Explicit Invocation (AgentTool) describes a pattern where one agent can directly call another agent as if it were a function. This is achieved by wrapping the target agent as a “tool” that the parent agent can choose to invoke. For example, a primary analysis agent might call a CalculatorAgent tool whenever it encounters a task requiring precise mathematical calculations.
It’s important to understand the distinction between a sub-agent and an AgentTool:
A Sub-Agent is a permanent part of the hierarchy—an employee on the org chart, always managed by its parent.
An AgentTool is like an external consultant. You call on them when you need their specific expertise, but they aren’t part of your core team structure.
Wrapping up
Let’s quickly recap what we’ve covered:
Multi-Agent Systems are powerful because they use decentralized control and local views to produce complex, emergent behaviors.
ADK provides a robust framework with three agent categories: LLM (brains), Workflow (managers), and Custom (specialists).
Agent Hierarchy provides the organizational structure for your system, defining clear parent-child relationships.
Workflow Agents (Sequential, Parallel, Loop) give you the patterns to orchestrate complex task flows.
Communication Mechanisms (Shared State, Delegation, and Explicit Invocation) allow your agents to collaborate effectively.
Together, these concepts make your multi-agent systems not just structured, but truly collaborative, flexible, and intelligent. Now you have the foundational knowledge to start building your own multi-agent applications with ADK. You can start coding the following tutorial here!
Do you find yourself battling surprise cloud bills? Do you spend more time tracking down un-tagged resources and chasing development teams than you do on strategic financial planning? In the fast-paced world of cloud, manual cost management is a losing game. It’s time-consuming, prone to errors, and often, by the time you’ve identified a cost anomaly, it’s too late to prevent the impact.
What if you could codify your financial governance policies and automate their enforcement across your entire Google Cloud organization? Enter Workload Manager (WLM), a powerful tool that lets you automate the validation of your cloud workloads against best practices for security and compliance, including your own custom-defined FinOps rules. Better yet, we recently slashed the cost of using Workload Manager by up to 95% for certain scenarios, letting you run large-scale scans more economically, including a small free tier to help you run small-scale tests. In this blog, we show you how to get started with automated financial governance policies in Workload Manager, so you can stop playing catch-up and start proactively managing your cloud spend.
The challenge with manual FinOps
Managing business-critical workloads in the cloud is complex. Staying on top of cost-control best practices is a significant and time-consuming effort. Manual reviews and audits can take weeks or even months to complete, by which time costs can spiral. This manual approach often leads to “configuration drift,” where systems deviate from your established cost management policies, making it difficult to detect and control spending.
Workload Manager helps you break free from these manual constraints by providing a framework for automated, continuous validation, helping FinOps teams to:
Improve standardization: Decouple team dependencies and drive consistent application of cost-control policies across the organization.
Enable ownership: Empower individual teams to build and manage their own detection rules for specific use cases, fostering a culture of financial accountability.
Simplify auditing: Easily run infrastructure checks across your entire organization and consolidate the findings into a single BigQuery dataset for streamlined reporting and analysis.
By codifying your FinOps policies, you can define them once and run continuous scans to detect violations across your entire cloud environment on a regular schedule.
Workload Manager makes this easy, providing you with out-of-the-box rules across Security, Cost, Reliability etc. Here are some examples of FinOps cost management policies that can be automated with Workload Manager:
Must have required label or tag for a specific google cloud resource (eg: BigQuery dataset)
Enforce lifecycle management or autoclass configuration for every cloud storage bucket
Ensure appropriate data retention is set for storage (eg: BigQuery tables)
Disable simultaneous multi-threading to optimize licensing costs (eg: SQL Server)
Figure – 1: Default Workload Manager policies as per Google Cloud best practices
Don’t find what you need? You can always build your own custom policies using examples in our Git repo.
Let’s take a closer look.
Automating FinOps policies: A step-by-step guide
Here’s how you can use Workload Manager to automate your cost management policies.
Step 1: Define your FinOps rules and create a new evaluation
First, you need to translate your cost management policies into a format that the Workload Manager can understand. The tool uses Open Policy Agent (OPA) Rego for defining custom rules. In this blog we will take a primary use case for FinOps — that is, to ensure resources are properly labeled for cost allocation and showback.
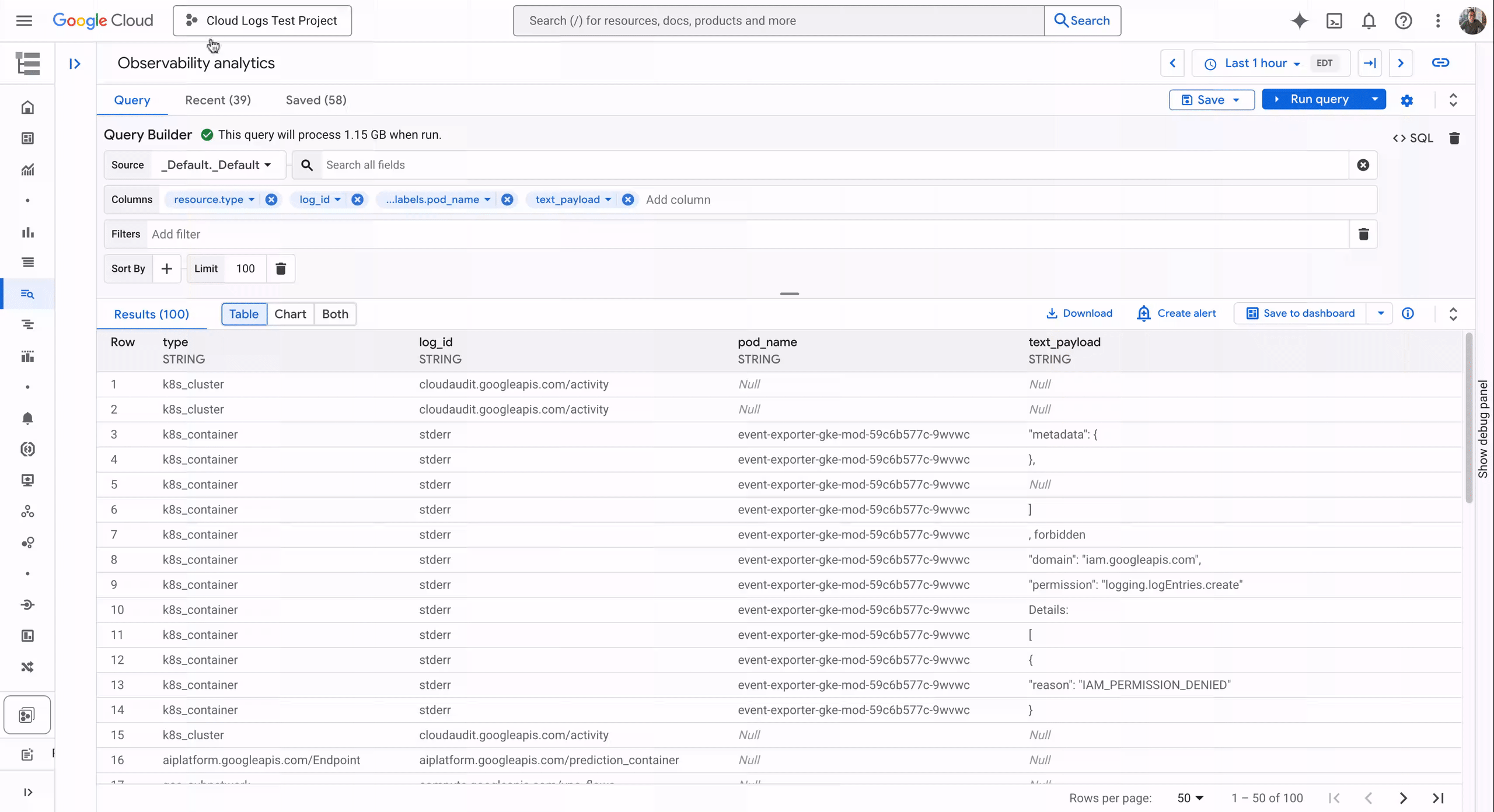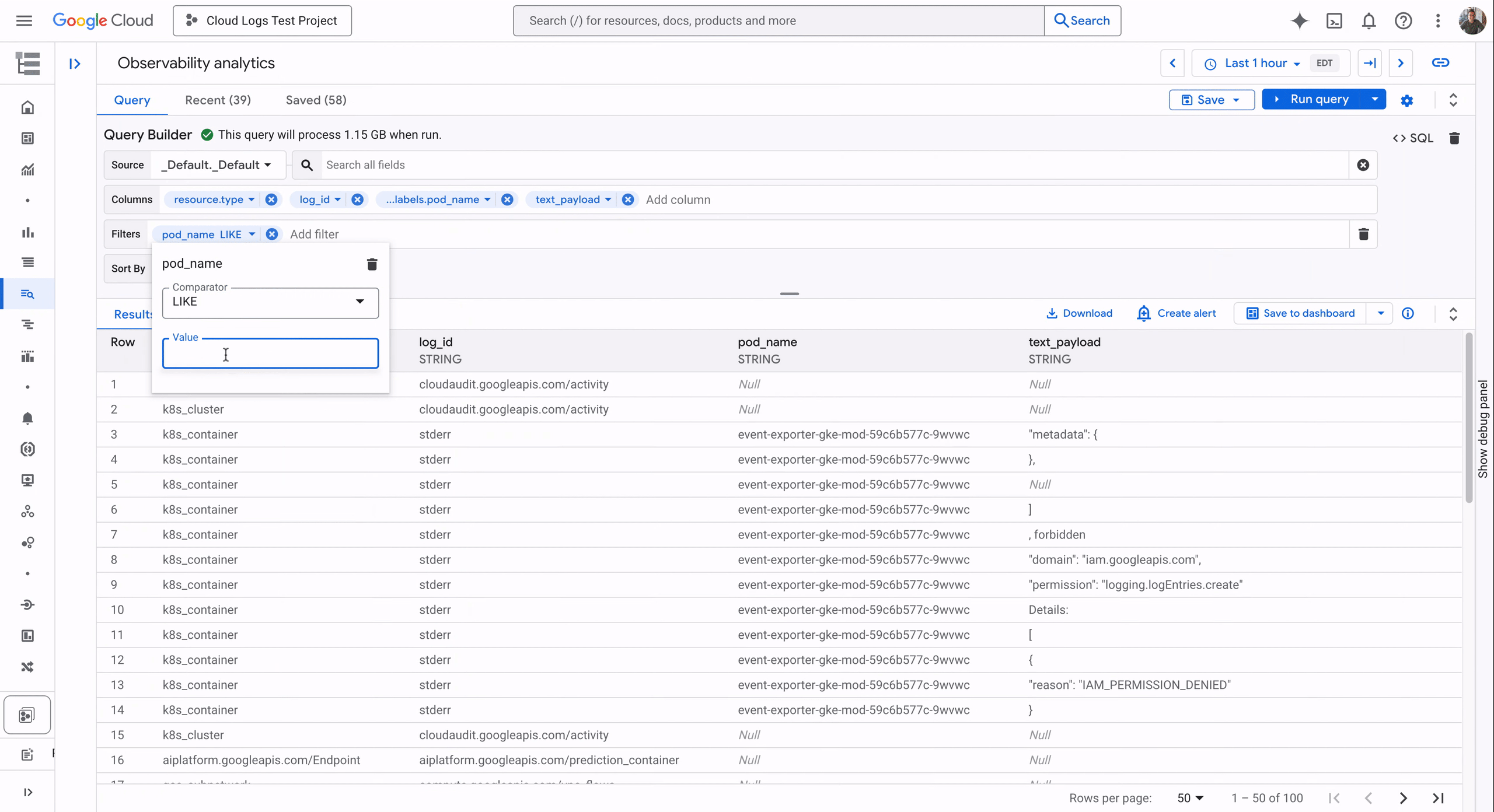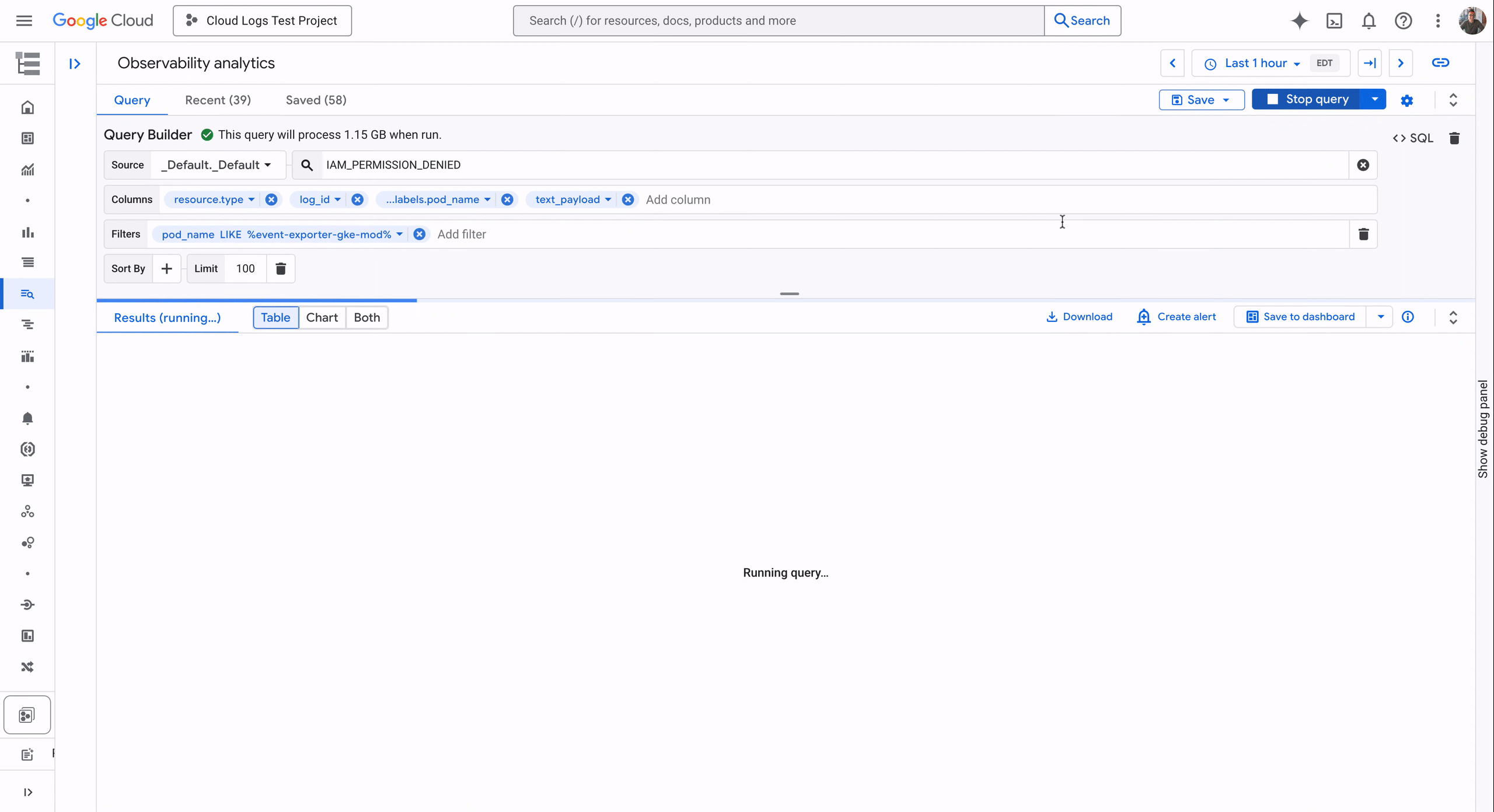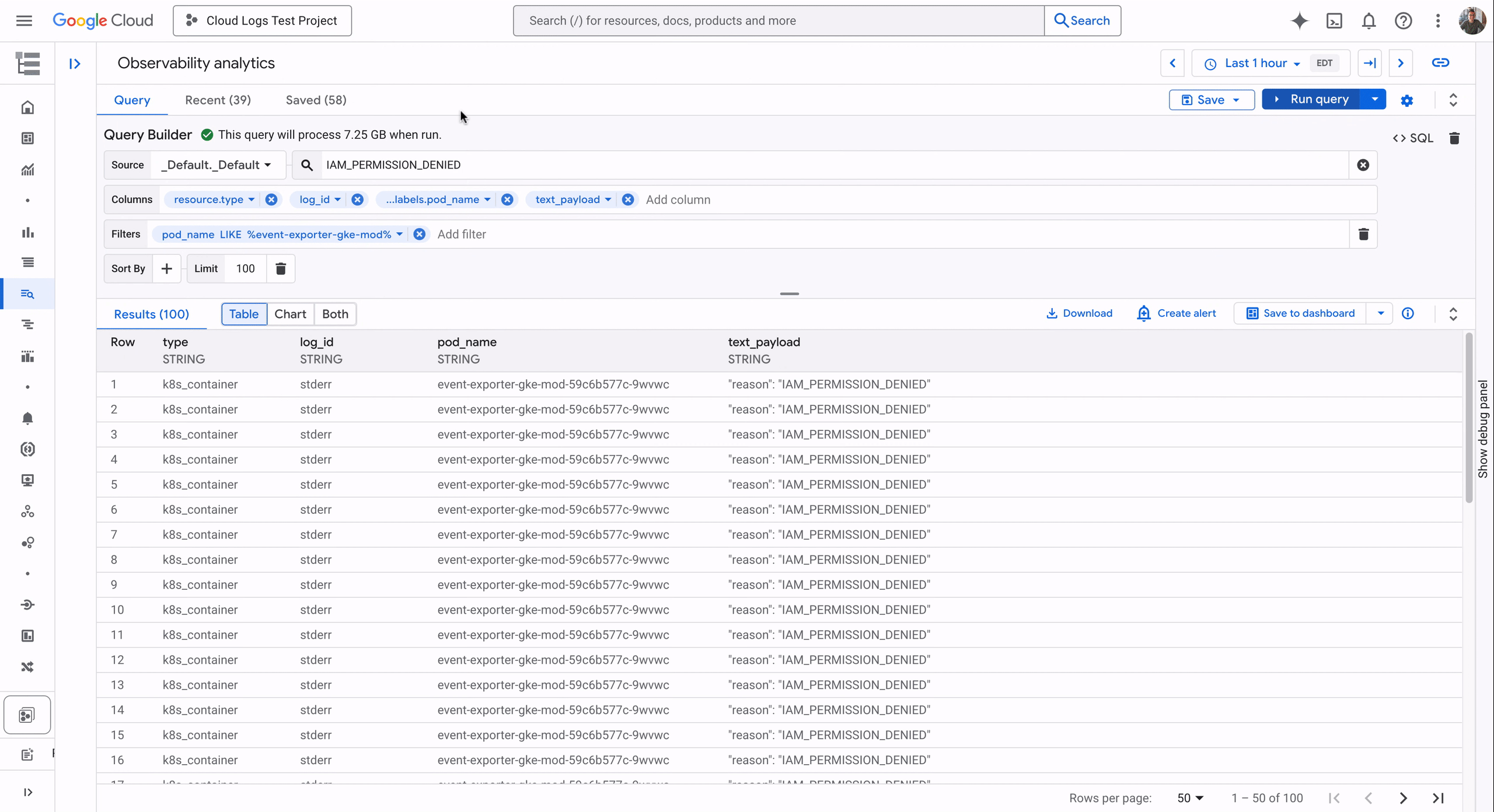
You can choose from hundreds of predefined rules authored by Google Cloud experts that cover FinOps, reliability, security, and operations according to the Google Cloud best practices or create and customize your own rules (checkout examples from the Google Cloud GitHub repository). In our example we will use one of the predefined ‘Google Cloud Best Practices’ rules for bigquery-missing-labels on a dataset. In this case, navigate to the Workload Manager section in your Google Cloud Console and start by creating a new evaluation.
Give your evaluation a name and select “Custom” as the workload type. This is where you can point Workload Manager to the Cloud Storage bucket that contains your custom FinOps rules if you’ve built one. The experience allows you to run both pre-defined and custom rule checks in one evaluation.
Figure 2 – Creating new evaluation rule
Step 2: Define the scope of your scan
Next, define the scope of your evaluation. You have the flexibility to scan your entire Google Cloud organization, specific folders, or individual projects. This allows you to apply broad cost-governance policies organization-wide, or create more targeted rules for specific teams or environments. You can also apply filters based on resource labels or names for more granular control. In this example, region selection lets you select where you want to process your data to meet data residency requirements.
Figure 3 – Selecting scope and location for your evaluation rule
Step 3: Schedule and notify
With FinOps, automation is key. You can schedule your evaluation to run at a specific cadence, from hourly to monthly. This helps ensure continuous monitoring and provides a historical record of your policy compliance. Optionally, but highly recommended for FinOps, you can configure the evaluation to save all results to a BigQuery dataset for historical analysis and reporting.
You can also set up notifications to alert the right teams when an issue is found. Channels include email, Slack, PagerDuty, and more, so that policy violations can be addressed promptly.
Figure 4 – Export, schedule and notify evaluation rules
Step 4: Run, review, and report
Once saved, the evaluation will run on your defined schedule, or you can trigger it on-demand. The results of each scan are stored, providing a historical view of your compliance posture
From the Workload Manager dashboard, you can see a summary of scanned resources, issues found, and trends over time. For deeper analysis, you can explore the violation data directly in the BigQuery dataset you configured earlier.
Figure – 5: Checkout evaluations for workload manager
Visualize findings with Looker Studio
To make the data accessible and actionable for all stakeholders, you can easily connect your BigQuery results to Looker Studio. Create interactive dashboards that visualize your FinOps policy violations, such as assets missing required labels or resources that don’t comply with cost-saving rules. This provides a clear, at-a-glance view of your cost governance status.
You can find Looker Studio template in template gallery and easily connect it with your datasets and modify as needed. Here is how you can use it:
Click on “Use your own Data” that asks for connecting the Bigquery table generated in previous steps.
After you have connected the Bigquery dataset, lick on Edit to create a customizable copy to incorporate any changes or share it with your team.
Figure – 6: Set up preconfigured Looker Studio dashboard for reporting
Take control of your cloud costs today
Stop the endless cycle of manual cloud cost management. With Workload Manager, you can embed your FinOps policies directly into your cloud environment, automate enforcement, and provide teams with the feedback they need to stay on budget.
Ready to get started? Explore the sample policies on GitHub and check out the official documentation to begin automating your FinOps framework today, and take advantage of Workload Manager’s new pricing.
Check out a quick overview video on how Workload Manager Evaluations helps you do a lot more across Security, Reliability and FinOps.
When we talk about artificial intelligence (AI), we often focus on the models, the powerful TPUs and GPUs, and the massive datasets. But behind the scenes, there’s an unsung hero making it all possible: networking. While it’s often abstracted away, networking is the crucial connective tissue that enables your AI workloads to function efficiently, securely, and at scale.
In this post, we explore seven key ways networking interacts with your AI workloads on Google Cloud, from accessing public APIs to enabling next-generation, AI-driven network operations.
#1 – Securely accessing AI APIs
Many of the powerful AI models available today, like Gemini on Vertex AI, are accessed via public APIs. When you make a call to an endpoint like *-aiplatform.googleapis.com, you’re dependent on a reliable network connection. To gain access these endpoints require proper authentication. This ensures that only authorized users and applications can access these powerful models, helping to safeguard your data and your AI investments. You can also access these endpoints privately, which we will see in more detail in point # 5.
#2 – Exposing models for inference
Once you’ve trained or tuned your model, you need to make it available for inference. In addition to managed offerings in Google Cloud, you also have the flexibility to deploy your models on infrastructure you control, using specialized VM families with powerful GPUs. For example, you can deploy your model on Google Kubernetes Engine (GKE) and use the GKE Inference Gateway, Cloud Load Balancing, or a ClusterIP to expose it for private or public inference. These networking components act as the entry point for your applications, allowing them to interact with your model deployments seamlessly and reliably.
#3 – High-speed GPU-to-GPU communication
AI workloads, especially training, involve moving massive amounts of data between GPUs. Traditional networking, which relies on CPU copy operations, can create bottlenecks. This is where protocols like Remote Direct Memory Access (RDMA) come in. RDMA bypasses the CPU, allowing for direct memory-to-memory communication between GPUs.
To support this, the underlying network must be lossless and high-performance. Google has built out a non-blocking rail-aligned network topology in its data center architecture to support RDMA communication and node scaling. Several high-performance GPU VM families support RDMA over Converged Ethernet (RoCEv2), providing the speed and efficiency needed for demanding AI workloads.
#4 – Data ingestion and storage connectivity
Your AI models are only as good as the data they’re trained on. This data needs to be stored, accessed, and retrieved efficiently. Google Cloud offers a variety of storage options, for example Google Cloud Storage, Hyperdisk ML and Managed Lustre. Networking is what connects your compute resources to your data. Whether you’re accessing data directly or over the network, having a high-throughput, low-latency connection to your storage is essential for keeping your AI pipeline running smoothly.
#5 – Private connectivity to AI workloads
Security is paramount, and you often need to ensure that your AI workloads are not exposed to the public internet. Google Cloud provides several ways to achieve private communication to both managed Vertex AI services and your own DIY AI deployments. These include:
Private Service Connect: Allows you to access Google APIs and managed services privately from your VPC. You can use PSC endpoints to connect to your own services or Google services.
#6 – Bridging the gap with hybrid cloud connections
Many enterprises have a hybrid cloud strategy, with sensitive data remaining on-premises. The Cross-Cloud Network allows you to architect your network to provide any-to-any connectivity. With design cases covering distributed applications, Global front end, and Cloud WAN, you can build your architecture securely from on-premises, other clouds or other VPCs to connect to your AI workloads. This hybrid connectivity allows you to leverage the scalability of Google Cloud’s AI services while keeping your data secured.
#7 – The Future: AI-driven network operations
The relationship between AI and networking is becoming a two-way street. With Gemini for Google Cloud, network engineers can now use natural language to design, optimize, and troubleshoot their network architectures. This is the first step towards what we call “agentic networking,” where autonomous AI agents can proactively detect, diagnose, and even mitigate network issues. This transforms network engineering from a reactive discipline to a predictive and proactive one, ensuring your network is always optimized for your AI workloads.
Upgrading a Kubernetes cluster has always been a one-way street: you move forward, and if the control plane has an issue, your only option is to roll forward with a fix. This adds significant risk to routine maintenance, a problem made worse as organizations upgrade more frequently for new AI features while demanding maximum reliability. Today, in partnership with the Kubernetes community, we are introducing a new capability in Kubernetes 1.33 that solves this: Kubernetes control-plane minor-version rollback. For the first time, you have a reliable path to revert a control-plane upgrade, fundamentally changing cluster lifecycle management.This feature is available in open-source Kubernetes, and is integrated and generally available in Google Kubernetes Engine starting in GKE 1.33 soon.
The challenge: Why were rollbacks so hard?
Kubernetes’ control plane components, especially kube-apiserver and etcd, are stateful and highly sensitive to API version changes. When you upgrade, many new APIs and features are introduced in the new binary. Some data might be migrated to new formats and API versions. Downgrading was unsupported because there was no mechanism to safely revert changes, risking data corruption and complete cluster failure.
As a simple example, consider adding a new field to an existing resource. Until now, both the storage and API progressed in a single step, allowing clients to write data to that new field immediately. If a regression was detected, rolling back removed access to that field, but the data written to it would not be garbage-collected. Instead, it would persist silently in etcd. This left the administrator in an impossible situation. Worse, upon a future re-upgrade to that minor version, this stale “garbage” data could suddenly become “alive” again, introducing potentially problematic and indeterministic behavior.
The solution: Emulated versions
The Kubernetes Enhancement Proposal (KEP), KEP-4330: Compatibility Versions, introduces the concept of an “emulated version” for the control plane. Contributed by Googlers, this creates a new two-step upgrade process:
Step 1: Upgrade binaries. You upgrade the control plane binary, but the “emulated version” stays the same as the pre-upgrade version. At this stage, all APIs, features, and storage data formats remain unchanged. This makes it safe to roll back your control plane to the previously stable version if you find a problem.
Validate health and check for regressions. The 1st step creates a safe validation window during which you can verify that it’s safe to proceed — for example, making sure your own components or workloads are running healthy under the new binaries and checking for any performance regressions before committing to the new API versions.
Step 2:Finalize upgrade. After you complete your testing, you “bump” the emulated version to the new version. This enables all the new APIs and features of the latest Kubernetes release and completes the upgrade.
This two-step process gives you granular control, more observability, and a safe window for rollbacks. If an upgrade has an unexpected issue, you no longer need to scramble to roll forward. You now have a reliable way to revert to a known-good state, stabilize your cluster, and plan your next move calmly. This is all backed by comprehensive testing for the two-step upgrade in both open-source Kubernetes and GKE.
Enabling this was a major effort, and we want to thank all the Kubernetes contributors and feature owners whose collective work to test, comply, and adapt their features made this advanced capability a reality.
This feature, coming soon to GKE 1.33, gives you a new tool to de-risk upgrades and dramatically shorten recovery time from unforeseen complications.
A better upgrade experience in OSS Kubernetes
This rollback capability is just one part of our broader, long-term investment in improving the Kubernetes upgrade experience for the entire community. At Google, we’ve been working upstream on several other critical enhancements to make cluster operations smoother, safer, and more automated. Here are just a few examples:
Support for skip-version upgrades:Our work on KEP-4330 also makes it possible to enable “skip-level” upgrades for Kubernetes. This means that instead of having to upgrade sequentially through every minor version (e.g., v1.33 to v1.34 to v1.35), you will be able to upgrade directly from an older version to a newer one, potentially skipping one or more intermediate releases (e.g., v1.33 to v1.35). This aims to reduce the complexity and downtime associated with major upgrades, making the process more efficient and less disruptive for cluster operators.
Coordinated Leader Election (KEP-4355): This effort ensures that different control plane components (like kube-controller-manager and kube-scheduler) can gracefully handle leadership changes during an upgrade, so that the Kubernetes version skew policy is not violated.
Graceful Leader Transition (KEP-5366): Building on the above, this allows a leader to cleanly hand off its position before shutting down for an upgrade, enabling zero-downtime transitions for control plane components.
Mixed Version Proxy (KEP-4020): This feature improves API server reliability in mixed-version clusters (like during an upgrade). It prevents false “NotFound” errors by intelligently routing resource requests to a server that recognizes the resource. It also ensures discovery provides a complete list of all resources from all servers in a mixed-version cluster.
Component Health SLIs for Upgrades (KEP-3466): To upgrade safely, you need to know if the cluster is healthy. This KEP defines standardized Service Level Indicators (SLIs) for core Kubernetes components. This provides a clear, data-driven signal that can be used for automated upgrade canary analysis, stopping a bad rollout before it impacts the entire cluster.
Together, these features represent a major step forward in the maturity of Kubernetes cluster lifecycle management. We are incredibly proud to contribute this work to the open-source community and to bring these powerful capabilities to our GKE customers.
Learn more at KubeCon
Want to learn more about the open-source feature and how it’s changing upgrades? Come say hi to our team at KubeCon! You can find us at booths #200 and #1100 and at a variety of sessions, including:
This is what it looks like when open-source innovation and managed-service excellence come together. This new, safer upgrade feature is coming soon in GKE 1.33. To learn more about managing your clusters, check out the GKE documentation.
Every November, we make it our mission to equip organizations with the knowledge needed to stay ahead of threats we anticipate in the coming year. The Cybersecurity Forecast 2026 report, released today, provides comprehensive insights to help security leaders and teams prepare for those challenges.
This report does not contain “crystal ball” predictions. Instead, our forecasts are built on real-world trends and data we are observing right now. The information contained in the report comes directly from Google Cloud security leaders, and dozens of experts, analysts, researchers, and responders directly on the frontlines.
Artificial Intelligence, Cybercrime, and Nation States
Cybersecurity in the year ahead will be defined by rapid evolution and refinement by adversaries and defenders. Defenders will leverage artificial intelligence and agentic AI to protect against increasingly sophisticated and disruptive cybercrime operations, nation-state actors persisting on networks for long periods of time to conduct espionage and achieve other strategic goals, and adversaries who are also embracing artificial intelligence to scale and speed up attacks.
AI Threats
Adversaries Fully Embrace AI: We anticipate threat actors will move decisively from using AI as an exception to using it as the norm. They will leverage AI to enhance the speed, scope, and effectiveness of operations, streamlining and scaling attacks across the entire lifecycle.
Prompt Injection Risks: A critical and growing threat is prompt injection, an attack that manipulates AI to bypass its security protocols and follow an attacker’s hidden command. Expect a significant rise in targeted attacks on enterprise AI systems.
AI-Enabled Social Engineering: Threat actors will accelerate the use of highly manipulative AI-enabled social engineering. This includes vishing (voice phishing) with AI-driven voice cloning to create hyperrealistic impersonations of executives or IT staff, making attacks harder to detect and defend against.
AI Advantages
AI Agent Paradigm Shift: Widespread adoption of AI agents will create new security challenges, requiring organizations to develop new methodologies and tools to effectively map their new AI ecosystems. A key part of this will be the evolution of identity and access management (IAM) to treat AI agents as distinct digital actors with their own managed identities.
Supercharged Security Analysts: AI adoption will transform security analysts’ roles, shifting them from drowning in alerts to directing AI agents in an “Agentic SOC.” This will allow analysts to focus on strategic validation and high-level analysis, as AI handles data correlation, incident summaries, and threat intelligence drafting.
Cybercrime
Ransomware and Extortion: The combination of ransomware, data theft, and multifaceted extortion will remain the most financially disruptive category of cybercrime. The volume of activity is escalating, with focus on targeting third-party providers and exploiting zero-day vulnerabilities for high-volume data exfiltration.
The On-Chain Cybercrime Economy: As the financial sector increasingly adopts cryptocurrencies, threat actors are expected to migrate core components of their operations onto public blockchains for unprecedented resilience against traditional takedown efforts.
Virtualization Infrastructure Under Threat: As security controls mature in guest operating systems, adversaries are pivoting to the underlying virtualization infrastructure, which is becoming a critical blind spot. A single compromise here can grant control over the entire digital estate and render hundreds of systems inoperable in a matter of hours.
Nation States
Russia: Cyber operations are expected to undergo a strategic shift, prioritizing long-term global strategic goals and the development of advanced cyber capabilities over just tactical support for the conflict in Ukraine.
China: The volume of China-nexus cyber operations is expected to continue surpassing that of other nations. They will prioritize stealthy operations, aggressively targeting edge devices and exploiting zero-day vulnerabilities.
Iran: Driven by regional conflicts and the goal of regime stability, Iranian cyber activity will remain resilient, multifaceted, and semi-deniable, deliberately blurring the lines between espionage, disruption, and hacktivism.
North Korea: They will continue to conduct financial operations to generate revenue for the regime, cyber espionage against perceived adversaries, and seek to expand IT worker operations.
Be Prepared for 2026
Understanding threats is key to staying ahead of them. Read the full Cybersecurity Forecast 2026 report for a more in-depth look at the threats covered in this blog post. We have also released special reports that dive into some of the threats and challenges unique to EMEA and JAPAC organizations.
For an even deeper look at the threat landscape next year, register for our Cybersecurity Forecast 2026 webinar, which will be hosted once again by threat expert Andrew Kopcienski.
Data is the lifeblood of the modern enterprise, but the process of making it useful is often fraught with friction. Data engineers, analysts, and scientists—some of the most skilled and valuable talent in any organization—are spending a disproportionate amount of their time on repetitive, low-impact tasks. What if you could shift your focus from manually building and maintaining pipelines to defining the best practices and rules that automate them?
Today, we’re announcing a fundamental shift to solve this challenge. We’re excited to announce the preview of the Data Engineering Agent in BigQuery, a first-party agent designed to automate the most complex and time-consuming data engineering tasks, powered by Gemini.
The Data Engineering Agent isn’t just an incremental improvement; it’s fundamentally transforming the way we work, with truly autonomous data engineering operations. According to IDC, ‘GenAI and other automation solutions will drive over $1 trillion in productivity gains for companies by 2026’1.
Here is a closer look at the powerful capabilities you can access today:
Pipeline development and maintenance
The Data Engineering Agent makes it easy to build and maintain robust data pipelines. The agent is available in BigQuery pipelines and it can help you with:
Natural language pipeline creation: Describe your pipeline requirements in plain language, and the agent generates the necessary SQL code, adhering to data engineering best practices that you can customize through instruction files. For example: “Create a pipeline to load data from the ‘customer_orders’ bucket, standardize the date formats, remove duplicate entries, and load it into a BigQuery table named ‘clean_orders’.”
Intelligent pipeline modification: Need to update an existing pipeline? Just tell the agent what you want to change. It analyzes the existing code, and proposes the necessary modifications, leaving you to simply review and approve the changes. For example, you can ask it to “Create a pipeline to load data from the ‘customer_orders’ bucket, standardize the date formats, remove duplicate entries, and load it into a BigQuery table named ‘clean_orders’.” The agent follows best-practice design principles and helps you optimize and redesign your existing pipelines to eliminate redundant operations, as well as to leverage BigQuery’s query optimization features such as partitioning.
Dataplex Universal Catalog integration: The agent leverages Google Cloud’s Dataplex data governance offering. It automatically retrieves additional resource metadata such as business glossaries and data profiles from Dataplex to improve the relevance, table-metadata generation (new tables) and performance of the generated pipelines.
Custom agent instructions and logic: Incorporate your unique business logic and engineering best practices by providing custom instructions and leveraging User-Defined Functions (UDFs) within the pipeline.
Automated code documentation: The agent automatically generates clear and concise documentation for your pipelines along with column descriptions, making them easier to understand and maintain for the entire team.
Spanish-language news and entertainment group PRISA Media and early access customer has had a positive experience with the Data Engineering Agent.
“The agent provides solutions that enable us to explore new development approaches, showing strong potential to address complex data engineering tasks. It demonstrates an impressive ability to correctly interpret our requirements, even for sophisticated data modeling tasks like creating SCD Type 2 dimensions. In its current state, it already delivers value in automating maintenance and small optimizations, and we believe it has the foundation to become a truly distinctive tool in the future.” – Fernando Calo, Lead Data Engineer at the Spanish-language news and entertainment group PRISA
Data preparation, transformation and modeling
The first step in any data project is often the most time-consuming: understanding, preparing, and cleaning raw data. The Data Engineering Agent allows you, for example, to access raw files from Google Cloud Storage. It automatically cleans, deduplicates, formats and standardizes your data based on the provided instructions. Integration with Dataplex allows you to generate data quality assertions based on rules defined in the Dataplex repository and automatically encrypt columns that were flagged as containing Personally Identifiable Information (PII). No more writing complex queries to identify data quality issues or to standardize formats.
The agent can then generate the necessary code to perform essential data transformation tasks, significantly reducing the time it takes to get your data ready for analysis. This process covers operations like joining and aggregating datasets.
The agent assists with complex data modeling, too. You can use natural language prompts to generate sophisticated schemas, such as Data Vault or Star Schemas, directly from your source tables.
Pipeline troubleshooting
When issues arise, the Data Engineering Agent can help you quickly identify and resolve them. Instead of manually digging through logs and code, you invoke the agent to diagnose the problem. The Data Engineering Agent is integrated with Gemini Cloud Assist. It analyzes the execution logs, identifies the root cause of the failure, and suggests a solution, helping you get your pipelines back up and running in record time.
Pipeline migrations
For teams looking to modernize their data stack, the Data Engineering Agent can speed up the transition to a unified Google Cloud data platform. That’s what happened at Vodafone as it migrated to BigQuery.
“During the migration journey to a Dataform environment, the Data Engineer Agent successfully replicated all existing data and transformations scripts with 100% automation and zero manual intervention. This achievement resulted in a 90% reduction in the time typically required for manual ETL migration, significantly accelerating the transition.” – Chris Benfield, Head of Engineering, Vodafone
Customers have already migrated onto BigQuery pipelines to:
Standardize and unify code: If you’re looking to consolidate your processing engines, the agent helps you to standardize on BigQuery pipelines. Simply provide the agent with your existing code, and it will generate the equivalent, optimized BigQuery pipeline, reducing operational complexity and cost.
Migrate from legacy tools: The agent can translate proprietary formats and configurations from legacy data processing tools into native BigQuery pipelines.
The road ahead
This is just the beginning for the Data Engineering Agent. We are continuously working to expand its capabilities to address more challenges faced by data engineering teams. In the future, you can expect to see the agent extend its reach to include proactive troubleshooting, IDE integration, and pipeline orchestration in Cloud Composer.
Get started today
The BigQuery Data Engineering Agent is available now. We are excited to see how you integrate this new intelligent partner into your daily work.
Ready to transform your data engineering workflows?
Access the agent: Navigate to BigQuery Pipelines in BigQuery Studio or the Dataform UI. The Data Engineering Agent is accessible via the ‘Ask Agent’ button.
Learn more: Review the official documentation for setup instructions and best practices.
Mercado Libre, the e-commerce and fintech pioneer of Latin America, operates at a staggering scale, demanding an infrastructure that’s not just resilient and scalable, but also a catalyst for rapid innovation. While our use of Spanner for foundational consistency and scale is known, a deeper dive reveals a sophisticated, multi-layered strategy. Spanner is not just a database here; it’s a core engine powering our internal developer platform, diverse data models, advanced analytics loops, intelligent features, and even our roadmap for next-generation AI applications.
This blog explores the technical underpinnings of how Mercado Libre leverages Spanner in concert with our internal innovations like the Fury platform, achieving significant business impact and charting a course for an AI-driven future.
The dual challenge: internet-scale operations and developer velocity
Mercado Libre faces the classic challenges of internet-scale services: keeping millions of daily financial transactions safe, making it easy for developers to build apps, and maintaining near-perfect uptime. The solution required a database powerful enough for the core and an abstraction layer elegant enough for broad developer adoption.
Fury: Mercado Libre’s developer gateway
At the heart of Mercado Libre’s strategy is Fury, our in-house middleware platform. Fury is designed to abstract away the complexities of various backend technologies, providing developers with standardized, simplified interfaces to build applications.
Abstraction & Standardization: Fury allows development teams to focus on business logic rather than the nuances of distributed database management, schema design for specific engines, or optimal connection pooling.
Spanner as the Reliable Core: Spanner is an always-on, globally consistent, multi-model database with virtually unlimited scale.By designating Spanner as a choice within Fury, Mercado Libre ensures that applications built on the platform using Spanner inherit its best features – they stay consistent globally, scale without breaking, and rarely go down.
Fig. 1 – Fury’s core services
Spanner – the versatile backbone
Through Fury, Spanner empowers Mercado Libre’s developers with remarkable versatility. Some apps need complex transactions, others need fast lookups. Spanner handles both, which means teams can use just one system:
Relational prowess for complex transactions: For sophisticated transactional workloads like order management, payments, and inventory systems, Spanner’s relational capabilities (SQL, ACID transactions, joins) remain critical.
High-performance key-value store: Many modern applications require fast point lookups and simple data structures. While Spanner isn’t Mercado Libre’s default backend for typical key-value workloads, there are specific applications running large scale non-relational, KV-style workloads on the Spanner.
Spanner’s foundational architecture — TrueTime for global consistency and automated sharding for effortless scaling — makes it an ideal candidate to reliably serve both these access patterns through the Fury platform.
Handling peak demand
Mercado Libre’s Spanner instances demonstrate significant processing capacity, handling around 214K queries per second (QPS) and 30K transactions per second (TPS). To manage this substantial workload, the Spanner infrastructure dynamically scales to over 400 nodes (by 30%), highlighting the robust and elastic nature of the underlying system in accommodating high-demand scenarios. This level of throughput and scalability is critical for maintaining the performance and reliability of Mercado Libre’s services during its busiest times.
Fig. 2 – Diagram of the solution built with Spanner, which uses current search data to predict and recommend products that a customer is most likely to purchase.
Turning data into action
Mercado Libre builds a dynamic data ecosystem around Spanner, leveraging advanced analytics to feed insights directly back into operational systems.
They achieve real-time analytics by combining Spanner Data Boost with BigQuery Federation. Data Boost isolates analytical queries, preventing them from impacting critical transactional performance. This allows for powerful, large-scale analytics to run directly on fresh Spanner data within BigQuery, integrating seamlessly with other data sources.
Insights from BigQuery, such as customer segmentations or fraud scores, are then actioned via Reverse ETL, feeding directly back into Spanner. This enriches operational data, enabling immediate action by frontline applications like serving personalized content or performing real-time risk assessments.
Furthermore, Spanner Change Streams coupled with Dataflow drive crucial service integrations. By capturing real-time data modifications from Spanner, they establish robust pipelines. These enable loading changes into BigQuery for analytics or streaming them to services like Fury Stream for real-time consumption, ensuring low-latency data propagation and enabling event-driven architectures across their systems.
The impact: cost savings, agility, and future-proofing
The strategic adoption of Spanner, amplified by internal platforms like Fury and sophisticated data workflows, has yielded significant benefits for Mercado Libre:
Significant cost savings & low total cost of ownership: The combination of Spanner’s managed nature (reducing manual sharding, maintenance, and maintenance work), efficient resource utilization, and the abstraction provided by Fury has led to a lower Total Cost of Ownership and substantial cost savings.
Business impact & agility: Developers, freed from infrastructure complexities by Fury and empowered by Spanner’s versatile capabilities, can deliver new features and applications faster. The reliability of Spanner underpins critical business operations, minimizing disruptions.
Low operational overhead: Automated scaling, sharding, and maintenance in Spanner significantly reduce the human effort required to manage large-scale database infrastructure.
Building for AI: Next-generation applications on Spanner
Looking ahead, Mercado Libre is exploring Spanner to support more AI workloads.
Spanner’s characteristics make it an ideal foundation:
Consistent state management: Critical for AI systems that need to maintain and reliably update their state context.
Scalable memory/knowledge store: Ability to store and retrieve vast amounts of data for AI system memory, logs, and contextual information.
Transactional operations: Enabling AI systems to perform reliable actions that interact with other systems.
Integration with analytics & Machine Learning (ML): The existing data loops and ML.PREDICT capabilities can enrich AI systems with real-time insights and intelligence.
Spanner provides the transactional foundation these sophisticated, AI applications will require.
Conclusion: A Unified, Intelligent Data Foundation
Mercado Libre’s adoption of Spanner demonstrates how to use a powerful, globally consistent database not just for its core capabilities, but as a strategic enabler for developer productivity, operational efficiency, advanced analytics, and future AI ambitions. Through their Fury platform, they’ve simplified access to Spanner’s capabilities, allowing it to serve as a flexible foundation for both relational and non-relational needs. The integration with BigQuery via Data Boost demonstrates a comprehensive approach to building an intelligent, data-driven enterprise. As Mercado Libre builds AI applications, Spanner is set to continue its role as the consistent and scalable foundation for their next wave of innovation.
Engineering teams use Ray to scale AI workloads across a wide range of hardware, including both GPUs and Cloud TPUs. While Ray provides the core scaling capabilities, developers have often managed the unique architectural details of each accelerator. For Cloud TPUs, this included its specific networking model and Single Programming Multiple Data (SPMD) programming style.
As part of our partnership with Anyscale, we are working on reducing the engineering effort to get started with TPUs on Google Kubernetes Engine (GKE). Our goal is to make the Ray experience on TPUs as native and low-friction as possible.
Today, we are launching several key improvements that help make that possible.
Ray TPU Library for improved TPU awareness and scaling in Ray Core
TPUs have a unique architecture and a specific programming style called SPMD. Large AI jobs run on a TPU slice, which is a collection of chips connected by high-speed networking called interchip interconnect (ICI).
Previously, you needed to manually configure Ray to be aware of this specific hardware topology. This was a major setup step, and if done incorrectly, jobs could get fragmented resources from different, unconnected slices, causing severe performance bottlenecks.
This new library, ray.util.tpu, abstracts away these hardware details. It uses a feature called SlicePlacementGroup along with the new label_selector API to automatically reserve the entire, co-located TPU slice as one atomic unit. This guarantees the job runs on unified hardware, preventing performance issues from fragmentation. Because Ray couldn’t guarantee this single-slice atomicity before, building reliable true multi-slice training (which intentionally spans multiple unique slices) was impossible. This new API also provides the critical foundation for Ray users to use Multislice technology to scale using multiple TPU slices.
Expanded support for Jax, Ray Train and Ray Serve
Our developments cover both training and inference. For training, Ray Train now offers alpha support for JAX (via JaxTrainer) and PyTorch on TPUs.
The JaxTrainer API simplifies running JAX workloads on multi-host TPUs. It now automatically handles the complex distributed host initialization. As shown in the code example below, you only need to define your hardware needs—like the number of workers, topology, and accelerator type—within a simple ScalingConfig object. The JaxTrainer takes care of the rest.
This is a significant improvement because it solves a critical performance problem: resource fragmentation. Previously, a job requesting a “4×4” topology (which must run on a single co-located hardware unit called a slice) could instead receive fragmented resources—for example, eight chips from one physical slice and eight chips from a different, unconnected slice. This fragmentation was a major bottleneck, as it prevented the workload from using the high-speed ICI interconnect that only exists within a single, unified slice.
Example of how the JaxTrainer simplifies training on multi-host TPU:
code_block
<ListValue: [StructValue([(‘code’, ‘import jaxrnimport jax.numpy as jnprnimport optaxrnimport ray.trainrnrnfrom ray.train.v2.jax import JaxTrainerrnfrom ray.train import ScalingConfigrnrndef train_func():rn”””This function is run on each distributed worker.”””rn…rnrn# Define the hardware configuration for your distributed job.rnscaling_config = ScalingConfig(rnnum_workers=4,rnuse_tpu=True,rntopology=”4×4″,rnaccelerator_type=”TPU-V6E”,rnplacement_strategy=”SPREAD”rn)rnrn# Define and run the JaxTrainer.rntrainer = JaxTrainer(rntrain_loop_per_worker=train_func,rnscaling_config=scaling_config,rn)rnresult = trainer.fit()rnprint(f”Training finished on TPU v6e 4×4 slice”)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f30c26eae50>)])]>
Ray Serve APIs support TPUs and with the improvements we have made to vLLM TPU, you can continue to use Ray on vLLM when moving to TPUs. This allows you to use the same stack you use on GPUs and run it on TPUs with minimal code changes.
Label-based Scheduling API for easy obtainability
The new Label-Based Scheduling API integrates with GKEcustom compute classes. A custom compute class is a simple way to define a named hardware configuration. For example, you can create a class called cost-optimized that tells GKE to try acquiring a Spot instance first, then fall back to a Dynamic Workload Scheduler FlexStart instance, and finally to a reserved instance as a last resort. The new Ray API lets you use classes directly from Python. With a simple label_selector, you can request hardware like “TPU-V6E” or target your cost-optimized class, all without managing separate YAML files.
This same label_selector mechanism also exposes deep hardware control for TPUs. As GKE provisions the TPU pods for a slice, it injects metadata (like worker rank and topology) into each one. KubeRay (which manages Ray on GKE) then reads this GKE-provided metadata and automatically translates it into Ray-specific labels as it creates the nodes. This provides key information like the TPU generation (ray.io/accelerator-type), the physical chip topology (ray.io/tpu-topology), and the worker rank within the slice (ray.io/tpu-worker-id).These node labels let you use a Ray label_selector to pin SPMD workloads to specific, co-located hardware, such as a “4×4” topology or a particular worker rank.
In the example below, a Ray user can request a v6e-32 TPU slice but instruct GKE to use custom compute classes to fallback to v5e-16 if that’s not available. Similarly, the user could start by requesting spot or DWS resources and if not available, fallback to reservation instances.
Developers select compute and nodepools
Platform Admins set up Kubernetes
@ray.remote(num_cpu=1, label_selector={ “ray.io/tpu-pod-type”: “v6e-32”, “gke-flex-start”: “true”, }, fallback_strategy=[ {“label_selector”: { “ray.io/tpu-pod-type”: “v5litepod-16”, “reservation-name”: “v5e-reservation”, } }, ] ) def tpu_task(): # Attempts to run on a node in a v6e 4×8 # TPU slice, falling back to a node in a # v5e 4×4 TPU if v6e is unavailable. …
You can now see key TPU performance metrics, like TensorCore utilization, duty cycle, High-Bandwidth Memory (HBM) usage, and memory bandwidth utilization, directly in the Ray Dashboard. We’ve also added low-level libtpu logs. This makes debugging much faster, as you can immediately check if a failure is caused by the code or by the TPU hardware itself.
Get started today
Together, these updates are a significant step toward making TPUs a seamless part of the Ray ecosystem. They make adapting your existing Ray applications between GPUs and TPUs a much more straightforward process. Here’s how to learn more and get started:
Scientific inquiry has always been a journey of curiosity, meticulous effort, and groundbreaking discoveries. Today, that journey is being redefined, fueled by the incredible capabilities of AI. It’s moving beyond simply processing data to actively participating in every stage of discovery, and Google Cloud is at the forefront of this transformation, building the tools and platforms that make it possible.
The sheer volume of data generated by modern research is immense, often too vast for human analysis alone. This is where AI steps in, not just as a tool, but as a collaborative force. We’re seeing powerful new models and AI agents assist with everything from identifying relevant literature and generating novel hypotheses to designing experiments, running simulations, and making sense of complex results. This collaboration doesn’t replace human intellect; it amplifies it, allowing researchers to explore more avenues, more quickly, and with greater precision.
At Google Cloud, we’re bringing together high-performance computing (HPC) and advanced AI on a single, integrated platform. This means you can seamlessly move from running massive-scale simulations to applying sophisticated machine learning models, all in one environment.
So, how can you leverage these capabilities to get to insights faster? The journey begins at the foundation of scientific inquiry: the hypothesis.
AI-enhanced scientific inquiry
Every great discovery starts with a powerful hypothesis. With millions of research papers published annually, identifying novel opportunities is a monumental task. To overcome this information overload, scientists can now turn to AI as a powerful research partner.
Our Deep Research agent tackles the first step: performing a comprehensive analysis of published literature to produce detailed reports on a given topic that would otherwise take months to compile. Building on that foundation, our Idea Generation agent then deploys an ensemble of AI collaborators to brainstorm, evaluate, propose, debate, and rank novel hypotheses. This powerful combination, available in Gemini Enterprise, transforms the initial phase of scientific inquiry, empowering researchers to augment their expertise and find connections they might otherwise miss.
Go from hypothesis to results, faster
Once a hypothesis is formed, the work of translating it into executable code begins. This is where AI coding assistants, such as Gemini Code Assist, excel. They automate the tedious tasks of writing analysis scripts and simulation models by generating code from natural language and providing real-time suggestions, dramatically speeding up the core development process.
But modern research is more than just a single script; it’s a complete workflow of data, environments, and results managed from the command line. For this, Gemini CLI brings that same conversational power directly to your terminal. It acts as the ultimate workflow accelerator, allowing you to instantly synthesize research and generate hypotheses with simple commands, then seamlessly transition to experimentation by generating sophisticated analysis scripts, and debugging errors on the fly, all without ever breaking your focus. Gemini CLI can further accelerate your path to impact by transforming raw results into publication-ready text, generating the code for figures and tables, and refining your work for submission.
This capability extends to automating the entire research environment. Beyond single commands, Gemini CLI can manage complex, multi-step processes like cloning a scientific application, installing its dependencies, and then building and testing it—all with a simple prompt, maximizing your productivity.
The new era of discovery: Your expertise, AI agents, and Google Cloud
The new era of scientific discovery is here. By embedding AI into every stage of the scientific process – from sparking the initial idea to accelerating the final analysis – Google Cloud provides a single, unified platform for discovery. This new era of AI-enhanced scientific inquiry is built on a robust, intelligent infrastructure that combines the strengths of HPC simulation and AI. This includes purpose-built solutions like our H4D VMs optimized for scientific simulations, alongside the latest A4 and A4X VMs, powered by the latest NVIDIA GPUs, and Google Cloud Managed Lustre, a parallel file system that eliminates storage bottlenecks and allows your HPC and AI workloads to create and analyze massive datasets simultaneously. We provide the power to streamline the entire process so you can focus on scientific creativity – and changing the world!
Join the Google Cloud Advanced Computing Community to connect with other researchers, share best practices, and stay up to date on the latest advancements in AI for scientific and technical computing, or contact sales to get started today.
Last year, we announced the public preview of Cost Anomaly Detection, an AI-powered product designed to eliminate one of the biggest anxieties of using the Cloud: unexpected costs. The goal was to provide a safety net that automatically identifies unusual spikes in spending, helping you catch issues before they become financial problems.
Today, we are excited to announce that Cost Anomaly Detection is now generally available (GA), and it is more proactive, intelligent, and flexible. Best of all, anomaly alerts are now on by default for every customer across all projects, including the new ones, offering complete protection from day one.
What’s new in general availability?
For the GA release, we focused on making the service smarter, more automatic, more proactive, and more customizable to suit your specific needs. Here’s what’s new:
1. Auto-alerts by default
Insights into any deviations in your cloud costs should be the default. Protection from cost overruns should be constant and not require any configuration from your end. That’s why we’ve automatically enabled anomaly alerts for all customers on all their projects. Default alerts will be sent to Billing Administrators; you can, of course, easily visit the billing console to manage and customize your alert preferences at any time. The alerts will take you to the Anomaly dashboard on the billing console, where you can easily see all the details related to the cost spike including the root causes.
Anomaly Dashboard with Root Cause Analysis
Default alert configuration
2. Intelligent, AI-generated thresholds
Will auto-alerts mean more noise and email spam? No. Our improved algorithm now provides automated, AI-generated anomaly thresholds based on your historical spending patterns. This intelligent baseline ensures you are only alerted to spikes that seem significant and unexpected, relative to your spend behavior.
Default threshold configuration
And while the AI-generated thresholds work out of the box, you still have the flexibility to override them with your own custom values, if needed. Customers who have already configured their own custom values but would like to leverage our AI-generated thresholds, can easily do so from the billing console at any time.
3. More flexible filtering with percentage deviation
We heard your feedback that every project has a different sensitivity to cost spikes. A $100 deviation might be critical for a small project but expected noise for a large one. To address this, we’ve introduced an additional threshold for percentage deviation that filters your anomaly dashboard and alerts not only on an absolute dollar value but also on a percentage change. This allows your alerts to stay relevant to your budget and scale.
Custom threshold configuration
Don’t worry — all anomalies are still captured and can be viewed at any time by simply removing the filters from your dashboard.
4.Immediate protection from day one
During the public preview, we offered anomaly detection only on projects that were at least 6 months old due to lack of significant spend history. However, our improved algorithm now solves this “cold start” problem, making it possible to alert on anomalies even for new accounts and projects with no prior spend history. This helps ensure that you are protected on Google Cloud, from the get go.
Get started today
Cost Anomaly Detection is a core part of our FinOps capabilities that provides you with complete and predictable control over your cloud costs. When layered with Cloud Budgets, it creates a robust cost control strategy that works to prevent, detect, and contain runaway spend. And it remains free, offered as part of our comprehensive set of cost management tools.
Ray is an OSS compute engine that is popular among Google Cloud developers to handle complex distributed AI workloads across CPUs, GPUs, and TPUs. Similarly, platform engineers have long trusted Kubernetes, and specifically Google Kubernetes Engine, for powerful and reliable infrastructure orchestration. Earlier this year, we announced a partnership with Anyscale to bring the best of Ray and Kubernetes together, forming a distributed operating system for the most demanding AI workloads. Today, we are excited to share some of the open-source enhancements we have built together across Ray and Kubernetes.
Ray and Kubernetes label-based scheduling
One of the key benefits of Ray is its flexible set of primitives that enable developers to write distributed applications without thinking directly about the underlying hardware. However, there are some use cases that weren’t very well covered by the existing support for virtual resources in Ray.
To improve scheduling flexibility and empower the Ray and Kubernetes schedulers to perform better autoscaling for Ray applications, we are introducing label selectors to Ray. Ray label selectors are heavily inspired by Kubernetes labels and selectors, and intend to offer a familiar experience and smooth integration between the two systems. The Ray Label Selector API is available starting on Ray v2.49 and offers improved scheduling flexibility for distributed tasks and actors.
With the new Label Selector API, Ray now directly helps developers accomplish things like:
Assign labels to nodes in your Ray cluster (e.g. gpu-family=L4, market-type=spot, region=us-west-1).
When launching tasks, actors or placement groups, declare which zones, regions or accelerator types to run on.
Use custom labels to define topologies and advanced scheduling policies.
For scheduling distributed applications on GKE, you can use Ray and Kubernetes label selectors together to gain full control over application and the underlying infrastructure. You can also use this combination with GKE custom compute classes to define fallback behavior when specific GPU types are unavailable. Let’s dive into a specific example.
Below is an example Ray remote task that could run on various GPU types depending on available capacity. Starting in Ray v2.49, you can now define the accelerator type to bind GPUs with fallback behavior in cases where the primary GPU type or market type is not available. In this example, the remote task is targeting spot capacity with L4 GPUs but with a fallback to on-demand:
On GKE, you can couple the same fallback logic using custom compute classes such that the underlying infrastructure for the Ray cluster matches the same fallback behavior:
Refer to the Ray documentation to get started with Ray label selectors.
Advancing accelerator support in Ray and Kubernetes
Earlier this year we demonstrated the ability to use the new Ray Serve LLM APIs to deploy large models such as DeepSeek-R1 on GKE with A3 High and A3 Mega machine instances. Starting on GKE v1.33 and KubeRay v1.4, you can use Dynamic Resource Allocation (DRA) for flexible scheduling and sharing of hardware accelerators, enabling the use of the next-generation of AI accelerators with Ray. Specifically, you can now use DRA to deploy Ray clusters on A4X series machines utilizing the NVIDIA GB200 NVL72 rack-scale architecture. To use DRA with Ray on A4X, create an AI-optimized GKE cluster on A4X and define a ComputeDomain resource representing your NVL72 rack:
Combining DRA with Ray ensures that Ray worker groups are correctly scheduled on the same GB200 NVL72 rack for optimal GPU performance for the most demanding Ray workloads.
We’re also partnering with Anyscale to bring a more native TPU experience to Ray and closer ecosystem integrations with frameworks like JAX. Ray Train introduced a JAXTrainer API starting in Ray v2.49, streamlining model training on TPUs using JAX. For more information on these TPU improvements in Ray, read A More Native Experience for Cloud TPUs with Ray.
Ray-native resource isolation with Kubernetes writable cgroups
Writable cgroups allow the container’s root process to create nested cgroups within the same container without requiring privileged capabilities. This feature is especially critical for Ray, which runs multiple control-plane processes alongside user code inside the same container. Even under the most intensive workloads, Ray can dynamically reserve a portion of the total container resources for system critical tasks, which significantly improves the reliability of your Ray clusters.
Starting on GKE v1.34.X-gke.X, you can enable writable cgroups for Ray clusters by adding the following annotations:
This capability is one such example of how we’re evolving Ray and Kubernetes to improve reliability across the stack without compromising on security.
In the near future, we plan to also introduce support for per-task and per-actor resource limits and requirements, a long requested feature in Ray. Additionally, we are collaborating with the open-source Kubernetes community to upstream this feature..
Ray vertical autoscaling with in-place pod resizing
With the introduction of in-place pod resizing in Kubernetes v1.33, we’re in the early stages of integrating vertical scaling capabilities for Ray when running on Kubernetes. Our early benchmarks show a 30% increase in workload efficiency due to scaling pods vertically before scaling horizontally.
Benchmark based on completing two TPC-H workloads (Query 1 and 5) with Ray, 3 times on a GKE cluster with 3 worker nodes, each with 32 CPUs and 32 GB of memory.
In-place pod resizing enhances workload efficiency in the following ways:
Faster task/actor scale-up: With in-place resizing, Ray workers can scale up their available resources in seconds, an improvement over the minutes it could take to provision new nodes. This capability significantly accelerates the scheduling time for new Ray tasks.
Enhanced bin-packing and resource utilization: In-place pod resizing enables more efficient bin-packing of Ray workers onto Kubernetes nodes. As new Ray workers scale up, they can reserve smaller portions of the available node capacity, freeing up the remaining capacity for other workloads.
Improved reliability and reduced failures: In-place scaling of memory can significantly reduce out-of-memory (OOM) errors. By avoiding the need to restart failed jobs, this capabilityimproves overall workload efficiency and stability.
Ray + Kubernetes = The distributed OS for AI
We are excited to highlight the recent joint innovations from our partnership with Anyscale. The powerful synergy between Ray and Kubernetes positions them as the distributed operating system for modern AI/ML. We believe our continued partnership will accelerate innovation within the open-source Ray and Kubernetes ecosystems, ultimately driving the future of distributed AI/ML.
Together, these updates are a significant step toward Ray working seamlessly on GKE. Here’s how to get started:
Request capacity: Get started quickly with Dynamic Workload Scheduler Flex Start for TPUs and GPUs, which provides access to compute for jobs that run for less than 7 days.
Welcome to the second Cloud CISO Perspectives for October 2025. Today, Jeanette Manfra, senior director, Global Risk and Compliance, shares her thoughts on the role of AI in risk management.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x7f5e28391940>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
AI as a strategic imperative: Modernizing risk management
By Jeanette Manfra, Senior Director, Global Risk and Compliance, Google Cloud
Jeanette Manfra, Senior Director, Global Risk and Compliance, Google Cloud
AI is more than a technological upgrade: It’s a strategic imperative for modernizing risk management, security, and compliance. It can help organizations fundamentally shift from reactive responses to proactive, data-driven strategies.
AI systems that can enable predictive risk analytics and accurately inform decision-making in a timely manner is the holy grail of risk management, although adoption has not been uniform. Great strides have been made in many disciplines, particularly in financial risk modeling. Other areas have struggled to take advantage of advances in analytics, for various reasons.
What I am focused on is the integration of a unified risk posture that is agile as inputs change — and meets the needs of a rapidly-growing company. There are four key areas where AI can help across the risk management lifecycle:
Risk identification: AI algorithms can analyze large volumes of structured and unstructured data from many sources to detect patterns and anomalies indicative of emerging risks. Natural Language Processing (NLP) specifically can help extract insights from text data, and can help identify risks from regulatory changes, customer complaints, and employee feedback. For financial institutions, AI can identify policies and procedures that align with regulations and pinpoint compliance gaps.
Risk assessment: AI models can use predictive analytics to forecast potential risks based on historical data and current trends to enable proactive management. They can run simulations for various risk scenarios to assess impact, which can improve decision-making. Machine learning algorithms can be trained to continuously learn from new data, dynamically adjusting risk assessments and improving accuracy.
Risk mitigation: AI-powered systems are being developed that can implement and enforce automated controls to reduce exposure to identified risks in near real-time. They suggest optimal mitigation strategies based on changing risk profiles and business objectives.
Risk monitoring and reporting: AI-driven systems can provide continuous monitoring, generating alerts for unusual activities or deviations. They can automate data collection and analysis, generate detailed reports, and improve compliance reporting, such as automating Suspicious Activity Reports (SARs) filings.
We can also track the value of AI across key risk-management uses:
In cybersecurity threat detection, AI-driven systems can monitor enterprise environments, network traffic, and user activity, and help enable detection. They can identify anomalies and predict attack vectors, shifting security from reactive to proactive.
In regulatory change management, AI systems can review regulatory documents and updates, then summarize the changes and other important details in plain language.
In quality assurance and quality control, AI is being explored by compliance departments to help with tasks, such as executing secondary reviews with large population samples.
Organizational and operational challenges
Implementing AI requires careful planning and testing to secure buy-in and acceptance from regulators, employees, executives, and other stakeholders. Boards of directors also can play a vital role in helping guide AI adoption. Conversely, a lack of broad organizational commitment and involvement from senior leadership can limit the beneficial impact of AI.
Organizations generally pursue one of two paths for AI adoption. AI tools can be integrated into existing workflows, or organizations can use AI as a starting point to transform workflows from scratch to make AI an integral part of the process. Both often face operational challenges when working with legacy infrastructure not designed for modern, data-intensive systems. Additionally, fragmentation of existing security tools can hamper a unified view of the threat landscape.
Organizations can face fragmented risk oversight from a lack of alignment, so effective AI risk management should be integrated into broader enterprise risk-management strategies. Business and security leaders, and boards of directors, should be prepared to implement cultural changes as required.
There is also a significant shortage of experienced specialists capable of effectively deploying, managing, and operating AI solutions. AI security solutions, for example, require specialized talent, ongoing training, and infrastructure investments.
While AI can automate many tasks, over-reliance on automated systems can diminish the critical role of human judgment and contextual understanding, leading to unfair or harmful outcomes when AI systems fail to account for nuanced or context-specific factors. Human decision-making authority should remain final in AI compliance.
Risk measurement and management with AI can also face an additional level of complexity when organizations rely on third-party suppliers for AI products and services. Differing metrics, lack of transparency, and less control over use cases can all impair the use of AI, so contingency processes for failures in third-party data and AI systems should be strongly considered.
Adopting comprehensive AI risk-management frameworks
Organizations can face fragmented risk oversight from a lack of alignment, so effective AI risk management should be integrated into broader enterprise risk-management strategies. Business and security leaders, and boards of directors, should be prepared to implement cultural changes as required.
Many organizations lack structured AI governance. To implement AI compliance and risk management properly, the legal, data governance, technical development, and cybersecurity teams should be brought together. Organizations need a structured, comprehensive approach.
At Google Cloud, part of our approach is to align AI risk management with the Secure AI Framework (SAIF), the NIST AI Risk Management Framework (AI RMF), and ISO 42001. Beyond NIST, organizations can integrate AI into existing enterprise risk-management frameworks including ISO 31000 and Committee of Sponsoring Organizations (COSO) to enhance their effectiveness by introducing automation, scalability, and near real-time capabilities.
Employing an AI risk assessment methodology for identifying, assessing, and mitigating risks;
Developing and using an automated, scalable, and evidence-based approach for auditing generative AI workloads;
And emphasizing human oversight and collaboration in our risk assessments and governance councils.
Additionally, we use explainability tools to help understand and interpret AI predictions and evaluate potential bias; privacy-preserving technologies such as masking and tokenization and adhering to privacy laws; continuous monitoring and auditing for security vulnerabilities that AI might miss; investing in training programs to bridge the AI knowledge gap; and encouraging “interdisciplinary collaboration” between data scientists, risk analysts, and domain experts is also key.
AI is a transformative force, enabling unprecedented levels of proactive risk management, enhanced security, and streamlined compliance. The path forward requires a holistic, leadership-driven approach, spanning structured frameworks, ethical AI design, interdisciplinary collaboration, and continuous investments in talent and technology. Staying adaptable to evolving technologies and regulations is not just a competitive advantage; it’s an operational necessity.
For more guidance on using AI in risk management, please check out ourCISO Insights hub.
aside_block
<ListValue: [StructValue([(‘title’, ‘Tell us what you think’), (‘body’, <wagtail.rich_text.RichText object at 0x7f5e28391430>), (‘btn_text’, ‘Join the conversation’), (‘href’, ‘https://google.qualtrics.com/jfe/form/SV_2n82k0LeG4upS2q’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
How Google Does It: Building AI agents for cybersecurity and defense: At Google, we’ve moved from talking about AI agents to actively using them for security. Here are four critical lessons that helped shape our approach. Read more.
How Model Armor can help protect your AI apps: You can use Model Armor to protect against prompt injections and jailbreaks. Here’s how. Read more.
Enabling a safe agentic web with reCAPTCHA: At Google Cloud, we believe preventing fraud and abuse in the agentic web should fundamentally result in a simpler customer experience. Here’s how we’re doing it. Read more.
New from Mandiant Academy: Practical training to protect your perimeter: Protecting the Perimeter: Practical Network Enrichment teaches the skills to transform network traffic analysis into a powerful, precise security asset. Read more.
How we’re helping customers prepare for a quantum-safe future: Google has been working on quantum-safe computing for nearly a decade. Here’s our latest on protecting data in transit, digital signatures, and public key infrastructure. Read more.
Google is named a Leader in the 2025 Gartner® Magic Quadrant™ for SIEM: We’re excited to share that Gartner has recognized Google as a Leader in the 2025 Gartner® Magic Quadrant™ for Security Information and Event Management (SIEM). Read more.
Cloud Armor named Strong Performer in Forrester WAVE, new features launched: New capabilities in Cloud Armor offer more comprehensive security policies and granular network configuration controls. Read more.
A practical guide to Google Cloud’s Parameter Manager: Google Cloud Parameter Manager is designed to reduce unnecessarily sharing key cloud configurations, and it works with many types of data formats. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x7f5e283916d0>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
EtherHiding in the open, part 1: DPRK hides nation-state malware on blockchains: Google Threat Intelligence Group (GTIG) and Mandiant have observed the North Korea threat actor UNC5342 using “EtherHiding” to deliver malware and facilitate cryptocurrency theft, the first time we have observed a nation-state actor adopting this method. EtherHiding uses transactions on public blockchains to store and retrieve malicious payloads, and is notable for its resilience against conventional takedown and blocklisting efforts. Read more.
EtherHiding in the open, part 2: How UNC5142 uses it to distribute malware: Since late 2023, UNC5142 has significantly evolved their tactics, techniques, and procedures (TTPs) to enhance operational security and evade detection. The group is characterized by its use of compromised WordPress websites and EtherHiding on the BNB Smart Chain to store its malicious components in smart contracts. Read more.
New malware attributed to Russia state-sponsored COLDRIVER: COLDRIVER, a Russian state-sponsored threat group known for targeting high-profile representatives from non-governmental organizations, policy advisors, and dissidents, swiftly shifted operations after GTIG’s May 2025 public disclosure of its LOSTKEYS malware. Only five days later, the group began deploying new malware families. Read more.
Pro-Russia information operations leverage Russian drone incursions into Polish airspace: GTIG has observed multiple instances of pro-Russia information operations (IO) actors promoting narratives related to the reported incursion of Russian drones into Polish airspace that occurred in September. The IO activity appeared consistent with previously-observed instances of pro-Russia IO targeting Poland — and more broadly the NATO Alliance and the West. Read more.
Vietnamese actors using fake job posting campaigns to deliver malware and steal credentials: GTIG is tracking a cluster of financially-motivated threat actors operating from Vietnam that use fake job postings on legitimate platforms to target individuals in the digital advertising and marketing sectors. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
What really makes your SOC ready for AI: What impact will AI have on security teams: Will it turn them into powered-up superheroes, or is the future more Jekyll-and-Hyde? Monzy Merza, co-founder and CEO, Crogl, discusses AI’s potential destinies with hosts Anton Chuvakin and Tim Peacock. Listen here.
How to stop playing security theater and start practicing security reality: Jibran Ilyas, director, Incident Response, Google Cloud, talks with hosts Anton and Tim about why tabletops for incident response preparedness are effective yet rarely done well. Listen here.
Behind the Binary: Building a robust network at Black Hat: Host Josh Stroschein is joined by Mark Overholser, a technical marketing engineer, Corelight, who also helps run the Black Hat Network Operations Center (NOC). He gives us an insider’s look at the philosophy and challenges behind building a robust network for a security conference. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
Cloud-native development is constantly evolving, and at Google, we’re dedicated to empowering developers and operators with tools that are both powerful and intuitive.
Today, we’re thrilled to dive into how the Gemini CLI and Google Kubernetes Engine (GKE) are coming together with the new open-sourcing of the GKE Gemini CLI extension. This extension brings GKE directly into the Gemini CLI ecosystem, and can also be used as an MCP server with any other MCP client. This gives developers several advantages:
Resources: Seamlessly integrate GKE-specific context directly into your Gemini CLI interactions, enabling less verbose and more natural language prompting.
Prompts: Provide detailed prompts integrated with Gemini CLI slash commands to easily complete common but complex workflows.
Powerful tools: Leverage GKE’s capabilities through intuitive commands, simplifying complex operations. Integration with companion products like Cloud Observability has been enhanced through the addition of specific context and tooling, ensuring seamless compatibility with other GCP products when using GKE.
We’re making regular releases, continuously improving and enhancing the Gemini CLI extension for GKE and GKE MCP server.
We’ve already heard from customers about how well the two work together: “We’re intrigued by the integration of GKE with Gemini CLI. This integration presents an exciting path to solve real-world challenges, and we look forward to working closely with Google to help shape its future.” – Jason O’Connell, Head of Engineering AI and Architecture, Macquarie Bank.
How Gemini CLI has become an essential developer tool
Gemini CLI has quickly become an essential tool for developers leveraging AI directly from their command line. For a deeper dive, learn more in this Gemini CLI blog post. This powerful AI agent, with built-in access to core tools, provides extensive out-of-the-box functionality, streamlining complex tasks and accelerating development workflows. It demonstrates the transformative potential of intelligent tooling for productivity. Gemini CLI quickly became the most starred agentic CLI on GitHub, and we’ve had dozens of releases featuring over a hundred community contributors.
One of the key strengths of Gemini CLI lies in its extensibility. Gemini CLI extensions bundle MCP servers, context files, and custom commands into a simple package that teaches Gemini how to use any tool. This innovative architecture enables seamless integration of countless extensibility, unlocking a universe of possibilities for developers to tailor their AI-driven workflows.
GKE: Powering the next generation of workloads
Google Kubernetes Engine (GKE) continues to be a cornerstone for enterprises seeking to deploy, manage, and scale their containerized applications. Its robust and flexible infrastructure has made it the leading choice for demanding workloads, including the increasingly vital training and inference tasks for AI models. Up until now, GKE leveraged the Gemini foundational model in Gemini CLI without GKE expert resources, prompts, or tools.
It is incredibly easy to get started with the new GKE Gemini CLI extension. You can install into Gemini CLI with a single command:
For those using other MCP clients, you can find installation instructions here.
GKE + Gemini CLI: Unlocking inference CUJs
Together, GKE and Gemini CLI shine when it comes to common inference use cases. They can deploy and manage your AI models on GKE as naturally as a conversation with your command line.
Here is an example of how this powerful combination can transform your workflow:
Scenario: You are an ML engineer and want to deploy an inference model. You aren’t familiar with what model or accelerator to use to satisfy your business requirements. You ask Gemini CLI configured with the GKE MCP server for help to deploy a model with a 1500ms latency requirement. Gemini CLI automates the process of discovering models and accelerators, and generating a deployable Kubernetes manifest based on your business requirements. This dynamic workflow has drastically reduced any friction.
Get started today
Together, GKE and Gemini CLI gives developers a more powerful experience working with AI on Kubernetes. We’re excited to see the innovative solutions you’ll build with these powerful tools. Download Gemini CLI, install the GKE Gemini CLI extension, dive in, experiment, and let us know what you think.
As a DevOps engineer, Site Reliability Engineer, or application developer, how many times have you wrestled with complex queries to get the insights you need? Have you wished that there was an easier way to troubleshoot, identify root causes, and verify fixes, without being a SQL expert? We hear you loud and clear. That’s why we’re thrilled to announce the general availability of the Log Analytics query builder, a powerful new tool designed to democratize access to your observability data in Google Cloud.
The challenge: When writing SQL is a bottleneck
Log Analytics lets you query logs, other telemetry types, and even transactional or business datasets from BigQuery in one place. However, for many users, writing SQL queries can be a significant hurdle. This is especially true when dealing with critical log data, where valuable information is often nested in JSON payloads with varying schemas. The time and effort required to write effective SQL can slow down troubleshooting and hinder the ability to diagnose issues efficiently.
The solution: An intuitive query-building experience
We designed the new query builder to break down these barriers, with an intuitive, UI-based experience that empowers users of all skill levels to get answers from their observability data quickly.
Our goals were simple:
Lower the barrier to entry: Get started with Log Analytics for troubleshooting without a steep learning curve.
Accelerate insights: Generate insights from your data faster, reducing the time and effort needed to create effective queries.
Simplify JSON parsing: Easily extract and analyze valuable data from JSON payloads in your logs.
Reduce the need for SQL: For many queries, you may not need to write a SQL, or use the builder to generate starting SQL and get a jump start to continue editing complex queries.
With the query builder, you can analyze, chart and alert on logs with a few clicks on the UI. Save time and effort by more easily writing a SQL query to help more quickly resolve an incident.
Figure: Query Builder Interface
Key features at a glance
The Log Analytics query builder is packed with features to streamline your workflow:
Search all fields: Simply paste an error message or string to search across all your data and quickly pinpoint the source of an issue.
Log schema preview: Querybuilder not only provides a log schema preview, but also provides inferred JSON key and value previews.
Intelligent value selection: The UI provides intelligent values for fields and filters, derived directly from your dataset, even including the nested fields in JSON.
Easier JSON handling: The query builder automatically discovers and suggests JSON schemas and values, allowing you to easily select and extract data without wrestling with JSON_VALUE, JSON_EXTRACT or CAST.
Powerful filtering and aggregation: Easily apply common SQL operators, aggregations (like counts, mean, percentiles), and group-by clauses through a simple UI.
Work with log scopes: Apply a query to a log scope by selecting the log scope from the view/scope picker.
Real-time SQL preview: If you want to see the underlying SQL, the query builder provides a real-time preview that updates as you build your query in the UI. You can switch to the code editor at any time to fine-tune your query.
Visualization dashboard: Instantly visualize your query results and save them to a dashboard with a single click.
Example: Search for `IAM_PERMISSION_DENIED` in pod name contains `event-exporter-gke-mod`
In this example, we searched for `IAM_PERMISSION _DENIED` message in a Kubernetes pod name containing `event-exporter-gke-mod`, and displayed the log id and text payload from the log entry.
From this example, query builder generates the below SQL:
code_block
<ListValue: [StructValue([(‘code’, “WITHrn scope_query AS (rn SELECTrn *rn FROMrn `test-project.global._Default._Default` )rnSELECTrn resource.type,rn log_id,rn JSON_VALUE( resource.labels.pod_name ) AS pod_name,rn text_payloadrnFROMrn scope_queryrnWHERErn JSON_VALUE( resource.labels.pod_name ) LIKE ‘%event-exporter-gke-mod%’rn AND SEARCH(scope_query,rn ‘IAM_PERMISSIONS_DENIED’)rnLIMITrn 100″), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f5e28338e50>)])]>
Example: Count log entries in groups
In this example, we grouped log entries by severity, resource type, and log ID, and counted the number of log entries in each group, in descending order of time.
Query builder generates the below SQL representing this example:
While building your query with the builder, you can always switch to SQL editor and see the generated SQL representing the query, as shown below:
code_block
<ListValue: [StructValue([(‘code’, “WITHrn scope_query AS (rn SELECTrn *rn FROMrn `test-project.global._Default._Default` )rnSELECTrn JSON_VALUE( json_payload.dest_location.country ) AS country,rn SUM( CAST( JSON_VALUE( json_payload.bytes_sent ) AS INT64 ) ) AS total_bytes_sent,rn SUM( CAST( JSON_VALUE( json_payload.packets_sent ) AS INT64 ) ) AS total_packets_sent,rn AVG( CAST( JSON_VALUE( json_payload.rtt_msec ) AS INT64 ) ) AS avg_rtt_msecrnFROMrn scope_queryrnWHERErn log_id = ‘compute.googleapis.com/vpc_flows’rn AND JSON_VALUE( json_payload.reporter ) = ‘SRC’rn AND JSON_VALUE( json_payload.dest_location.country ) IS NOT NULLrnGROUP BYrn JSON_VALUE( json_payload.dest_location.country )rnORDER BYrn total_bytes_sent DESCrnLIMITrn 100″), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f5e28338d30>)])]>
You can also easily edit the query and advance the query as needed, while the foundations are built for you through the query builder experience.
To find more log analysis examples using the query builder, check out the user guide.
What’s next? The future of querying in Log Analytics
Query builder in Log Analytics is just the beginning. We have an exciting features planned, including:
More log scopes: We will soon support log scope containing views from multiple projects.
Trace in Analytics: We will introduce trace to become accessible and queryable from Log Analytics. Join trace and log data for advanced troubleshooting in the coming month.
Save and reuse Queries: Save your frequently used queries and access your recent query history, so you don’t have to start from scratch every time.
NL2SQL: Leverage the power of Gemini to ask questions in natural language and have the query builder generate the SQL for you.
Get started today!
Ready to say goodbye to your SQL headaches and experience a new level of simplicity and power in Log Analytics? The query builder is available now. Dive in and see how easy it is to get the answers you need from your observability data. We can’t wait to hear what you think!
The demand for AI inference infrastructure is accelerating, with market spend expected to soon surpass investment in training the models themselves. This growth is driven by the demand for richer experiences, particularly through support for larger context windows and the rise of agentic AI. As organizations aim to improve user experience while optimizing costs, efficient management of inference resources is paramount.
According to an experimental study of large model inferencing, external key-value caches — KV Cache or, “attention caches” — on high-performance storage like Google Cloud Managed Lustre, can reduce total cost of ownership (TCO) by up to 35%, allowing organizations to serve the same workload with 43% fewer GPUs by offloading prefill compute to I/O. In this blog, we explore the core challenges of managing long-context AI inference and detail how Google Cloud Managed Lustre provides the high-performance external storage solution required to achieve these significant cost and efficiency benefits.
About KV Cache
During the inference phase, a KV Cacheis a critical optimization technique for the efficient operation of Transformer-based large language models (LLMs).
The key innovation of the Transformer was the complete elimination of sequential processing (recurrence), which was achieved by introducing the self-attention mechanism to allow every element in a sequence to instantaneously and dynamically compare itself to and assess the relevance of every other element (a global, all-at-once evaluation). Within this self-attention mechanism, the model computes Key (K) and Value (V) vectors of all preceding tokens in the sequence. To generate the next token during the inference phase, the model needs the K and V vectors of all the previous tokens.
This is where theKV Cachecomes into play. The KV Cache stores these K and V vectors after the initial context processing (known as the “prefill” stage), thereby avoiding the redundant, costly re-computation of the context sequence when generating subsequent tokens. By eliminating this re-computation, the KV Cache vastly speeds up the overall inference process. While smaller caches can fit in high-bandwidth memory (HBM) or host DRAM — up to a few TBs of memory may be available in a single multi-accelerator server — managing a KV Cache for contexts across multiple concurrent users that exceed the memory capacity often requires external or hierarchical storage solutions.
These large contexts can make the “prefill” computation — the calculation that an AI model performs when processing a large context window — very expensive:
For a large context of 100K or more tokens, the prefill computation may cause the time to first token (TTFT) to increase to tens of seconds.
Prefill computation requires a high number of floating-point operations (FLOPs). KV Cache reuse saves these costs and makes additional resources available on the accelerator.
The growth of agentic AI is likely to make the challenge of managing a long context even greater. Unlike a simple chatbot, agentic AI is built for action. It moves beyond conversation to solve problems proactively, completing tasks on your behalf. To do this, it actively gathers context from a wide range of digital sources. Agentic AI may, for example: check live flight data, pull a customer’s history from a database, research topics on the web, and/or keep organized notes in its own files. Agentic AI thereby builds a rich understanding of its environment, but often increases context lengths and their associated KV Cache size.
The key to managing performance costs at scale is to ensure that the accelerator is utilized as fully as possible. High-performance, scale-out storage provides the required greater throughput per accelerator and therefore translates into lighter resource requirements.
External KV Cache on Google Cloud Managed Lustre
We believe that Google Cloud Managed Lustre should be your primary storage solution for external KV Cache. On GPUs, Lustre is assisted by locally attached SSDs. And on TPUs, where local SSDs are not available, Lustre’s role is even more central.
A recent LMCache blog post by Google’s Danna Wang, “LMCache on Google Kubernetes Engine: Boosting LLM Inference Performance with KV Cache on Tiered Storage,” demonstrates the foundational value of host-level offloading. Our Managed Lustre strategy is the next evolution of this host-offloading concept. While Local SSDs and CPU RAM are effective node-local tiers, they are fixed in size and cannot be shared. Managed Lustre provides a parallel file system to act as the massive, high-throughput external storage, making it a great solution for large-scale, multi-node, and multi-tenant AI inference workloads where the cache exceeds the capacity of the host machine.
Here’s an example of how the performance gains of Managed Lustre can reduce your TCO:
In an experiment with a 50K token context and a high cache hit rate (about 75%), usingManaged Lustre improved total inference throughput by 75% and reduced mean time to first token by 44% compared to using KV Cache in host memory alone (further detail below).
TCO analysis yielded a 35% savings from using an external attention/KV Cache for a workload processing 1 million Tokens per Second (TPS) and leveraging A3-Ultra VMs and Managed Lustre, when compared to a workload leveraging no external storage.
Our experiment demonstrated that with configuration tuning and an improvement in KV Cache software to adopt more I/O parallelism, Managed Lustre can substantially improve inference performance.
Total Cost of Ownership: Analysis
When evaluating a KV Cache solution, it’s critical to consider the TCO, which includes not just compute and storage costs but also operational expenses and potential savings. Our analysis shows that a high performance storage-backed KV Cache, like one built on Managed Lustre, provides a compelling TCO advantage compared to purely memory-based solutions.
Cost savings
After taking incremental storage costs into account, we project that the TCO for a file-system-backed KV Cache solution, processing 1m TPS, is 35% lower compared to a memory-only solution. This makes it a more scalable and economically viable option for large-scale AI inference deployments.
The primary TCO benefit comes from a more efficient utilization of expensive compute resources. By offloading KV Cache to a high-performance storage solution, you can achieve a higher inference throughput per accelerator. This means that fewer accelerators are needed for the same workload: You can handle a specific number of queries per second with 43% fewer accelerators, resulting in direct cost savings.
TCO model assumptions
The TCO calculation includes several key components:
Storage costs (list price): These are the costs of Managed Lustre. Testing used the 1000 MB/s per TiB Performance Tier. The TCO model includes sufficient Lustre capacity (73 A3-Ultra machines, with 18 TiB Lustre capacity per machine) to hit the 1m TPS target rate.
Compute costs (list price): A3-Ultra VMs each with 8x H200s GPUs and 8x 141 GB HBM (spot prices will be lower).
Performance benchmarks
Our experiments demonstrated Google Cloud Managed Lustre’s ability to deliver the high-performance I/O necessary with a state-of-the-art LLM. These experiments serve Deepseek-R1 on a Google Cloud A3-Ultra machine (8x H200s; 8x 141GB HBMs). The experiments ran a synthetic serving workload with a 50K token context and a high cache-hit rate (about 75% hit rate) with a total KV Cache size of about 3.4TiB. The memory-only baseline uses 1 TiB host memory for KV Cache. We experimented with two variants of Managed Lustre at high and low I/O parallelism. For high I/O parallelism, we utilized 32 I/O worker threads to read KV Cache data from Lustre in parallel.
Lustre improved total inference throughput by 75% and reduced the mean time to first token by 44% compared to using KV Cache in host memory alone.
Ready to optimize your inference workloads?
To get started with an external KV Cache solution that solves the capacity limits of long context windows and delivers significant performance gains on your large-scale LLMs, follow these steps:
1. Provision your infrastructure; create a Managed Lustre instance:
Provision your Lustre file system in the same region and zone as your target accelerators (GPUs or TPUs) for optimal low-latency access.
Deploy your inference engine: Deploy your LLM using a high-performance inference server like vLLM or a similar framework that supports an external KV Cache or paged-attention architecture.
2. Configure for performance
Once you’ve mounted Managed Lustre, you must configure your inference engine software to leverage the high-performance storage:
Implement direct I/O: Configure your application to access Managed Lustre using the o_direct flag. This bypasses the general-purpose file system cache, allowing the inference engine to manage the critical host memory more effectively.
Tune I/O parallelism: Depending on your inference KV Cache software, its out-of-the-box storage I/O parallelism may not be ideal. You may need to tune the KV Cache software to read KV chunk files with enhanced parallelism to maximize performance.
Remember when online shopping meant typing specific keywords into a rigid search bar and endlessly scrolling through irrelevant results? Traditional e-commerce search, while common, helps only about 1 in 10 consumers find exactly what they’re looking for.
For designers and developers, this opens up possibilities to deliver on what users expect in the AI era. But what exactly are they looking for, and how can you design an experience that both delights, and helps get them what they need?Conversational AI is a significant leap in online search and shopping, moving towards more natural, personalized, and efficient interactions. By focusing on design principles that prioritize multimodal input, intelligent query handling, rich visual presentation, transparency, and accessibility, retailers can build AI experiences that meet user expectations and transform the online shopping journey.
Here are seven ways building conversational AI agents can improve the online shopping experience for shoppers– and how you can start designing them.
1. Smarter search that understands you
Gone are the days of finding the perfect keyword. AI-driven search, or “conversational” search, understands natural language, interpreting full-phrase queries, user intent, and context. This means your users can search more naturally, like asking, “What’s a good jacket for hiking in a rainy climate?” or “Show me red sneakers for under $100”. AI can also intelligently rank and prioritize the most relevant products based on context, user history, and trends.
To help users find what you’re looking for even faster, AI, such as Google Cloud’s Conversational Commerce agent, offers “predictive assistance”, suggesting completions as you type. When a query is ambiguous, the conversational AI agent can proactively ask clarifying questions. This reduces friction and improves product discovery.
2. Personalized recommendations
AI allows for a truly personalized shopping experience. It can suggest products based on users’ past behavior, preferences, and interactions such as conversation history. For travel, imagine a user booking a flight. They might prefer the window seat, and an AI agent notices that an aisle seat has been assigned to their ticket. You can design an experience that notifies the user if a window seat is available, so they have the option to switch. However, it’s important that the AI agent is transparent about why results are personalized, perhaps stating: “Recommended based on previous searches/bookings”, and always clarifying that users have the ability to modify or reset their personalization options.
3. Seamless conversational interaction
Users are increasingly interested in interacting with AI in a conversational way, much like using tools such as Gemini and AI Mode. This allows designers to ask questions in natural language about product availability, differences between items, best store locations, and more. Enhanced conversational capabilities can even help designers adapt to users’ styles and offer tailored prompts.
For example, according to our research, end users have expressed a desire for an “agentic experience” that’s more engaging. Asking clarifying questions when a query is ambiguous is a key part of this interaction.
These tools also support multimodal inputs, allowing users to search using voice, image, or text, or any combination. Voice search is particularly valued for its flexibility and hands-free convenience, especially on mobile devices. As a designer, you could design an experience where the user uploads an image of an item they saw, and ask the agent to see it in a different color – all by using their voice.
4. Addressing frustrations and enhancing comparison
One major pain point in online shopping is the uncertainty of item availability and receiving unsuitable substitutions when items are out of stock. AI can provide real-time stock information and suggest closely related alternatives if an item isn’t available.
Users also strongly desire better tools for “comparing products”, especially details like nutritional information, specifications on tech products, cars, even clothing. They want features like a “compare” button or the ability to see differences side-by-side on a single screen. AI-generated side-by-side comparison tables are highly valued by users as they help in making decisions between products.
5. Clear visuals and user-friendly design
Seeing product pictures and visuals alongside search results is crucial for online shopping. AI interfaces can effectively present results using visual layouts and features like “carousels”, which are particularly useful on mobile to showcase multiple relevant products without cluttering the screen. For designers, we recommend the following:
Rethink placement on mobile: For conversational features on mobile, placing the conversational UI at the top of the page pushes products down. Consider placements like the bottom of the screen, a flyout menu, or a side panel that allows users to browse products while interacting with the AI. Let the user have control over when conversation appears.
Prioritize a “co-browse” experience: A preferred design is an “integrated mode” where the AI assistant appears on the same page as the product results, allowing users to see products update in real-time as they refine their search with the AI. A side panel/fly-out was suggested as an ideal way to achieve this without being as cumbersome as a top-of-page element.
Use clear and intuitive labels: Descriptive labels like “shopping assistant” clarify the feature’s function.
6. Building trust and handling errors gracefully
Trust is a significant factor in user adoption of AI features. Users want clear source attribution for information provided by AI. In a shopping context, this translates to clearly showing product details, prices, and links to retailers.
When the AI can’t fully understand a query or finds no results, it should handle this gracefully. Instead of a simple “no results” message, it can offer intelligent suggestions, alternatives, or prompt the user for clarification, maintaining a productive dialogue.
7. Conversational commerce components library:
We havea downloadable component library on Figma accompanying the UX use cases, that can be used as a guiding kit to utilize designs as outlined in the UX documentation. It contains a collection of reusable UI elements reflecting our tech capabilities that are pre-designed and pre-built, allowing designers and developers to quickly adapt to their particular brand needs and quickly customize and incorporate into their projects.
Components include:
Device sizes
Color (Black/White/Tertiary Colors)
Typography
Component varieties (Buttons, Filters, etc)
Search input
AI prompt
More detailed results
Light/Dark Mode
In addition to speeding up implementation, the component library empowers teams with unmatched customization capabilities. With just a few clicks, designers and developers can easily tailor the experience to reflect their unique brand identity — adjusting everything from typography and color schemes to corner roundness and layout structure. This flexibility ensures that businesses don’t need to compromise between advanced AI functionality and maintaining a consistent, on-brand user interface. The components are built to scale and adapt, offering autonomy while reducing development overhead.
Get started
Designers and developers have the opportunity to meet consumers where they are using conversational AI. To get started with Vertex AI Search: Conversational Commerce Agent: